 Piotr Smargol
Piotr Smargol  Csaba Pirosca
Csaba Pirosca Acest fisier discret permite controlul accesului robotilor motoarelor de cautare la site-ul dvs. web. De aceea, joaca un rol esential in SEO si merita atentia necesara, mai ales in activitatile SEO avansate. In acest articol, vom explora ce este fisierul robots.txt, scopul sau si importanta sa, iar ulterior vom prezenta exemple de reguli si instructiuni pentru a crea singur un astfel de fisier.
Concluziile principale
- Fisierul robots.txt controleaza accesul robotilor de cautare la anumite parti ale site-ului, influentand indexarea si vizibilitatea in motoarele de cautare, element esential pentru o buna Analiză de Vizibilitate Senuto.
- Robotii motoarelor de cautare, precum Google, utilizeaza fisierul robots.txt pentru a identifica resursele accesibile pe site, astfel incat sa poata actualiza periodic indexul lor.
- Crearea unui fisier robots.txt implica utilizarea unui editor de text si plasarea acestuia in folderul radacina al domeniului, cu seturi de reguli specifice pentru diferiti roboti.
- Desi majoritatea motoarelor de cautare respecta fisierul robots.txt, unii roboti pot ignora instructiunile si accesa continutul blocat.
- Fisierul robots.txt poate utiliza caractere speciale, cum ar fi asteriscul (*) si semnul dolar ($), pentru a crea reguli mai flexibile si mai detaliate.
Ce este un fisier robots.txt si de ce este utilizat?
Fisierul denumit exact robots.txt este un fisier text simplu, salvat in format .txt si plasat direct in folderul radacina al domeniului.
Acest fisier contine directive pentru robotii care viziteaza site-ul nostru.
In aceste linii directoare, specificam ce pagini din radacina domeniului pot fi vizitate de robotii si care sunt cele carora le blocam posibilitatea de a fi vizitate.
Este important de mentionat ca robotii pot ignora directivele din fisierul robots.txt si pot continua sa acceseze paginile sau sectiunile respective.
Încearcă Senuto Suite gratuit timp de 14 zile
Încearcă gratuit 14 zileDe ce este important fisierul robots.txt?
Putem intelege importanta fisierului robots.txt prin modul in care robotul Google scaneaza paginile web.
Cand robotul Google descopera site-ul dvs. printr-un link de pe un alt domeniu deja indexat, acesta verifica imediat fisierul robots.txt pentru a vedea ce resurse poate accesa pe site-ul dvs. Apoi, revine periodic pentru a verifica daca au aparut modificari in fisierul respectiv.
Analizand jurnalele site-ului, observam ca fisierul robots.txt este accesat de zeci de ori pe luna, chiar si in cazul site-urilor mici.
In plus fata de posibilitatea de a bloca accesul robotilor la anumite sectiuni ale site-ului, folosim fisierul robots.txt pentru a indica adresa URL a hărții site-ului XML.
Acest aspect este deosebit de important, mai ales daca nu avem un profil in Google Search Console sau daca harta site-ului nostru are un URL neobisnuit.
De asemenea, merita mentionat cat de meticulos isi gestioneaza Google fisierul robots.txt, care poate fi gasit la adresa URL https://www.google.com/robots.txt.
Exemplu de reguli in robots.txt. Din ce grupe si directive este alcatuit un astfel de fisier?
Fiecare fisier robots.txt consta din grupuri de directive. Un grup de directive include:
- referinta la numele robotului.
Fiecare aplicatie sau utilizator care acceseaza site-ul este reprezentat prin denumirea sa de client sau, altfel spus, numele botului. Acest nume este specificat in directivele din fisier, sub directiva User-agent. - informatii referitoare la resursele excluse sau permise pentru botul respectiv.
Aceste grupuri permit, in principal:
- selectarea numelui botului catre care dorim sa directionam directivele.
User-agent: AdsBot-Google
- adaugarea de directive pentru a restrictiona accesul la anumite directoare sau URL-uri.
Disallow: /maps/api/js/
- adaugarea de directive pentru a permite accesul la anumite directoare sau URL-uri.
Allow: /maps/api/js
Fiecare grup ulterior poate contine un alt nume de robot si directive specifice acestuia. De exemplu:
User-agent: Twitterbot
Allow: /imgres
In concluzie, obtinem un set de grupuri:
User-agent: AdsBot-Google
Disallow: /maps/api/js/
Allow: /maps/api/js
Disallow: /maps/api/place/js/
Disallow: /maps/api/staticmap
Disallow: /maps/api/streetview
User-agent: Twitterbot
Allow: /imgres
Este esential de mentionat ca liniile din interiorul unui grup sunt procesate de sus in jos, iar clientul utilizatorului (in acest caz, numele robotului) este asociat cu un singur set de reguli, sau, mai exact, cu prima regula cel mai specificata care ii este aplicabila.
Ordinea grupurilor din fisier nu are relevanta. De asemenea, trebuie subliniat faptul ca robotii sunt sensibili la majuscule si minuscule. De exemplu, regula:
Disallow: /file.asp
se aplica subpaginii http://www.example.com/file.asp, dar nu se aplica subpaginii http://www.example.com/FILE.asp.
Aceasta nu ar trebui sa genereze probleme daca URL-urile sunt create corect in cadrul domeniului nostru.
In concluzie, daca exista mai multe grupuri pentru un robot, directivele din aceste grupuri duplicate sunt consolidate intr-un singur grup.
User-Agent
Doar unul dintre grupurile plasate în fișierul robots.txt este asociat cu numele fiecărui robot, iar celelalte sunt ignorate. Prin urmare, un robot numit Senuto, observând regulile din fișierul robots.txt al domeniului:
User-agent: *
Disallow: /search/
User-agent: Senuto
Allow: /search/
va selecta regula specificată pentru el (în exemplu) și va putea accesa directorul /search/, deoarece este clar direcționată catre acesta.
Disallow
Directiva Disallow specifica ce directoare, cai sau URL-uri nu pot fi accesate de catre robotii selectati.
Disallow: [path]
Disallow: [address-URL]
Directiva este ignorata daca nu este completata nicio cale sau niciun director.
Disallow:
Exemplu de utilizare a directivei:
Disallow: /search
Directiva de mai sus va bloca accesul la URL-urile:
https://www.domena.pl/search/
https://www.domena.pl/search/test-site/
https://www.domena.pl/searches/
Este important de mentionat ca exemplul prezentat aici se refera doar la aplicarea unei singure reguli pentru un anumit robot specific.
Autorizare
Directiva Allow indica robotilor desemnati ce directoare, cai sau URL-uri pot sa acceseze.
Allow: [path]
Allow: [adresa-URL]
Directiva este neglijata daca nu este specificata nicio cale sau director.
Allow:
Exemplu de utilizare a directivei:
Allow: /images
Directiva de mai sus va permite accesul la URL-uri:
https://www.domena.pl/images/
https://www.domena.pl/images/test-site/
https://www.domena.pl/images-send/
Este important de mentionat ca exemplul prezentat aici se aplica exclusiv atunci cand se utilizeaza o singura regula pentru un anumit robot specificat.
Sitemap
In fisierul robots.txt, avem posibilitatea de a include si un link catre harta site-ului nostru in format XML. Avand in vedere ca fisierul robots.txt este accesat frecvent de catre robotul Google si reprezinta una dintre primele pagini verificate pe site, este foarte logic sa adaugam un link catre harta site-ului.
Sitemap: [unlabeled-address-URL]
Ghidul Google specifica faptul ca URL-ul sitemap trebuie sa fie absolut (URL complet). De exemplu:
Sitemap: https://www.domena.pl/sitemap.xml
Alte directive
In fisierile robots.txt se pot regasi si alte directive, cum ar fi:
- Host – Aceasta directiva este utilizata pentru a specifica domeniul preferat dintre multiplele versiuni disponibile pe Internet.
- Crawl delay – In functie de robot, aceasta directiva poate avea utilizari diferite. Pentru robotul motorului de cautare Bing, timpul indicat in crawl delay reprezinta intervalul minim dintre prima si a doua accesare a unei subpagini a site-ului. In schimb, Yandex interpreteaza aceasta directiva ca fiind timpul pe care robotul trebuie sa-l astepte inainte de a accesa fiecare pagina noua din domeniu.
Ambele directive vor fi ignorate de Google si nu vor fi luate in considerare in procesul de scanare a site-ului.
Pot fi folosite expresii regulate in reguli?
Motoarele de cautare, inclusiv Google, recunosc caractere speciale in caile de acces din fisierul robots.txt. Aceste caractere includ:
- Asterisc (*) – care indica zero sau mai multe aparitii ale oricarui caracter.
- Semnul dolar ($) – care indica sfarsitul URL-ului.
Aceste caracteristici nu se aliniază complet cu ceea ce stim despre expresiile regulate, asa cum se poate vedea aici: https://pl.wikipedia.org/wiki/Wyrazenie_regularne. Este important de mentionat ca proprietatile caracterelor * si $ nu sunt incluse in standardul de excludere a robotilor: https://en.wikipedia.org/wiki/Robots_exclusion_standard.
Un exemplu de utilizare a acestor caractere in directivele nofollow ar putea fi:
Disallow: search
Aceasta regula este echivalenta cu:
Disallow: searches
si caracterele * vor fi pur si simplu ignorate.
Aceste caractere sunt utile, de exemplu, cand doriti sa blocati accesul la pagini unde pot exista alte dosare intre doua dosare din URL, fie singure, fie repetate.
O regula pentru a bloca accesul la paginile care au un folder /search/ in URL si un folder /on-demand/ mai adanc in structura paginii ar fi:
Disallow: /search/*/on-demand
Aceasta regula va bloca accesul la urmatoarele URL-uri:
https://www.domena.pl/search/wstawka-w-url/on-demand/wlasciwy-url/
https://www.domena.pl/search/a/on-demand/
Insa nu va bloca accesul la:
https://www.domena.pl/search/on-demand/
https://www.domena.pl/on-demand/
https://www.domena.pl/search/adres-url/
Un alt exemplu ar fi blocarea accesului la toate fiserele cu extensia .pdf (presupunand ca orice fisier cu aceasta extensie se termina astfel) care contin folderul /data-client/ in URL. Pentru aceasta, vom folosi directiva:
Disallow: /data-client/*.pdf$
Puteti citi mai multe despre sintaxa corecta si regulile care trebuie incluse intr-un fisier robots.txt aici: https://datatracker.ietf.org/doc/html/rfc5234.
Ce ar trebui sa contina un fisier robots.txt de baza
Pentru ca un fisier robots.txt sa fie citit corect, acesta ar trebui sa indeplineasca urmatoarele criterii:
- Sa fie un fisier text in codificare UTF-8.
- Sa aiba numele: robots.txt (URL de exemplu: https://www.domena.pl/robots.txt).
- Sa fie plasat direct in directorul radacina al domeniului.
- Sa fie unic pentru domeniul respectiv – nu ar trebui sa existe mai mult de un fisier robots.txt, deoarece directivele din alte fisiere plasate la alte URL-uri nu vor fi luate in considerare.
- Sa contina cel putin un set de directive.
De asemenea, uneori putem gasi semnul # in fisier. Acesta permite adaugarea de comentarii in fisier, care nu vor fi citite de robotul Google. Atunci cand pui un # pe o linie, orice caracter care urmeaza acestuia in aceeasi linie nu va fi citit de Google.
Disallow: /search/ #orice caracter dupa „fence” nu va fi citit de robotul Google.
Cum se creeaza un fisier robots.txt?
Acum suntem pregatiti sa cream propriul nostru fisier robots.txt. Pentru a face acest lucru, vom avea nevoie de un editor de text, cum ar fi MS Word, Notepad, etc. In editor, cream un document text nou si il denumim simplu robots.txt.
Pasul urmator este completarea documentului cu directivele corecte. Inainte de a incepe sa le tastam, ar trebui sa ne pregatim cu:
- Lista robotilor care vor fi supusi restrictiilor.
- Lista robotilor care nu vor fi supusi restrictiilor.
- Lista paginilor de pe site la care dorim sa blocam accesul.
- Lista paginilor de pe site la care nu putem bloca accesul.
- URL-ul hartii site-ului.
Avand aceste date, putem incepe sa scriem manual regulile in documentul text creat. Iata un exemplu de fisier robots.txt:
User-agent: * disallow: /business-card #blochează accesul la paginile din folderul business-card. disallow: /*.pdf$ #blochează accesul la fișierele cu extensia .pdf disallow: sortby= #blochează accesul la fișierele care au sortare în url User-agent: ownbotsc1 allow: * sitemap: <https://www.domena.pl/sitemap_product.xml> #link to xml sitemap sitemap: <https://www.domena.pl/sitemap_category.xml> sitemap: <https://www.domena.pl/sitemap_static.xml> sitemap: <https://www.domena.pl/sitemap_blog.xml>
Trebuie sa plasam documentul creat in acest mod in directorul radacina al domeniului nostru pe serverul FTP unde se afla fisierele site-ului. Este de remarcat ca in sistemele de gestionare a continutului, cum ar fi WordPress, exista plug-in-uri care ne permit sa editam fisierul robots.txt direct pe serverul FTP.
Cum sa verificam corectitudinea directivelor din fisierul robots.txt?
Aici vom găsi un instrument care va descărca fișierul robots.txt actual de pe domeniu (trebuie să fim proprietari verificați în Google Search Console), iapoi ne va permite să îl modificăm și să verificăm dacă subpaginile indicate vor fi blocate sau vor trece de directivele sale.
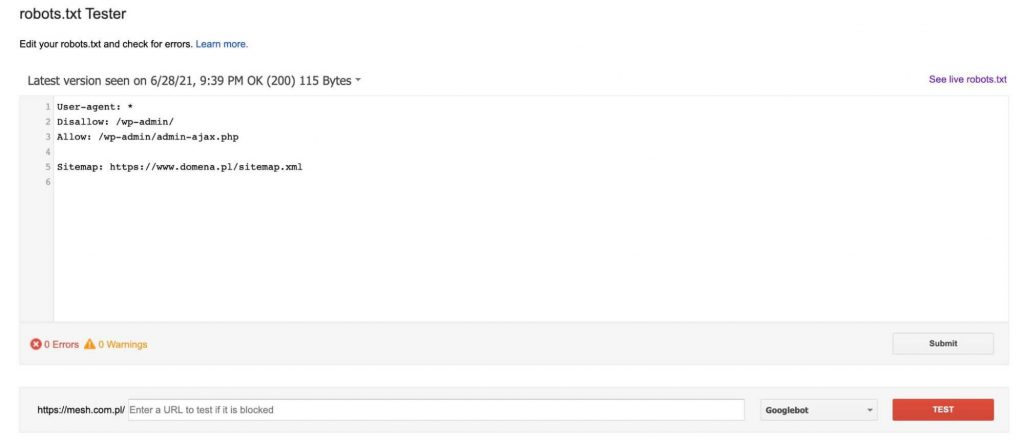
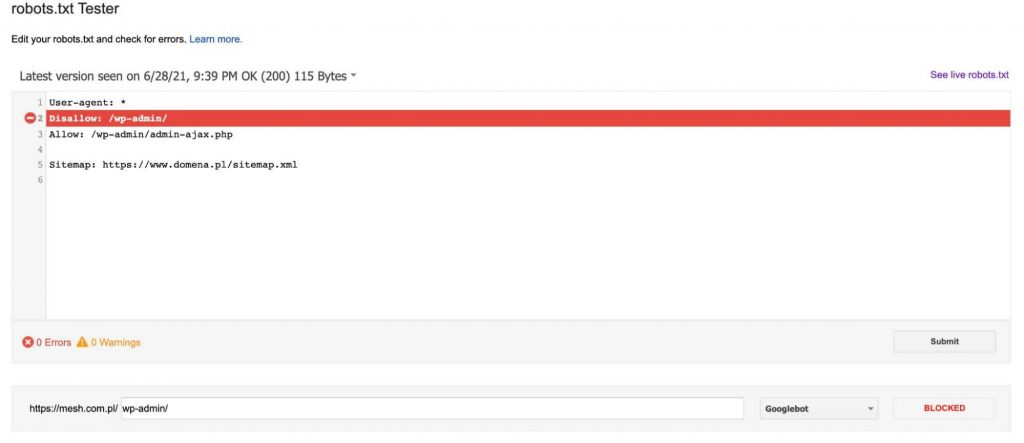
De fiecare data cand adaugam un URL pentru testare (in partea de jos a graficului), facem clic pe butonul rosu „TEST”. Drept raspuns, primim informatii despre daca URL-ul indicat a fost blocat si, daca a fost blocat, ce linie din fisierul robots.txt a cauzat aceasta blocare.
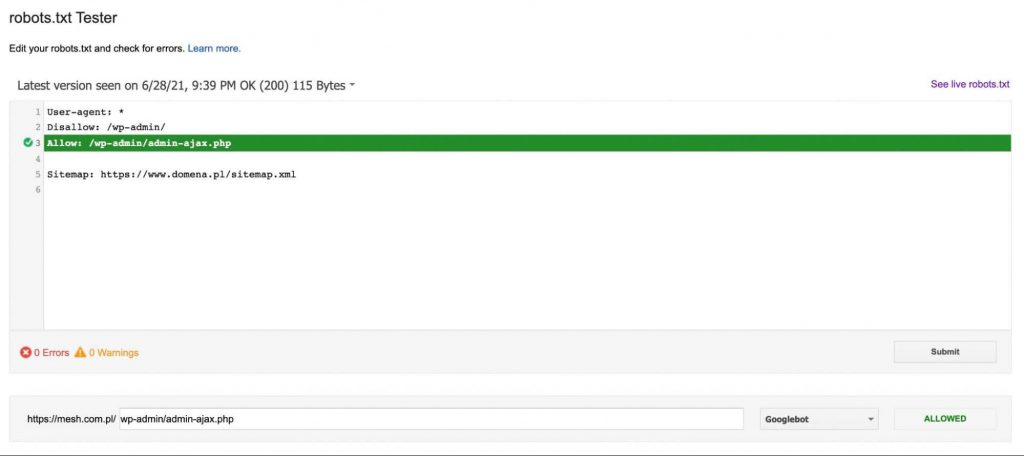
Daca URL-ul nu este blocat, vom primi un mesaj care indica faptul ca URL-ul directivei este accesibil pentru robotul Google, asa cum se vede in graficul de mai jos:
Ce trebuie sa luati in considerare atunci cand creati un fisier robots.txt?
Cand creati un fisier robots.txt, este esential sa aveti grija sa nu blocati accidental accesul robotului Google la site, fie in totalitate, fie partial. Din acest motiv, este recomandat sa consultati un specialist inainte de a face orice modificare acestui fisier pentru a evita potentiale probleme care ar putea afecta negativ site-ul.
Totusi, este important de mentionat ca fisierul robots.txt nu impiedica indexarea site-ului de catre roboți. Google permite ca, daca robotul sau ajunge la una dintre paginile noastre printr-un alt domeniu si acea pagina este considerata valoroasa, aceasta va fi indexata.
De asemenea, trebuie retinut ca majoritatea robotilor care nu apartin Google nu respecta directivele din fisierul robots.txt si ignora instructiunile din acesta.
Rezumat
Fisierul robots.txt este un element esential in SEO tehnic. Daca este completat incorect, exista riscul de a limita traficul provenit din SEO, in timp ce o completare adecvata va ajuta la gestionarea indexarii unui site si a bugetului de cautare. Cu cat volumul de trafic pe site este mai mare si cu cat exista mai multe subpagini pe site-ul nostru, cu atat este mai important sa ne asiguram ca fisierul robots.txt este completat corect.