 Sebastian Mioduszewski
Sebastian Mioduszewski V tomto článku sa pozrieme na získavanie údajov z najdôležitejších nástrojov zo stajne spoločnosti Google pre akékoľvek SEO – Google Analytics (aj v najnovšej verzii, t. j. v4) a Google Search Console. Začneme číslami, ktoré sú pre nás potrebné na dennej báze. Okrem toho budeme využívať hotové a bezplatné nástroje, ktorými sú knižnice: searchConsoleR a googleAnalyticsR.
.
Z tohto článku sa dozviete:
- .
-
Ako nainštalovať potrebné knižnice?
.
-
Ako neinštalovať knižnice, ktoré už máte?
-
Ako sťahovať údaje zo služby Google Analytics (vrátane jej najnovšej verzie – v4)?
-
Ako zbierať údaje z panela nástrojov Google Webmaster Tools?
-
Ako začať používať rozhrania API poskytované spoločnosťou Google?
.
.
.
.
Po prečítaní predchádzajúceho príspevku si už pamätáte (ak nie, pozývam vás k prečítaniu – Programovací jazyk R pre každé SEO. Polohujte, programujte a sledujte výsledky):
-
Čo je R a ako vám pomôže pri vašej práci
.
-
Aké sú knižnice v R (a prečo ich potrebujete)
- .
Hlavné závery
- Inštalácia potrebných knižníc v R, ako sú
"searchConsoleR"a"googleAnalyticsR", je kľúčová pre efektívnu prácu s Google Analytics a Google Search Console. - Autorizácia a získavanie údajov z Google Search Console v jazyku R sú zjednodušené vďaka knižnici
searchConsoleR, ktorá umožňuje prístup k dôležitým SEO metrikám. - Pre pokročilú analýzu a obídenie limitov počtu riadkov pri sťahovaní údajov z Google Search Console je možné využiť možnosť dávkovania v knižnici
searchConsoleR. - API Google Analytics umožňuje komplexnú analýzu údajov, pre ktorú je potrebné vytvoriť účet Google Cloud Platform a získať prístup k pokročilým funkcionalitám pomocou knižnice
googleAnalyticsR. - Integrácia s Senuto Visibility Analysis poskytuje užívateľom R možnosť efektívnejšie sledovať a analyzovať SEO údaje pre zlepšenie online viditeľnosti.
Získavame údaje z konzoly vyhľadávania Google
.
Aby sme mohli používať knižnicu v R, musíme ju nainštalovať (môžete to obísť, ale odporúčam ju nainštalovať) a načítať do pamäte (presne v tomto poradí). Proces inštalácie vo väčšine prípadov trvá do desiatich sekúnd. Aj napriek tomu v nasledujúcom kóde najprv skontrolujeme, či knižnice, ktoré nás zaujímajú, ešte nemáte. Ak áno, prejdeme rovno k druhému kroku, ktorým je načítanie vybranej knižnice do operačnej pamäte počítača.
Krok 1. Nasledujúci kód zapíše názov knižnice, ktorú potrebujeme, ako vektor (sprievodca dátovým typom v jazyku R: https://towardsdatascience.com/data-types-in-r-8124c3b2afe6):
balíky <- c("searchConsoleR"," googleAnalyticsR")
.
kód 1.1
Krok 2. Skontrolujte, či sú v počítači nainštalované potrebné knižnice (ak niektorá z potrebných knižníc nie je nainštalovaná, je nainštalovaná).
inštalujte.balíky(setdiff(packages, rownames(installed.packages())))
Kód 1.2
Krok 3. Autorizácia. Toto je samozrejmé, ale stojí za to pripomenúť, že týmto spôsobom budeme mať prístup len k údajom o lokalite, ktoré sú dostupné v našom účte Search Console.
Urobíme to pomocou jedného jednoduchého príkazu:
scr_auth()
.
Kód 1.3
Kód pre kroky 1, 2 a 3 je k dispozícii zde. .
Ďalšie kroky závisia od toho, či ide o prvé načítanie údajov pomocou tejto knižnice na konkrétnom počítači.
Prvýkrát je to vtedy, keď sa v prehliadači otvorí prihlasovacie okno účtu Google. Nástroj GSC používa overovanie prostredníctvom protokolu oAuth. V dôsledku toho sa zobrazí štandardné prihlasovacie okno Google..
Po úspešnom prihlásení musíte ešte odsúhlasiť povolenie prístupu aplikácie Search Console k vášmu účtu Google.
Takáto požiadavka sa uskutoční len počas prvého prihlásenia na danom zariadení. Počas nej sa vytvorí súbor JSON obsahujúci prihlasovacie údaje. Vďaka tomu prebiehajú ďalšie prihlásenia oveľa rýchlejšie (R už stiahne prihlasovacie údaje uložené v súbore JSON).
Od tohto momentu máme plný prístup k funkciám týkajúcim sa:
- Strong je možné použiť na všetky funkcie, ktoré sa týkajú
- Stránky pridané do panelu (stiahnutie zoznamu všetkých, pridanie stránky do panelu, odstránenie stránky z panelu)
-
Mapy stránok (načítanie zoznamu všetkých, pridanie na panel stránok, odstránenie z panelu stránok)
.
-
Chyby nahlásené v paneli (stiahnutie príkladov chýb nahlásených v paneli, stiahnutie príkladov URL obsahujúcich nahlásené chyby)
-
Viditeľnosť našich stránok v Google (tieto údaje môžeme vidieť v rozmeroch):
-
adresa URL (potrebný parameter)
.
-
dátum začiatku – dátum, od ktorého chcete získať údaje (ak nastavíte dátum, pre ktorý nie sú v paneli žiadne údaje, budú vrátené jednoducho prázdne riadky)
-
koncový dátum – dátum, ku ktorému chcete stiahnuť údaje
-
typ výsledkov vyhľadávania, dostupné hodnoty:
-
prechádzka_data – parameter určujúci, ako chceme získať údaje. Preberá jednu z hodnôt:
-
Použitie rozhrania API (rozhranie GSC má obmedzenie na 1 000 záznamov v správe – vlastne prvých 1 000 záznamov, čo znamená, že napríklad uvidíte len najpopulárnejšie frázy)
- .
-
Použitie možnosti dávkovania v gscR (už opísané vyššie)
-
Dávkovanie údajov – stiahnutie približne 1,5 milióna záznamov trvá približne 30 minút. Pri oveľa väčšom počte môžeme na stiahnutie všetkých údajov potrebovať aj niekoľko dní! Riešením tohto problému je použitie parametra dimensionFilterExp.
- Krajina
- Zariadenie
- Stránka
- Dotaz
- ~~ (znamená obsahuje)
- == (znamená rovná sa)
- !~(význam neobsahuje)
- != (znamená nerovná sa)
-
Všetka prevádzka z vybraných zariadení
.
-
Všetka návštevnosť vybraných podstránok (napr. len domovskej stránky)
-
Všetka návštevnosť z vybranej krajiny (napr. len návštevnosť z Poľska)
- .
-
Všetky prenosy z vybraného typu zariadenia na vybranú podstránku
.
-
Všetka návštevnosť od používateľov z vybranej krajiny pre frázy obsahujúce konkrétny prvok
- strong
- .
.
– dátum – tu získame informáciu o tom, za ktorý deň sme údaje získali
– krajina – údaje o geografickej polohe používateľa, ktorý videl vašu stránku vo výsledkoch vyhľadávania
– typ zariadenia – na akom type zariadenia vo výsledkoch Google došlo k zobrazeniu (k dispozícii sú hodnoty Desktop, Mobile, Tablet)
– stránka – podstránka webovej lokality, ktorá sa zobrazuje vo výsledkoch vyhľadávania
– hľadaná fráza – fráza, po ktorej vyhľadaní bola stránka nájdená v Google
– zaujímavé je, že žiaden z rozmerov nie je potrebný (potom dostaneme celkové údaje).
Funkcia search_analytics, ktorú sa chystáme použiť, preberá parametre ako napr:
- .
.
– „web“ – štandardné výsledky vyhľadávania
– „obrázok“ – grafické výsledky vyhľadávania
– „video“ – výsledky vyhľadávania Google vo videu
– byBatch – táto možnosť funguje oveľa rýchlejšie, ale vráti iba výsledky, na ktoré analyzovaná stránka získala kliknutia (t. j. nie je to dobrý nápad, ak chcete skontrolovať, koľko kliknutí získala stránka v službe Google – všetky kliknutia bez kliknutí budú odstránené)
– byDate – ako už viete, táto metóda je presnejšia, ale vyžaduje si viac času (získanie informácií o 10 miliónoch zobrazení v službe Google mi trvalo približne hodinu). Obmedzenie, ktoré je kladené na rozhranie API, spočíva v tom, že naraz možno načítať maximálne 25 000 riadkov. Našťastie pre tých, ktorí chcú viac údajov, je k dispozícii možnosť zaradiť 25 000 riadkov naraz do frontu a takto získané údaje spojiť.
Ako sa vysporiadať s obmedzeniami GSC?
.
Opísaná knižnica získava údaje pomocou API GSC, takže môžeme obísť štandardné obmedzenie panela GSC, ktoré nám umožňuje získať až 1 000 riadkov v zostave. Možnosť dávkovania nám umožňuje stiahnuť všetky údaje. Ako som popísal, takéto údaje sa sťahujú v dávkach až do 25 000 riadkov.
Pri sťahovaní údajov z GSC musíme počítať s možnosťou straty časti údajov. Je to preto, ako vysvetľuje spoločnosť Google, že systém sa snaží vrátiť výsledky v prijateľnom čase. Z toho vyplýva, že v prípade zle zostavených dotazov (zahŕňajúcich príliš veľa zdrojov spoločnosti Google v jednom čase) môže dôjsť k strate niektorých údajov.
S uvedenými poznatkami môžeme vykonať prvý úplný dotaz na údaje GSC..
Nápoveda: Jednou zo silných stránok programu Rstudio je automatické napovídanie kódu. Ako môžete vidieť nižšie, je to veľmi užitočné pri práci s knižnicou searchconsoler.
Ako stiahnuť naozaj veľké množstvo údajov (viac ako milión riadkov) z Google Search Console?
.
Stiahnutie takéhoto množstva údajov si vyžaduje:
.
Obsah tohto parametra sa skladá z filtra a operátora.

Filter môže nadobúdať jednu z hodnôt:
Dostupné operátory sú:
.
.
.
.
Filtrovanie myšlienok:
Dôležité je, že filtre možno kombinovať. Medzi príklady zložených filtrov patria napr:
Celý skript, pripravený na skopírovanie a spustenie, je k dispozícii t tu..
Vyskúšajte Senuto Suite na 14 dní zadarmo
Vyskúšajte si 14-dňovú bezplatnú verziuAko rýchlo stiahnuť údaje z Google Analytics (aj verzia v4) v R?
.
Krok 1. Rovnako ako v predchádzajúcom skripte zapíšeme názov knižnice, ktorú potrebujeme.
balíky <- c(" googleAnalyticsR")
.
Krok 2. Tak ako som už popísal pri Google Search Console, skontrolujeme, či je potrebná knižnica nainštalovaná v počítači.
Install.packages(setdiff(packages, rownames(installed.packages())))
.
Začneme seriózne pracovať s rozhraním API spoločnosti Google (zaregistrujeme si účet Google Cloud Platform)
.
Ak chceme seriózne pracovať s rozhraniami API poskytovanými spoločnosťou Google, mali by sme si vytvoriť účet.
Krok 3. V tomto kroku si vytvoríme účet v službe Google Cloud Platform. Je to potrebné na to, aby sme mohli naplno využívať možnosti API pre Google Analytics. Naším cieľom bude získať:
- klientské tajomstvo (reťazec dostupný v súbore, ktorý stiahneme z GCP)
- ID klienta (ID používateľa GCP)
.
.
Na tento účel musíme:
-
Vytvoriť si bezplatné konto na webovej lokalite GCP (nebudem to vysvetľovať)
.
-
Zapnite na svojom účte GCP podporu rozhrania Google analytics API.
- .
.
Ak to chcete urobiť, vyberte ponuku API a služby.
 .
.
Prejdite na položku Povolenie rozhraní API a služieb.

Spomedzi dostupných rozhranie API vyberáme nasledujúce.

Ďalej v ponuke vyberte položku Podrobnosti o prihlásení.
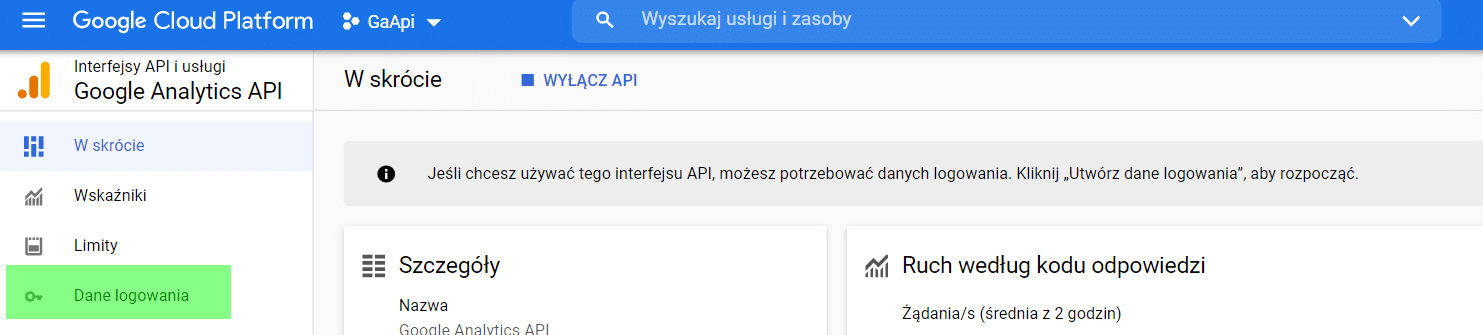 .
.
Pri otázke o type aplikácie vyberieme možnosť „Počítačová aplikácia“.
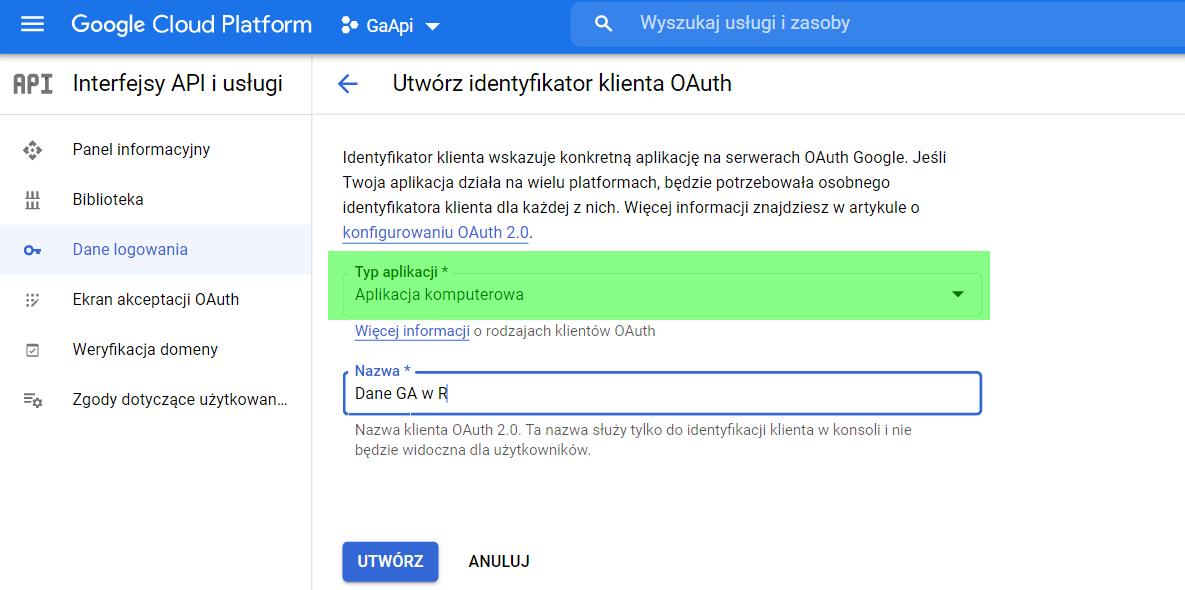
Po vyplnení názvu a typu aplikácie získame ID a tajný kľúč pre náš účet.
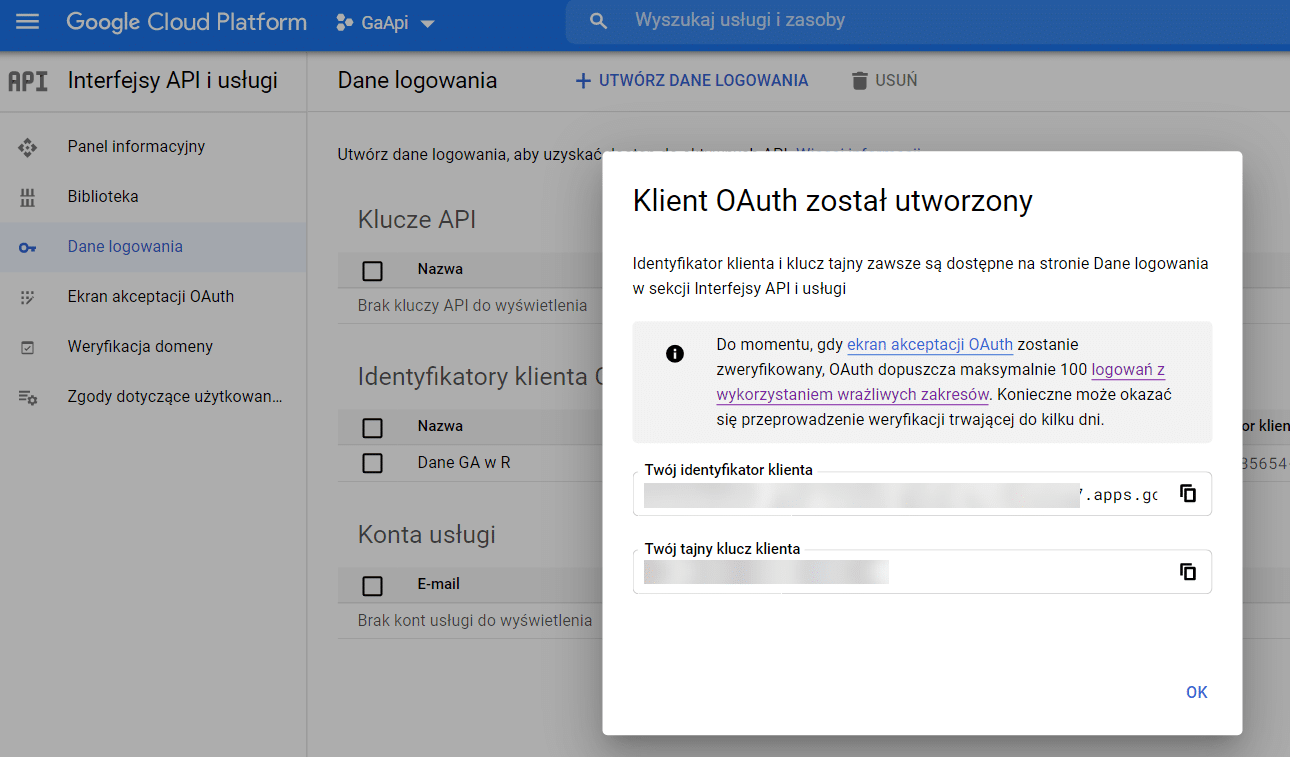
Ďalším krokom je vytvorenie účtu služby. To nám umožní vygenerovať adresu potrebnú na overenie v GA. Tento servisný účet vytvoríme výberom položky Administrácia > Servisné účty v ponuke GCP (ako je uvedené nižšie).
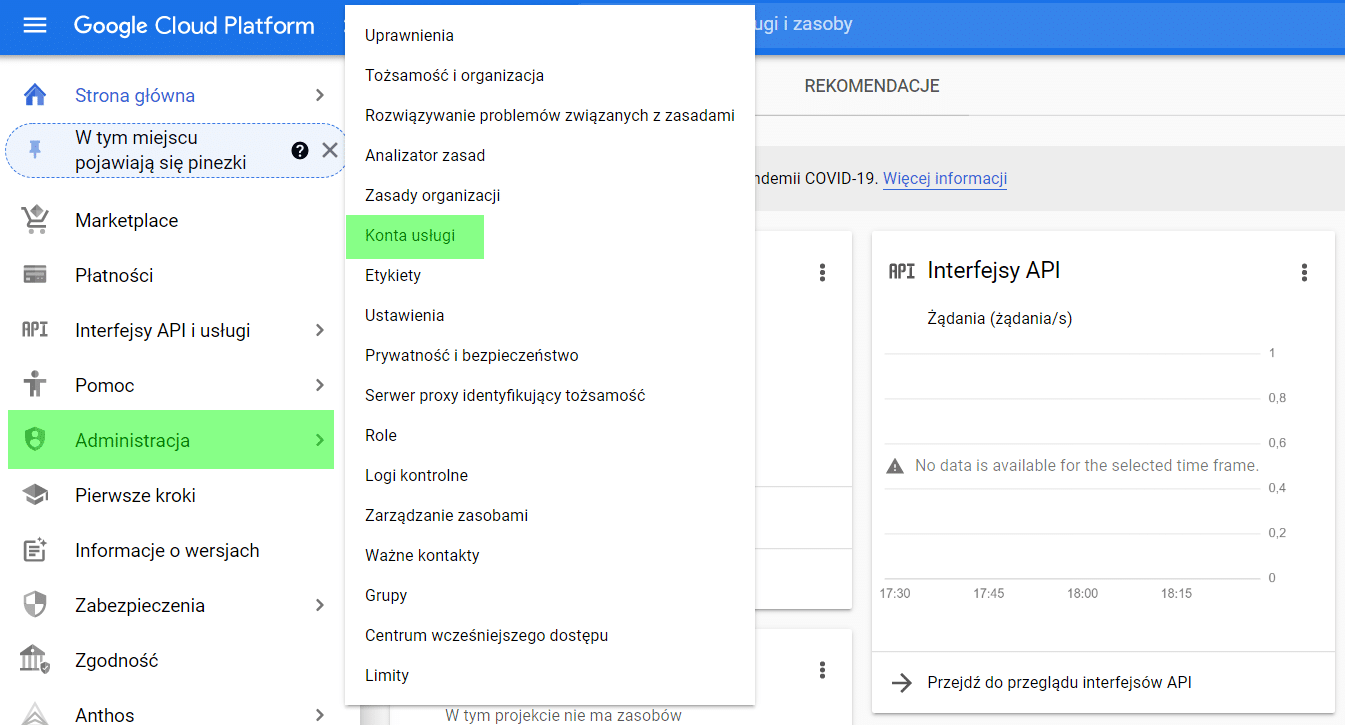
Posledným prípravným krokom je pridanie adresy používateľa účtu GCP (zvýraznené nižšie) na ovládací panel služby Google Analytics.
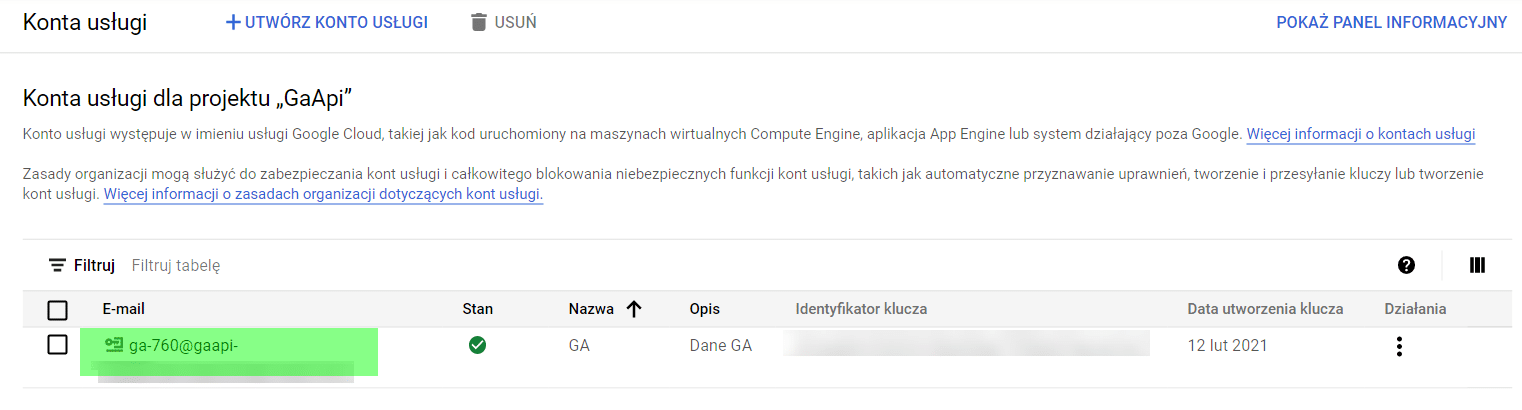
Na overenie budeme potrebovať ID zákazníka a kľúč zákazníka. Uložíme ich ako premenné v programe R.
Čo sú dimenzie a metriky údajov
.
Tým, ktorí majú skúsenosti s prácou s databázami, bude rozdelenie medzi faktami a dimenziami známe. Keďže jeden obrázok vydá za viac ako tisíc slov, pokúsim sa to rozobrať názorne.
Fakty sú udalosti, ktoré sú základom pre analýzu (napr. predaj alebo používatelia služieb).
Dimenzie opisujú fakty. Fakty možno rozdeliť na dimenzie (napr. počet relácií používateľov).
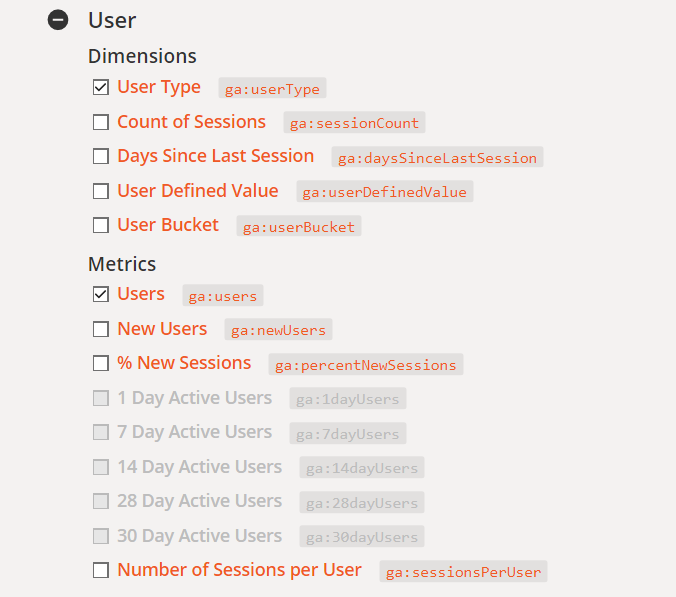
Nasledujúce členenie údajov pre GA (prevzaté z tejto stránky) predstavuje analýzu, kde:
Fakt – používatelia stránky.
Dimenzia – typ používateľa (tu nový alebo vracajúci sa)
Metrika – počet používateľov, dátum vo formáte (RRRR-MM-DD, t. j. napríklad 2021-02-15).
To nám poskytuje údaje, ako sú tieto:
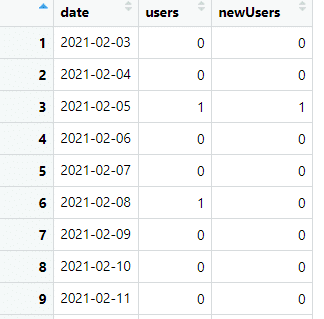
A kód R:

Celý kód je k dispozícii zde.
Omedzenia (výber vzorky a množstvo údajov) v prehľadoch Google Analytics v porovnaní s API
.
Služba Google Analytics má obmedzenia týkajúce sa vzorkovania údajov (viac informácií o vzorkovaní zde).
Pri preberaní údajov to môžeme skontrolovať pomocou parametra anti_sample. Jeho použitie spôsobí, že systém vráti nevybrané údaje, ak je to možné (teda kým sa pohybujeme v rámci limitov). Nasledujúci príklad ukazuje spätnú väzbu v konzole R Studio, ktorá indikuje, že správa bola prevzatá bez vzorkovania údajov.
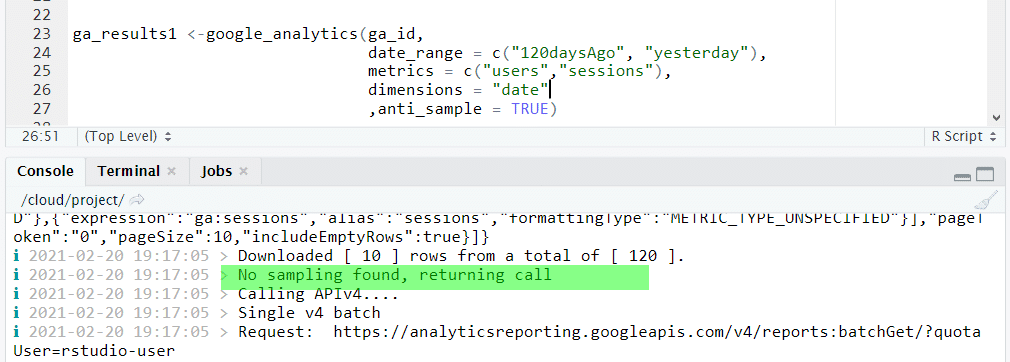
Stiahnutie údajov
.
Stiahnite si zoznam účtov GA, ku ktorým máme prístup
.
Týmto krokom vždy začínam prácu s programom GA. Umožňuje mi overiť, či môj skript získal pripojenie k rozhraniu API a či mám prístup k účtom, ktoré ma zaujímajú. Toto sa vykonáva volaním funkcie ga_account_list().
![]()
![]()
Čo nám dáva objekt s názvom my_acc obsahujúci informácie o zobrazeniach údajov a účtoch GA, ku ktorým máme prístup. To nám umožňuje vytvoriť objekt (v tomto prípade maticu s názvom data_GA), ktorý obsahuje všetky ID zobrazení údajov a názvy účtov, ku ktorým máme prístup.
![]()
![]()
Takto získame nasledujúci objekt:
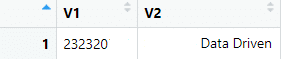
Počet výsledkov
.
V predvolenom nastavení API vráti iba 100 výsledkov. Počet výsledkov možno nastaviť pomocou parametra limit. Ak chcete získať všetky výsledky, zadajte parametru limit hodnotu -1.

Rozsahy dátumov
.
V predvolenom nastavení je rozsah dátumov, ktorý načítame, nastavený prostredníctvom parametra date_range. Je možné vybrať viac ako jeden rozsah dátumov.

Čo je veľmi užitočné, namiesto konkrétnych dátumov (vždy vo formáte RRRR-MM-DD) môžeme použiť univerzálne parametre, napríklad včera alebo XXdníAgo. Ten vráti dátum XX dní pred dnešným dňom (namiesto XX vložíme konkrétny počet dní, takže napríklad 7daysAgo nám poskytne dátum pred 7 dňami).
Filtrovanie údajov
.
Ak chcete skrátiť čas čakania na údaje, oplatí sa použiť filtrovanie. Umožňuje načítať len vybrané údaje. Filtrovanie je možné na dvoch úrovniach: metriky a/alebo dimenzie (na to slúžia parametre met_filters – filtrovanie podľa metriky a dim_filters – filtrovanie podľa dimenzie).
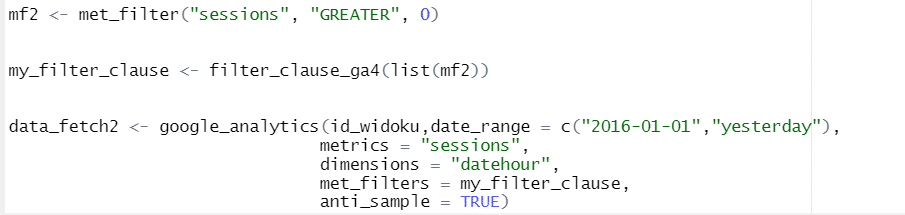
Met_filter() prijíma nasledujúce parametre:
- .
- metrika – metrika, podľa ktorej filtrujeme (napr. relácie)
- operátor – nadobúda jednu z nasledujúcich hodnôt :
- „EQUAL“ – rovná sa
- „Menej ako“ – menej ako
- „Viac ako“ – viac ako
- „IS_MISSING“ – chýbajúca hodnota
- comparisonValue – hodnota metriky, ktorú chceme filtrovať alebo odfiltrovať
- nie – ak nadobúda hodnotu TRUE, potom do výsledkov nezahrnieme údaje zodpovedajúce filtru.
- Dim_filter() – použijeme túto funkciu s parametrami:
- dimenzia – dimenzia, podľa ktorej filtrujeme (napr. typ zariadenia = Desktop alebo krajina používateľa = Poľsko;
- Operátor – funguje rovnako ako pri met_filter a môže nadobúdať jednu z hodnôt:
- REGEXP – kontroluje, či pole zadané vo výrazoch zodpovedá zadanému regulárnemu výrazu
- Začína sa – začína sa zadaným filtrom
- KONČÍ_VYBRANÝM – končí zadaným filtrom
- PARTIÁLNE – obsahuje zadaný fragment
- EXACT – má presne takú hodnotu, aká je zadaná
- NUMERIC_EQUAL – má číslo rovné zadanej hodnote
- NUMERIC_GREATER_THAN – je číslo väčšie ako dané
- NUMERIC_LESS_THAN – je číslo menšie ako dané číslo
- IN_LIST – je v zozname hodnôt, ktoré sme zadali
- Výraz – výraz (číslo alebo text, ktorý hľadáme v názve dimenzie)
- Casesitive – ak má hodnotu TRUE, rozlišuje veľké a malé písmená (upper/lower case sensitive)
- Nie – funguje rovnako ako pri met_filter.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Úplný zoznam filtrov a rozmerov dostupných v GA môžeme skontrolovať pomocou funkcie ga_meta.
![]()
![]()
Poskytne nám objekt obsahujúci podrobný popis všetkých (vrátane už stiahnutých – označených ako DEPRECATED v poli status) rozmerov a metrík.
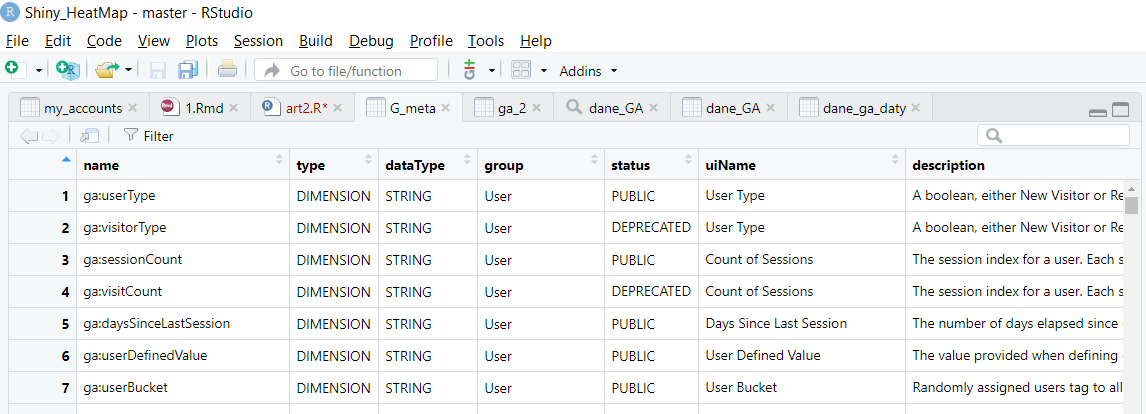
Po vytvorení objektu filtra metrík a/alebo rozmerov je potrebné vytvoriť objekt filtra pomocou funkcie filter_clause_ga4. Tento objekt používame vo funkcii google_analytics. To nám umožňuje vytvárať pokročilé filtre pre kombinácie viac ako jednej metriky a/alebo dimenzie.
Nižšie filtrujeme údaje tak, aby zahŕňali len návštevy (metrika) z krajiny Poľsko (dimenzia s názvom contry nadobúda hodnotu Poland).
Vytvoríme filter pre údaje, v ktorých dimenzia krajina obsahuje presne reťazec Poľsko – to znamená, že odmietneme všetky návštevy z iných krajín ako Poľsko.
![]()
![]()
Na základe tohto filtra vytvoríme objekt filtra:
![]()
![]()
Vo funkcii, ktorá načítava údaje, používame objekt filtra:

Kód použitý v tejto časti je k dispozícii zde.
Súhrn
.
Mnohí z nás SEO optimalizátorov sa zameriavajú na vyhľadávač Google. Samozrejme, nástroje ako priama odpoveď poskytujú veľa informácií o tom, čo sa deje vo vyhľadávači. Aj napriek tomu by však základom každej analýzy mali byť údaje od samotnej spoločnosti Google. Svoje dobrodružstvo pri aplikácii programovania do SEO som začal práve sťahovaním údajov z tu opísaného nástroja. Pre mňa sa to premietlo do lepšieho pochopenia toho, čo sa vo vyhľadávači deje, a v konečnom dôsledku do vyšších pozícií. Ako všetky nástroje, aj tie od spoločnosti Google si vyžadujú pochopenie možností a obmedzení, aby sa dali dobre používať.
Najdôležitejšie veci, ktoré je potrebné mať na pamäti:.
- .
- Údaje z analytických služieb Google nie sú na 100 % zosúladené s údajmi z konzoly vyhľadávania Google
- Údaje Google nezdieľajú informácie o konkurencii
- Analytické údaje Google sa zhromažďujú „na vašej strane“. – takže môžete nahrať množstvo ďalších informácií (napr. pri blogových príspevkoch meno autora alebo názov výrobcu v obchode)
- Údaje služby Google Search Console sa zhromažďujú na strane spoločnosti Google – preto si na zhromažďovanie údajov stačí vytvoriť účet.
.
.
.
Pomocou jazyka R môžete:.
- zbierať veľké množstvo údajov (oveľa viac, ako sa vám zmestí do Excelu – niečo cez milión riadkov)
- exportovať výsledné údaje (napr. do excelu)
- spájať údaje z viacerých zdrojov
- obísť obmedzenia bezplatných nástrojov Google, ak je to možné
.
.
.
.
Odporúčam vám otestovať, komentovať a implementovať riešenia, ktoré som tu opísal, alebo vaše vlastné nápady.
Uvidíme sa v SERP!
Ďakujem za prečítanie!
Zaregistrujte sa zadarmo a pridajte sa k viac ako 14 000 používateľom Senuto ????
FAQ
install.packages() s menami knižníc, ktoré potrebujete, ako sú napríklad "searchConsoleR" a "googleAnalyticsR".
installed.packages() a porovnať výsledok s požadovanými knižnicami. Ak knižnice ešte nie sú nainštalované, môžete ich nainštalovať.
searchConsoleR, ktorá umožňuje autorizáciu a získavanie údajov prostredníctvom jednoduchých príkazov v R, ako je scr_auth() pre autorizáciu.
searchConsoleR, ktorá umožňuje stiahnuť údaje v dávkach až do 25 000 riadkov.
googleAnalyticsR. Nastavenie Google Analytics, Rýchle získavanie údajov z Google Search a Google Analytics v R, SEO stratégia založená na analýze konkurencie.