 Piotr Smargol
Piotr Smargol Nenápadný súbor robots.txt umožňuje kontrolovať prístup robotov vyhľadávačov na vaše webové stránky. Z tohto dôvodu zohráva v SEO kľúčovú úlohu a oplatí sa mu venovať náležitú pozornosť, najmä pri pokročilejších SEO aktivitách. V tomto článku si povieme, čo je súbor robots.txt, na čo slúži a prečo je dôležitý, a potom prejdeme k vzorovým pravidlám a návodu, ako si takýto súbor vytvoriť sami.
Hlavné závery
- Súbor robots.txt je textový súbor, ktorý poskytuje pokyny pre webové roboty o tom, ktoré časti stránky môžu alebo nemôžu prehliadať, čo je zásadné pre efektívne SEO a viditeľnosť Senuto.
- Pravidlá v súbore robots.txt umožňujú blokovať prístup robotom k určitým častiam webovej stránky, čím ovplyvňujú indexáciu a môžu zohrávať kľúčovú úlohu v SEO stratégii.
- Robots.txt môže obsahovať odkazy na XML mapy stránok, ktoré pomáhajú robotom vyhľadávačov efektívne indexovať obsah stránky.
- Je dôležité správne vytvoriť a umiestniť súbor robots.txt, pretože chyby môžu obmedziť návštevnosť zo SEO alebo neúmyselne blokovať dôležitý obsah.
- Pre overenie správnosti súboru robots.txt môžu užívatelia využiť nástroje ako Google Search Console, ktoré umožňujú testovať a analyzovať účinnosť pokynov pre roboty.
Čo je súbor robots.txt a prečo sa používa?
Súbor s presným názvom robots.txt je jednoduchý textový súbor – uložený vo formáte .txt a umiestnený priamo v koreňovom priečinku domény.
Vo vnútri súboru umiestňujeme pokyny pre roboty, ktoré navštevujú naše webové stránky.
V týchto pokynoch určíme, ktoré stránky z koreňového adresára domény môžu roboty navštíviť a ktorým možnosť návštevy zablokujeme.
Stojí za zmienku, že roboty môžu obísť smernice umiestnené v súbore robots.txt a stále sa pýtať na stránky alebo sekcie, ktoré sú tam umiestnené.
Prečo je súbor robots.txt dôležitý?
.
Dôležitosť súboru robots.txt môžeme poznať podľa toho, ako robot Google prehľadáva stránky.
Keď robot Google narazí na vašu stránku prepojenú z inej domény, ktorá sa už nachádza v jeho indexe, okamžite skontroluje súbor robots.txt, aby overil, ktoré zdroje na stránke môže navštíviť. Potom tento súbor pravidelne navštevuje, aby zistil, či sa niečo v usmerneniach nezmenilo.
Analýzou protokolov webových lokalít môžeme zistiť, že súbor robots.txt je aj na malých webových lokalitách navštevovaný desiatky či desiatky krát mesačne.
Okrem už spomínanej možnosti blokovania prístupu robotov na určité miesta na stránke používame súbor robots.txt na podlinkovanie adresy URL mapy stránok XML. Prepojenie mapy lokality je tu dôležité najmä vtedy, keď nemáme profil v službe Google Search Console a keď má naša mapa lokality nefunkčnú adresu URL.
Za zmienku stojí aj to, ako starostlivo Google napĺňa svoj súbor robots.txt, ktorý sa nachádza na adrese URL https://www.google.com/robots.txt.
Vyskúšajte Senuto Suite na 14 dní zadarmo
Vyskúšajte si 14-dňovú bezplatnú verziuPríklady pravidiel v súbore robots.txt. Z akých skupín a smerníc sa takýto súbor skladá?
.
Každý súbor robots.txt je zostavený zo skupín. Do skupiny smerníc patria napr:
- odkaz na názov bota,
Každá aplikácia alebo používateľ, ktorý navštívi stránku, je predstavený svojím klientskym menom alebo inak známym ako meno bota. Práve toto meno uvádzame v smerniciach vo vnútri súboru v smernici User-agent. - informácia o tom, ktoré zdroje sú vylúčené alebo povolené na návštevu uvedeným botom.
.
Takéto skupiny nám predovšetkým umožňujú:
- .
- Vybrať názov bota, na ktorého chceme nasmerovať smernice.
Užívateľský agent: AdsBot-Google
.
- Pridáme smernice na blokovanie prístupu do konkrétnych adresárov alebo na konkrétne adresy URL.
Zakázať: /maps/api/js/
.
- Pridanie direktív na povolenie prístupu k špecifickým adresárom alebo URL.
Povolenie:
Povoliť: /maps/api/js
.
Každá ďalšia skupina môže obsahovať ďalšie meno robota a smernice pre ďalšieho robota, napr:
Užívateľský agent: Twitterbot Allow: /imgres
.
V súhrne dostaneme súbor skupín:
User-agent: AdsBot-Google Zakázať: /maps/api/js/ Povoliť: /maps/api/js Zakázať: /maps/api/place/js/ Zakázať: /maps/api/staticmap Zakázať: /maps/api/streetview User-agent: Twitterbot Povoliť: TwitterPay, TwitterPay, TwitterPay, TwitterPay, TwitterPay: /imgres
Všimnite si však, že riadky vo vnútri skupiny sa spracúvajú zhora nadol a klient používateľa (v tomto prípade: meno robota) sa priradí len k jednej sade pravidiel, presnejšie k prvému najsilnejšie špecifikovanému pravidlu, ktoré sa naň vzťahuje.
Na samotnom poradí skupín v súbore nezáleží. Za zmienku stojí aj to, že pri robotoch sa rozlišujú veľké a malé písmená. Napríklad pravidlo:
Disallow: /file.asp
platí pre podstránku http://www.example.com/file.asp, ale pre podstránku http://www.example.com/FILE.asp – už nie.
To by však nemalo spôsobovať problémy, ak v našej doméne správne vytvárame adresy URL.
Nakoniec, ak pre jedného robota existuje viac ako jedna skupina, smernice z duplicitných skupín sa zlúčia do jednej skupiny.
Užívateľský agent
.
K názvu každého robota sa priradí iba jedna zo skupín umiestnených v súbore robots.txt a ostatné sa ignorujú. Preto robot s názvom Senuto, ktorý vidí pravidlá v súbore robots.txt domény:
User-agent: * disallow: /search/ User-agent: Senuto allow: /search/
vyberie nižšie uvedené pravidlo (v príklade) a sprístupní adresár /search/, pretože je presne cielené naň.
Disallow
.
Smernica disallow určuje, ku ktorým adresárom, cestám alebo adresám URL nemajú vybraní roboti prístup.
disallow: [cesta]
.
disallow: [address-URL]
.
Smernica sa ignoruje, ak nie je vyplnená žiadna cesta alebo adresár.
disallow:
.
Príklad použitia smernice:
disallow: /search
Uvedená smernica zablokuje prístup k adresám URL:
- https://www.domena.pl/search/
- https://www.domena.pl/search/test-site/
- https://www.domena.pl/searches/
.
Stojí za zmienku, že príklad, o ktorom sa tu hovorí, sa vzťahuje len na použitie jedného pravidla pre jedného určeného robota.
Povolenie
.
Smernica allow určuje, ku ktorým adresárom, cestám alebo adresám URL majú určení roboti povolený prístup.
allow: [cesta]
.
allow: [adresa-URL]
Táto smernica sa ignoruje, ak nie je vyplnená žiadna cesta alebo adresár.
allow:
.
Príklad použitia smernice:
allow: /images
Uvedená smernica umožní prístup k adresám URL:
- https://www.domena.pl/images/
- https://www.domena.pl/images/test-site/
- https://www.domena.pl/images-send/
.
Stojí za zmienku, že príklad, o ktorom sa tu hovorí, sa vzťahuje len na použitie jedného pravidla pre jedného uvedeného robota.
Mapa stránky
.
Do súboru robots.txt môžeme tiež zahrnúť odkaz na mapu nášho webu vo formáte XML. Keďže stránku robots.txt navštevuje robot Google pravidelne a je jednou z prvých stránok na webe, na ktoré pristupuje, má veľký zmysel zahrnúť odkaz na mapu webu.
mapa stránky: [unlabeled-address-URL]
.
V usmerneniach spoločnosti Google sa uvádza, že adresa URL mapy stránok by mala byť absolútna (úplná, správna adresa URL), takže napr:
sitemap: https://www.domena.pl/sitemap.xml
Ďalšie smernice
.
V súboroch robots.txt môžeme nájsť aj ďalšie smernice, a to:
- host – smernica host sa používa na označenie preferovanej domény spomedzi mnohých jej kópií dostupných na internete.
- crawl delay – v závislosti od robota sa táto smernica môže používať rôzne. V prípade robota vyhľadávača Bing bude čas uvedený v poli crawl delay minimálnym časom medzi prvým a druhým prehľadávaním jednej podstránky webu. Na druhej strane Yandex bude túto smernicu čítať ako čas, ktorý musí robot počkať pred vyhľadaním každej ďalšej stránky v doméne.
.
Obe tieto smernice bude Google ignorovať a pri prehľadávaní stránky ich nebude brať do úvahy.
Môžeme v pravidlách používať regulárne výrazy?
.
Roboty (ale nielen) vyhľadávača Google podporujú v cestách jednotlivé znaky so špeciálnymi vlastnosťami. Medzi takéto znaky patria napr:
- .
- znakasterisk * – označuje nula alebo viac výskytov ľubovoľného znaku,
- znak dolára $ – označuje koniec adresy URL.
.
.
Toto sa úplne nezhoduje s tým, čo poznáme z regulárnych výrazov https://pl.wikipedia.org/wiki/Wyrażenie_regularne. Za zmienku stojí aj to, že vlastnosti znakov * a $ nie sú zahrnuté v norme pre vylúčenie robotov https://en.wikipedia.org/wiki/Robots_exclusion_standard.
Príkladom použitia týchto znakov nofollow by bolo pravidlo:
disallow: *vyhľadáva*
.
Citované pravidlo bude rovnaké ako pravidlo:
disallow: searches
a znaky * sa budú jednoducho ignorovať.
Tieto znaky nájdu využitie napríklad vtedy, keď chcete zablokovať prístup k stránkam, kde sa medzi dvoma priečinkami v adrese URL môžu nachádzať ďalšie priečinky, a to buď jednotlivo, alebo opakovane.
Pravidlo na blokovanie prístupu k stránkam, ktoré majú v adrese URL priečinok /search/ a hlbšie v štruktúre stránky priečinok /on-demand/, by vyzeralo takto:
disallow: /search/*/on-demand
Pomocou uvedeného pravidla zablokujeme prístup k týmto adresám URL:
- https://www.domena.pl/search/wstawka-w-url/on-demand/wlasciwy-url/
- https://www.domena.pl/search/a/on-demand/,
.
Nebudeme však blokovať prístup k týmto:
- https://www.domena.pl/search/on-demand/
- https://www.domena.pl/on-demand/
- https://www.domena.pl/search/adres-url/
Zaujímavým príkladom by bolo zablokovanie prístupu ku všetkým súborom s príponou .pdf (predpokladáme, že každý súbor s touto príponou v našej doméne je takto ukončený), ktoré v adrese URL obsahujú priečinok /data-client/. Na tento účel použijeme smernicu:
disallow: /data-client/*.pdf$
Viac informácií o správnej syntaxi a pravidlách, ktoré treba zahrnúť do súboru robots.txt, si môžete prečítať v špecifikácii syntaxe ABNF na adrese URL: https://datatracker.ietf.org/doc/html/rfc5234
Čo by mal obsahovať základný súbor robots.txt
.
Aby sa súbor robots.txt správne čítal, mal by:
- byť textový súbor v kódovaní UTF-8,
- miet názov: robots.txt (ukážka URL https://www.domena.pl/robots.txt),
- byť umiestnený priamo v koreňovom priečinku domény,
- byť jedinečný v rámci domény – nemal by existovať viac ako jeden súbor robots.txt, pretože pokyny v súboroch umiestnených na inej ako uvedenej adrese URL sa nebudú čítať,
- obsahovať minimálne jednu skupinu smerníc vo vnútri súboru
.
.
.
.
.
V súbore môžeme niekedy nájsť aj znak #. Umožňuje pridať komentáre vo vnútri súboru, ktoré robot Google nebude čítať. Keď do riadku vložíte znak #, akýkoľvek znak nasledujúci za týmto znakom v tom istom riadku nebude Google čítať.
disallow: /search/ #žiadny zo znakov nasledujúcich za "plot" nebude robot Google čítať
.
Ako vytvoriť súbor robots.txt
.
V tejto chvíli sme pripravení vytvoriť takýto súbor sami. Budeme na to potrebovať ľubovoľný textový editor: MS Word, Poznámkový blok atď. V editore vytvoríme prázdny textový dokument a jednoducho ho nazveme robots.txt.
Ďalším krokom je doplnenie textového dokumentu správnymi smernicami. Pred ich zadaním by sme sa mali pripraviť:
- zoznam robotov, ktorých sa majú obmedzenia týkať,
- zoznam robotov, na ktoré sa obmedzenia nebudú vzťahovať,
- zoznam stránok, ku ktorým chceme zablokovať prístup,
- zoznam stránok, ktorých prístup nemôžeme blokovať,
- adresa URL mapy stránok,
.
.
.
.
.
Keď máme uvedené údaje, môžeme začať ručne vpisovať pravidlá jedno pod druhé do vytvoreného textového dokumentu. Príklad súboru robots.txt:
Užívateľský agent: * disallow: /business-card # zablokujte prístup k stránkam v priečinku business-card. disallow: /*pdf$ # zablokuje prístup k súborom s príponou .pdf disallow: sortby= # zablokuje prístup k súborom, ktoré majú v url adrese triedenie User-agent: ownbotsc1 allow: * sitemap: <https://www.domena.pl/sitemap_product.xml> #odkaz na xml sitemap sitemap: <https://www.domena.pl/sitemap_category.xml> sitemap: <https://www.domena.pl/sitemap_static.xml> sitemap: <https://www.domena.pl/sitemap_blog.xml>
.
Takto vytvorený dokument musíme umiestniť do koreňového priečinka našej domény na serveri FTP, kde sa nachádzajú jeho súbory. Stojí za zmienku, že v systémoch na správu obsahu, ako je napríklad WordPress, nájdeme pluginy, ktoré nám umožnia upravovať súbor robots.txt umiestnený na serveri FTP.
Ako otestovať, či sú pokyny v súbore robots.txt správne?
.
Ak chceme dôkladne otestovať, či nami vytvorený súbor robots.txt bude fungovať správne, musíme navštíviť: https://www.google.com/webmasters/tools/robots-testing-tool.
Tu nájdeme tester, ktorý stiahne súbor robot.txt, ktorý sa aktuálne nachádza na doméne (musíme byť jej overeným vlastníkom v Google Search Console), a potom nám umožní ho upraviť a skontrolovať, či sa nami uvedené podstránky zablokujú alebo prejdú podľa smerníc v ňom uvedených.
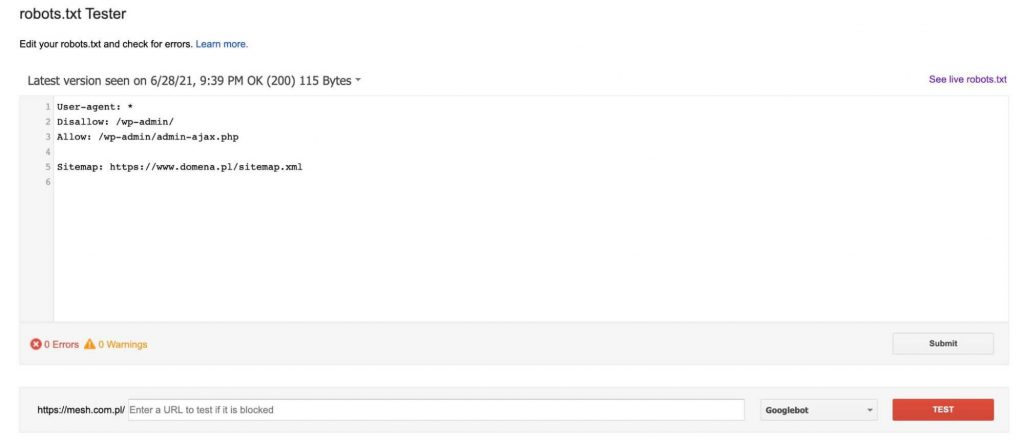
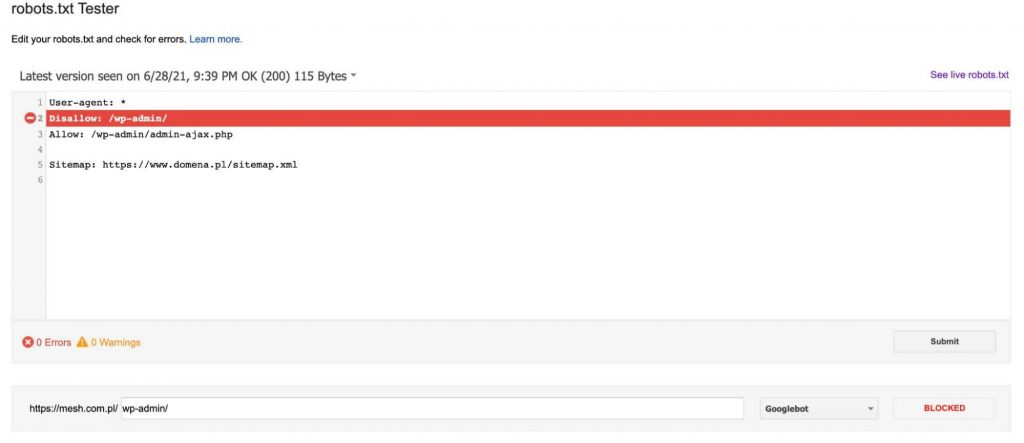
Vždy po pridaní adresy URL do testu (v dolnej časti grafiky) klikneme na červené tlačidlo „TEST“ a v odpovedi dostaneme informáciu o tom, či bola uvedená adresa URL zablokovaná, a ak áno, ktorý riadok textu v súbore robots.txt zablokoval našu adresu URL.
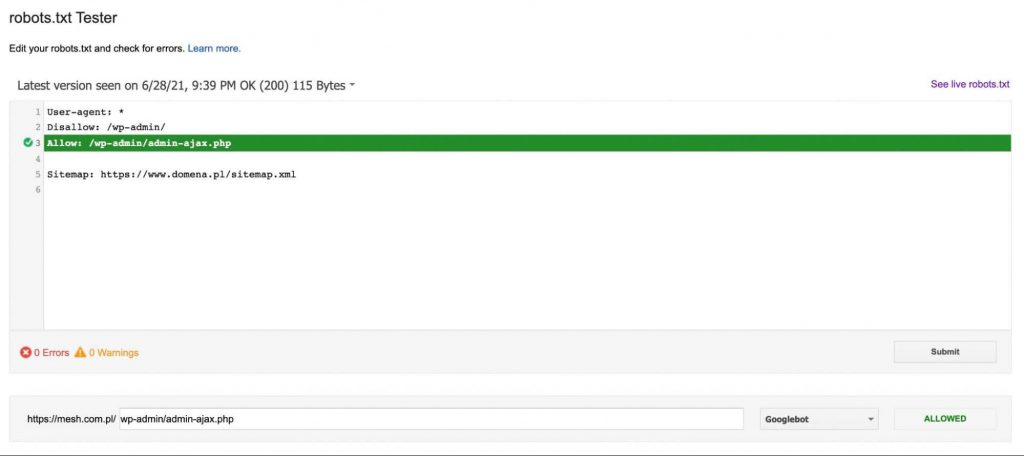
Ak adresa URL nie je zablokovaná, dostaneme správu, ktorá sprístupní adresu URL smernice robotovi Google – ako na nasledujúcom grafe:
Čomu venovať pozornosť pri vytváraní súboru robots.txt?
.
Pri vytváraní súboru robots.txt by sme mali dbať najmä na to, aby sme úplne alebo čiastočne zablokovali prístup robota Google na stránku. Všetky zmeny v tomto súbore by ste preto mali konzultovať s odborníkom, aby ste svojmu webu ešte viac neuškodili.
Treba však poznamenať, že súbor robots.txt nezablokuje indexovanie webu robotmi. Spoločnosť Google pripúšťa možnosť, že ak sa jej robot dostal na niektorú z našich podstránok z inej domény, tak pokiaľ je táto stránka považovaná za hodnotnú, pôjde do indexu.
Ďalšou dôležitou poznámkou je, že väčšina robotov, ktoré nie sú súčasťou spoločnosti Google, sa neriadi pokynmi v súbore robots.txt a ignoruje príkazy v ňom uvedené.
Súhrn
.
Súbor robots.txt je určite dôležitým prvkom technickej optimalizácie SEO. Jeho zlým vyplnením hrozí obmedzenie návštevnosti zo SEO, zatiaľ čo jeho dobré vyplnenie pomôže spravovať indexáciu webu a rozpočet na prehľadávanie. Čím väčší je objem návštevnosti na stránke, čím viac podstránok na našej stránke existuje, tým lepšie je dbať na správne vyplnenie robots.txt.
.