 Łukasz Rogala
Łukasz Rogala  Csaba Pirosca
Csaba Pirosca Analiza bugetului de crawl este o sarcină esențială pentru orice specialist SEO, în special când gestionează site-uri de dimensiuni mari. Această sarcină importantă este abordată în mod adecvat în materialele oferite de Google. Totuși, după cum se poate observa pe Twitter, chiar și angajați Google subestimează importanța bugetului de crawl în obținerea unui trafic mai mare și a unor clasamente mai bune:
Au dreptate în această privință?
Principalele concluzii
- Bugetul de crawl reprezintă capacitatea Googlebot de a accesa și indexa un site. Aceasta este influențată de popularitatea și frecvența actualizării conținutului site-ului, fiind esențială pentru o optimizare SEO eficientă.
- Optimizarea bugetului de crawl necesită o atenție sporită asupra detaliilor tehnice ale site-ului, cum ar fi performanța serverului, gestionarea erorilor 404 și a redirecționărilor, precum și structura link-urilor interne.
- Analiza bugetului de crawl poate fi realizată cu ajutorul unor instrumente precum Google Search Console și crawlere externe. Senuto Visibility Analysis poate furniza date valoroase despre vizibilitate și trafic organic.
- Eliminarea conținutului duplicat și de slabă calitate este esențială pentru a maximiza eficiența indexării, iar gestionarea corectă a tag-urilor noindex și a directivelor din robots.txt este de asemenea importantă.
- Instrumentele de analiză a bugetului de crawl, precum Screaming Frog SEO Spider, oferă o imagine detaliată asupra performanței crawl-ului și evidențiază aspectele care necesită optimizare.
Cum funcționează și cum colectează datele Google?
Deoarece discutăm despre acest subiect, este important să ne reamintim modul în care motorul de căutare colectează, indexează și organizează informațiile. Reținerea acestor trei pași este esențială pentru optimizarea ulterioară a site-ului:
Etapa 1: Crawling. Aceasta implică explorarea resurselor online pentru a descoperi și naviga printre toate legăturile, fișierele și datele existente. În general, Google începe cu cele mai populare site-uri de pe internet, continuând apoi să scaneze alte resurse mai puțin frecventate.
Etapa 2: Indexarea. În această fază, Google încearcă să înțeleagă conținutul paginii și să determine dacă materialul analizat este unic sau duplicat. În cadrul indexării, Google organizează conținutul și îi atribuie o ordine de importanță, bazându-se pe sugestii precum etichetele rel=”canonical” sau rel=”alternate”.
Etapa 3: Servirea. Odată ce datele sunt segmentate și indexate, acestea sunt prezentate drept răspuns la interogările utilizatorilor. În această etapă, Google sortează și afișează informațiile, luând în considerare factori precum locația utilizatorului.
Important: Mulți neglijează Etapa 4: Randarea conținutului. În mod implicit, Googlebot indexează conținutul text. Totuși, pe măsură ce tehnologiile web evoluează, Google a trebuit să dezvolte soluții pentru a depăși limitările textului și pentru a „vedea” conținutul. Randarea permite Google să își extindă semnificativ capacitatea de indexare, în special pentru site-urile nou lansate.
Notă: Problemele legate de randarea conținutului pot contribui la un buget de crawling deficitar.
Încearcă Senuto Suite gratuit timp de 14 zile
Încearcă gratuit 14 zileCe este bugetul de crawl?
Bugetul de crawl reprezintă frecvența cu care crawlerele și roboții motoarelor de căutare pot accesa și indexa site-ul dumneavoastră, precum și numărul total de URL-uri pe care le pot explora într-o singură sesiune de crawling. Puteți imagina bugetul de crawl ca pe niște credite pe care le utilizați într-un serviciu sau aplicație. Dacă nu luați măsuri pentru a „încărca” acest buget, crawler-ul va încetini și va vizita site-ul mai rar.
În SEO, „încărcarea” bugetului de crawl se referă la activitățile prin care se obțin backlink-uri sau se crește popularitatea generală a site-ului web. Prin urmare, bugetul de crawl este o componentă esențială a întregului ecosistem online. Atunci când îmbunătățiți conținutul și obțineți backlink-uri de calitate, extindeți limita bugetului de crawl disponibil.
Google nu oferă o definiție explicită a bugetului de crawl în resursele sale. În schimb, subliniază două elemente esențiale ale procesului de crawling care influențează frecvența și amploarea vizitelor Googlebot:
- Limita ratei de crawl – determină cât de des și cât de mult poate accesa Googlebot un site.
- Crawl demand – se referă la necesitatea de a scana anumite pagini, în funcție de relevanță și actualitate.
Ce este limita ratei de accesare și cum se verifică?
Limita crawl rate reprezintă numărul de conexiuni simultane pe care Googlebot le poate stabili în timpul explorării site-ului dumneavoastră. Pentru a nu afecta negativ performanța site-ului și experiența utilizatorului, Google limitează acest număr de conexiuni. Cu cât site-ul dumneavoastră este mai lent, cu atât această limită va fi mai mică.
Important: Limita de accesare este influențată și de sănătatea generală a SEO a site-ului. Dacă site-ul are multe redirecționări, erori 404/410 sau dacă serverul returnează frecvent un cod de stare 500, limita de accesare va scădea.
Pentru a verifica și analiza limitele de accesare, puteți utiliza Google Search Console, unde raportul Crawl Stats oferă informații detaliate despre activitatea de crawling a Googlebot pe site-ul dumneavoastră.
Crawl demand, or website popularity
În timp ce limita crawl rate vă obligă să îmbunătățiți aspectele tehnice ale site-ului, crawl demand reflectă popularitatea site-ului dumneavoastră. Cu cât există mai multă activitate și interes în jurul site-ului (și pe site), cu atât cererea pentru crawling va fi mai mare.
Google ia în considerare două aspecte principale:
- Popularitatea generală: Google prioritizează crawlarea frecventă a URL-urilor care sunt populare în mod general pe internet, nu neapărat cele care au cele mai multe backlink-uri.
- Actualitatea datelor din index: Google urmărește să afișeze doar cele mai recente informații. Important: Crearea continuă de conținut nou nu garantează că bugetul global de crawl va crește.
Astfel, popularitatea și actualitatea sunt esențiale pentru a atrage mai multă atenție din partea Googlebot.
Factori care afectează bugetul de crawl
Unelte utile pentru analiza bugetului de crawl
Întrucât nu există un standard de referință pentru bugetul de crawl, ceea ce face dificilă compararea limitelor între diferite site-uri, este esențial să folosiți instrumente special concepute pentru colectarea și analiza datelor.
-
Google Search Console (GSC)
Google Search Console s-a dezvoltat semnificativ în ultimii ani. Pentru analiza bugetului de crawl, sunt două rapoarte principale pe care ar trebui să le examinați: Index Coverage și Crawl Stats.
-
Index Coverage în GSC
Acest raport oferă o cantitate vastă de date. Verificarea URL-urilor excluse de la indexare este o metodă excelentă de a înțelege amploarea problemelor întâmpinate. Acest raport poate dezvălui paginile care nu sunt indexate din diverse motive, ajutându-vă să identificați și să rezolvați problemele legate de indexare.
Folosirea Google Search Console vă va oferi informațiile necesare pentru a optimiza eficient bugetul de crawl al site-ului dumneavoastră.
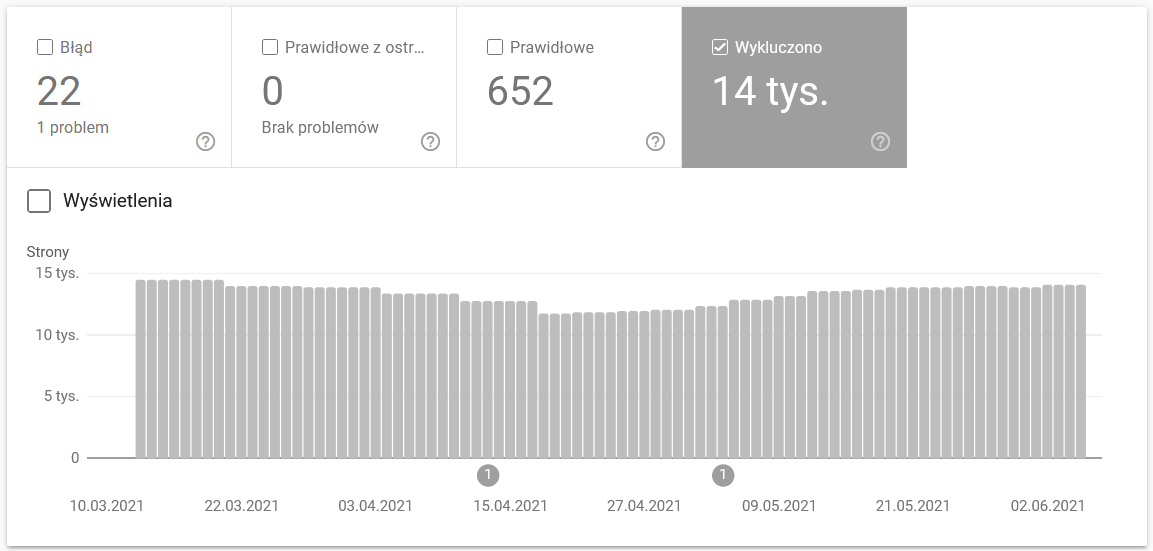
Întregul raport justifică un articol separat, dar pentru moment, să ne concentrăm pe următoarele aspecte importante:
- Exclus de tag-ul ‘noindex’ – În general, un număr mare de pagini cu tag-ul noindex poate conduce la scăderea traficului. Este important să ne întrebăm care este scopul păstrării acestor pagini pe site și cum putem restricționa accesul la ele, dacă nu sunt necesare pentru indexare.
- Crawled – momentan neindexate – Dacă observați acest statut, verificați dacă conținutul este redat corect în ochii Googlebot. Fiecare URL cu acest statut consumă din bugetul de crawl fără a aduce trafic organic, deci este important să rezolvați problemele de redare.
- Descoperit – momentan neindexat – Acesta este unul dintre cele mai îngrijorătoare probleme care ar trebui tratată cu prioritate. Verificați motivele pentru care paginile nu sunt indexate și luați măsuri pentru a le include în indexul Google, dacă sunt relevante.
- Duplicate fără canonicală selectată de utilizator – Pagina duplicată este problematică, deoarece nu doar că afectează bugetul de crawl, dar poate duce și la canibalizarea conținutului. Este important să gestionați paginile duplicate și să stabiliți canonicalele corecte.
- Duplicate, Google a ales un canonical diferit de cel al utilizatorului – Teoretic, Google ar trebui să ia deciziile corecte privind canonicalele. Totuși, în practică, Google poate selecta canonicele într-un mod aleatoriu, adesea afectând paginile valoroase prin redirecționarea lor către pagini de start sau alte pagini de mai mică valoare.
- Soft 404 – Erorile „soft 404” sunt foarte periculoase deoarece pot duce la eliminarea paginilor critice din index. Verificați și corectați aceste erori pentru a preveni pierderea de conținut important.
- Duplicate, URL-ul trimis nu a fost selectat ca fiind canonic – Similar cu paginile duplicate fără canonicale selectate de utilizator, această problemă indică lipsa unei canonică corecte, afectând bugetul de crawl și risipind resursele.
Statistici de accesare
Raportul Google Search Console nu oferă o imagine completă și perfectă a activității de crawling. În plus față de analizele din GSC, vă recomand cu tărie să consultați și jurnalele serverului. Acestea oferă o perspectivă mai detaliată asupra datelor și mai multe opțiuni pentru modelare și interpretare.
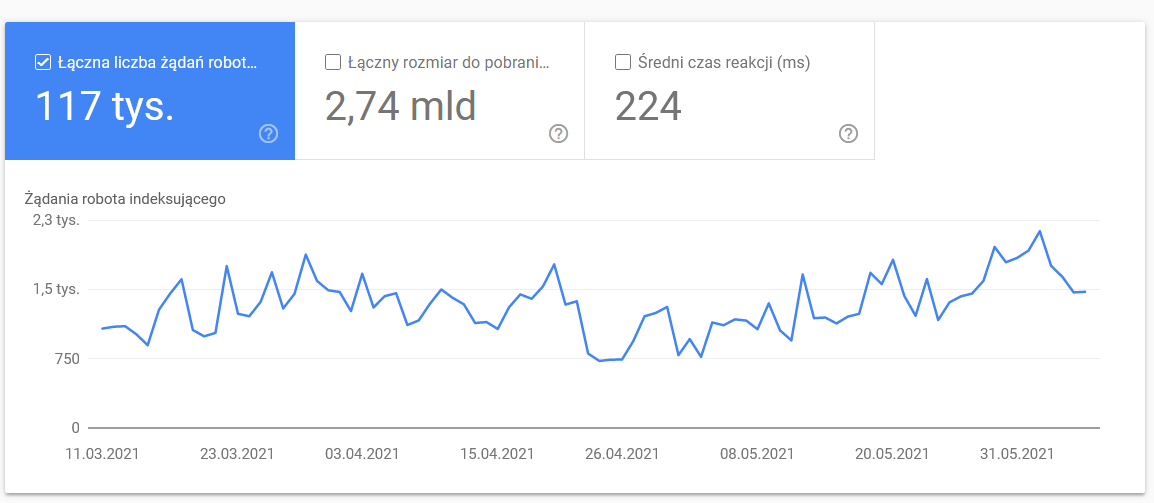
Așa cum am menționat anterior, stabilirea unor puncte de referință precise pentru cifrele prezentate poate fi dificilă. Cu toate acestea, este esențial să analizați atent anumite aspecte:
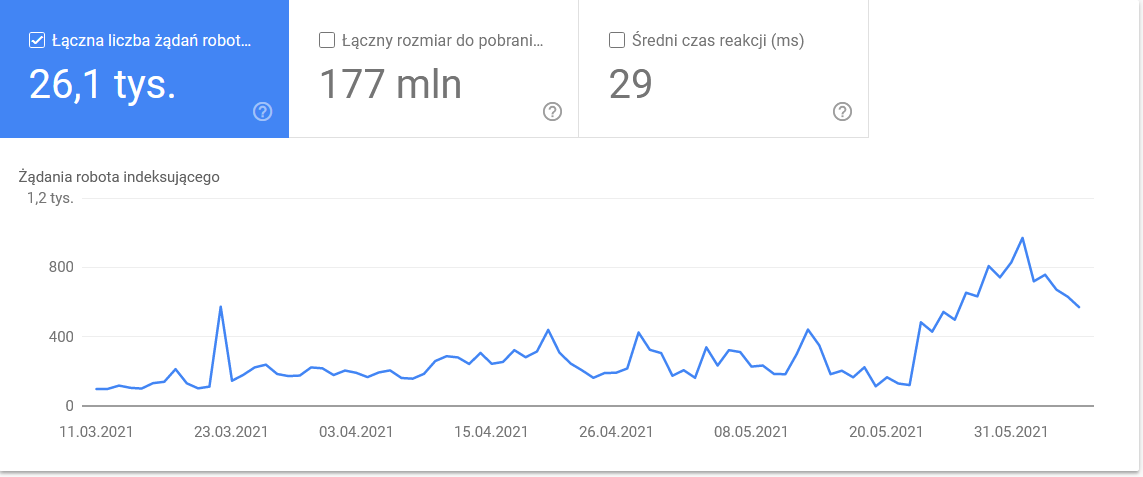
- Timp mediu de descărcare: Captura de ecran de mai jos evidențiază o scădere dramatică a timpului mediu de răspuns, care poate fi atribuită problemelor legate de server. Acest timp de răspuns afectează direct performanța site-ului și eficiența crawling-ului.
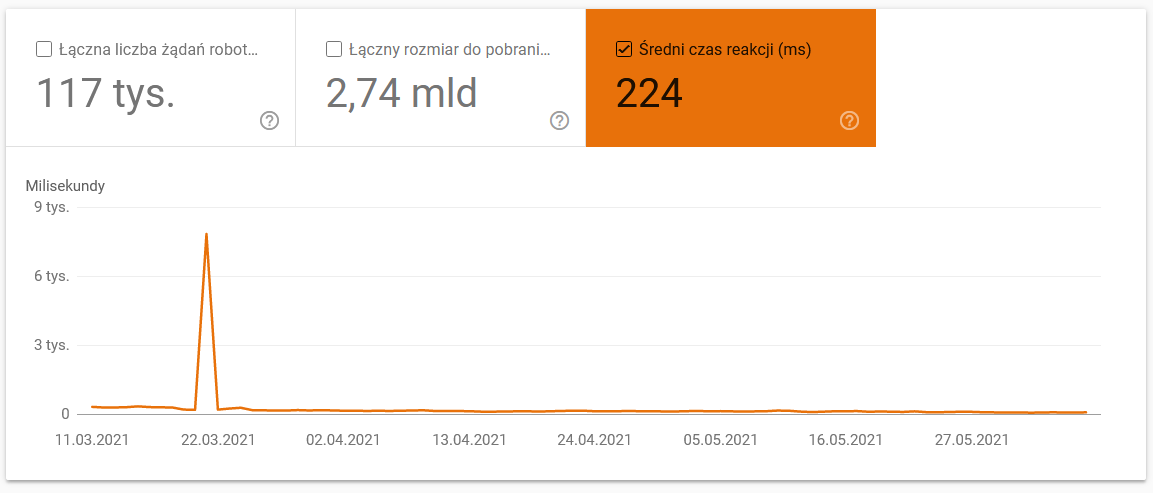
- Răspunsuri crawl. Examinați raportul de crawling pentru a evalua, în general, starea site-ului dumneavoastră. Acordați o atenție specială codurilor de stare neobișnuite ale serverului, cum ar fi codurile 304 menționate mai jos. Aceste URL-uri, care nu aduc niciun beneficiu funcțional, consumă resursele Google pentru a fi parcurse. Identificarea și remedierea acestor probleme pot ajuta la optimizarea eficienței bugetului de crawl.

- Scop de căutare.În general, datele privind scopul de căutare sunt strâns legate de volumul de conținut nou de pe site. Diferențele între informațiile colectate de Google și cele colectate de utilizator pot fi deosebit de interesante. Aceste discrepanțe pot oferi perspective valoroase asupra modului în care Google percepe și prioritizează conținutul comparativ cu utilizatorii reali.
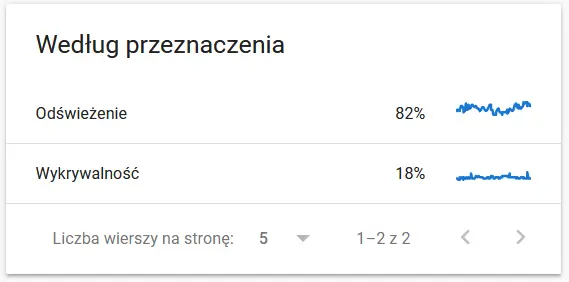
Conținutul unui URL recrawled în ochii Google:
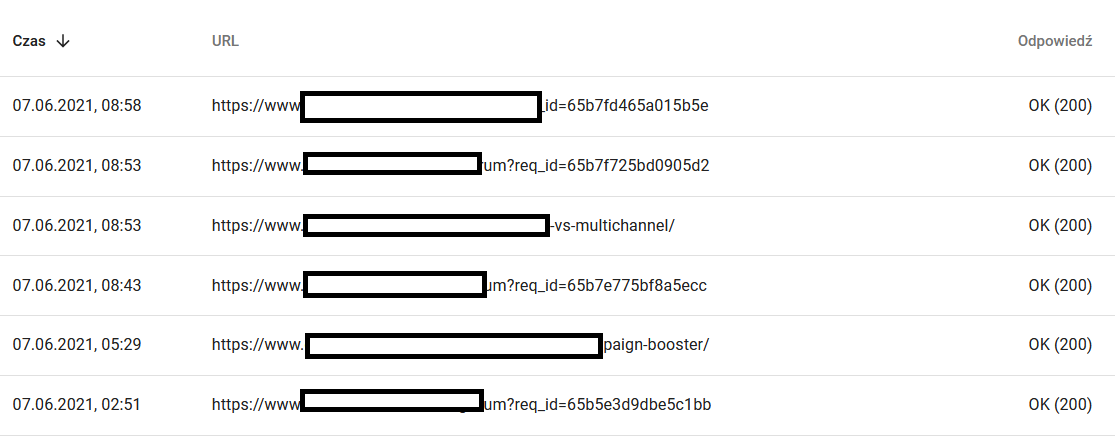
Între timp, iată ce vede utilizatorul în browser:
Cu siguranță un motiv de reflecție și analiză : )
- Tip Googlebot. În această secțiune, aveți la dispoziție informații despre roboții care vizitează site-ul dumneavoastră și scopurile lor în analiza conținutului. Captura de ecran de mai jos ilustrează că 22% din cereri sunt dedicate încărcării resurselor paginii. Această informație poate fi utilă pentru înțelegerea tipurilor de solicitări făcute de Googlebot și pentru optimizarea resurselor site-ului.
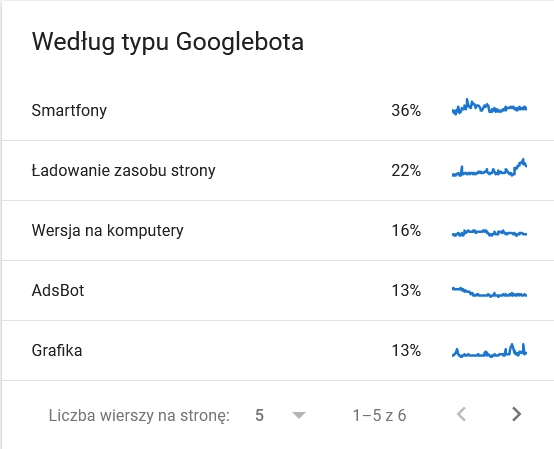
Totalul a explodat în ultimele zile ale intervalului de timp:
O privire asupra detaliilor dezvăluie URL-urile care necesită o atenție sporită:
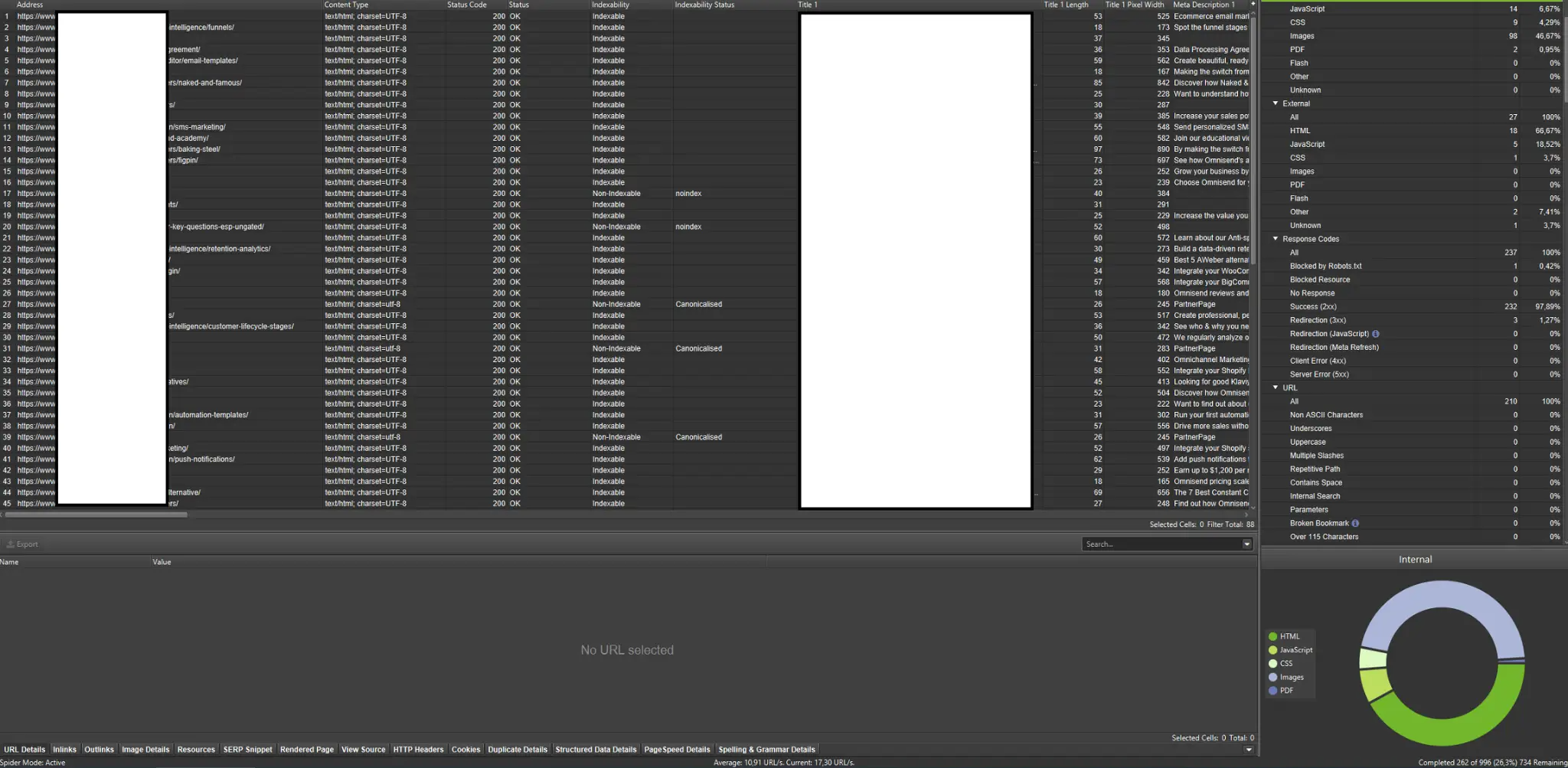
Crawlere externe (cu exemple de la Screaming Frog SEO Spider)
Crawlerele sunt unele dintre cele mai importante instrumente pentru analiza bugetului de crawl al site-ului dumneavoastră. Scopul principal al acestor instrumente este de a imita comportamentul roboților de crawling pe site-ul web. Această simulare vă oferă o viziune de ansamblu asupra funcționării site-ului și ajută la identificarea eventualelor probleme care pot afecta eficiența crawling-ului.
Dacă sunteți o persoană care învață vizual, este important să știți că majoritatea soluțiilor disponibile pe piață oferă vizualizări de date. Aceste vizualizări ajută la înțelegerea și interpretarea mai ușoară a informațiilor, facilitând analiza și optimizarea bugetului de crawl.
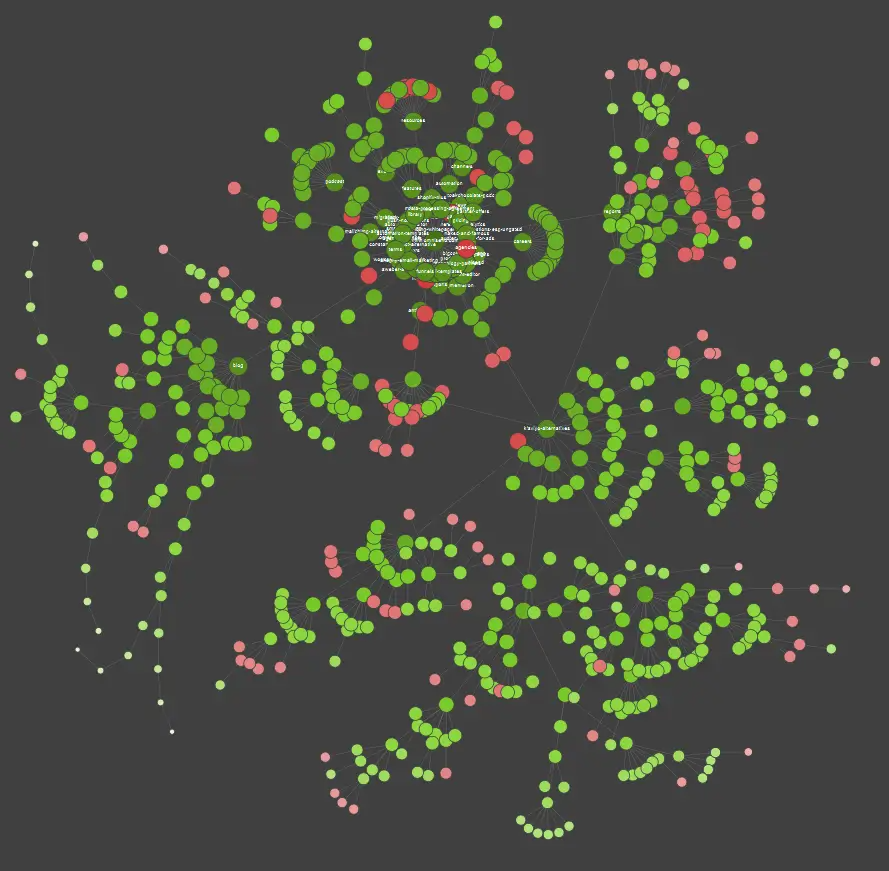
În exemplul de mai sus, punctele roșii indică paginile neindexate. Este esențial să reflectați asupra utilității și impactului acestor pagini asupra funcționării site-ului dumneavoastră. Dacă jurnalele serverului arată că aceste pagini consumă mult timp pentru Google fără a adăuga valoare, ar trebui să reconsiderați serios necesitatea menținerii lor pe site.
Important: Pentru a recrea comportamentul Googlebot cât mai exact posibil, este crucial să aveți setările corecte. Exemplele de setări de pe calculatorul meu sunt prezentate mai jos, pentru a ilustra cum să configurați corect instrumentele de crawling.
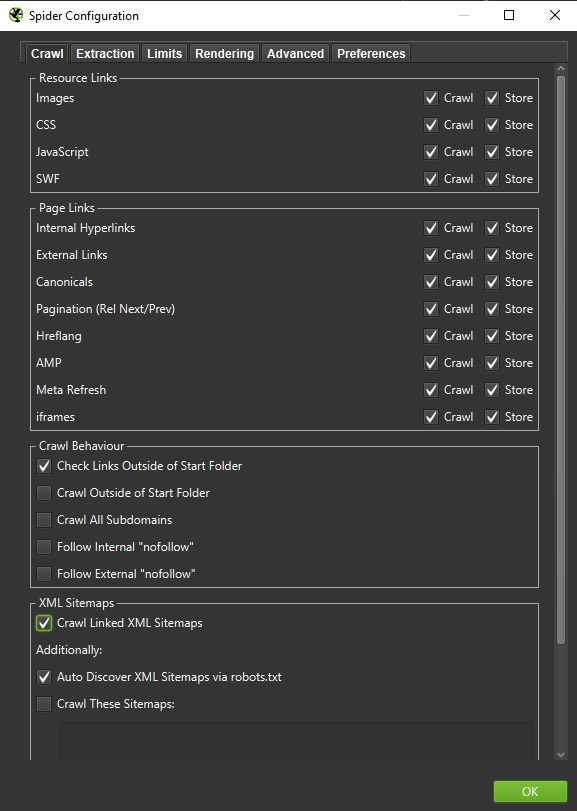
Atunci când efectuați o analiză aprofundată, este recomandat să testați două moduri de crawling: doar text și JavaScript. Compararea rezultatelor obținute prin aceste metode poate evidenția diferențe semnificative, dacă există, și poate oferi o imagine mai completă asupra modului în care site-ul este perceput și indexat de Google.
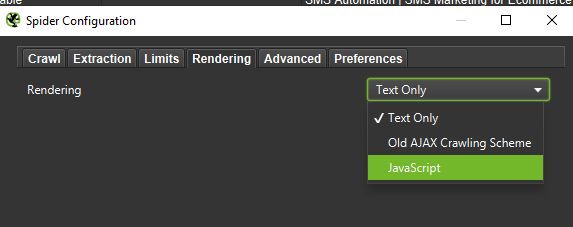
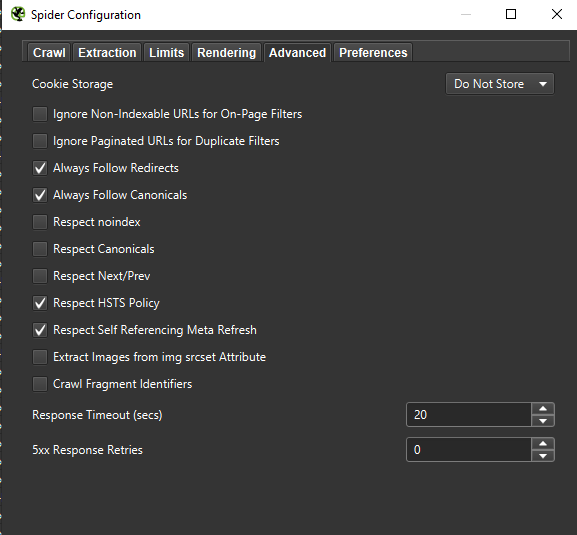
În cele din urmă, nu strică niciodată să testați configurația prezentată mai sus pe doi agenți de utilizator diferiți:
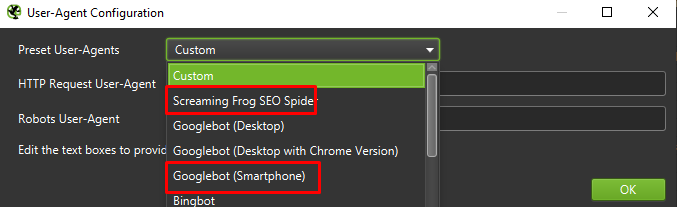
În majoritatea cazurilor, este esențial să vă concentrați pe rezultatele răscolite și redarea efectuată de agentul mobil.
Important: Vă sugerez să profitați de oportunitatea oferită de Screaming Frog și să integrați date din Google Analytics (GA) și Google Search Console. Această integrare permite identificarea rapidă a risipirii bugetului de crawl, inclusiv a unui număr semnificativ de URL-uri potențial redundante care nu generează trafic.
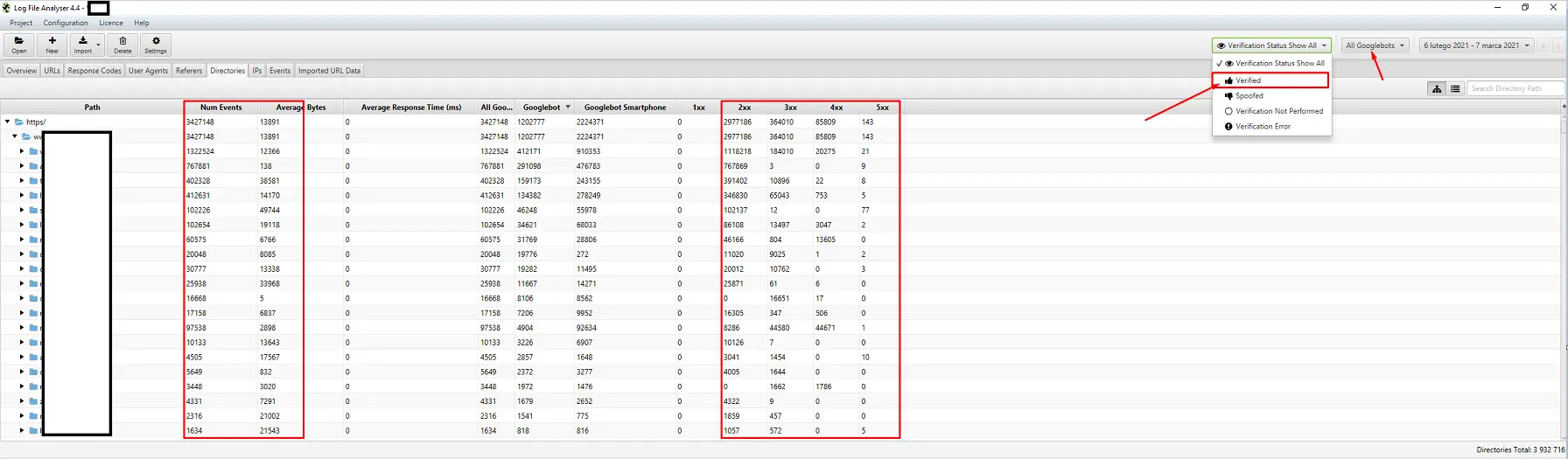
Instrumente pentru analiza jurnalelor (Screaming Frog Logfile și altele)
Alegerea unui analizor de jurnal de server depinde de preferințele personale. Instrumentul meu preferat este Screaming Frog Log File Analyzer. Deși nu este întotdeauna cea mai eficientă soluție (încărcarea unui pachet mare de jurnale poate duce la suspendarea aplicației), apreciez interfața sa. Este esențial să configurați sistemul pentru a afișa doar Googlebots verificați, pentru a obține cele mai relevante informații.
Instrumente pentru urmărirea vizibilității
Instrumentele de urmărire a vizibilității sunt utile pentru identificarea paginilor de top. Dacă o pagină se clasează pe primele locuri pentru multe cuvinte cheie în Google și primește mult trafic, este posibil să aibă o cerere de crawl mai mare. Verificați jurnalele pentru a vedea dacă Google efectuează mai multe accesări pentru această pagină specifică.
Pentru scopurile noastre, vom folosi rapoarte generale în Senuto, cum ar fi „Căi de acces” și „URL-uri”, pentru o analiză continuă. Ambele rapoarte sunt disponibile în Analiza vizibilității, sub fila „Secțiuni”. Aruncați o privire pentru a evalua performanța și cererea de crawl a paginilor.
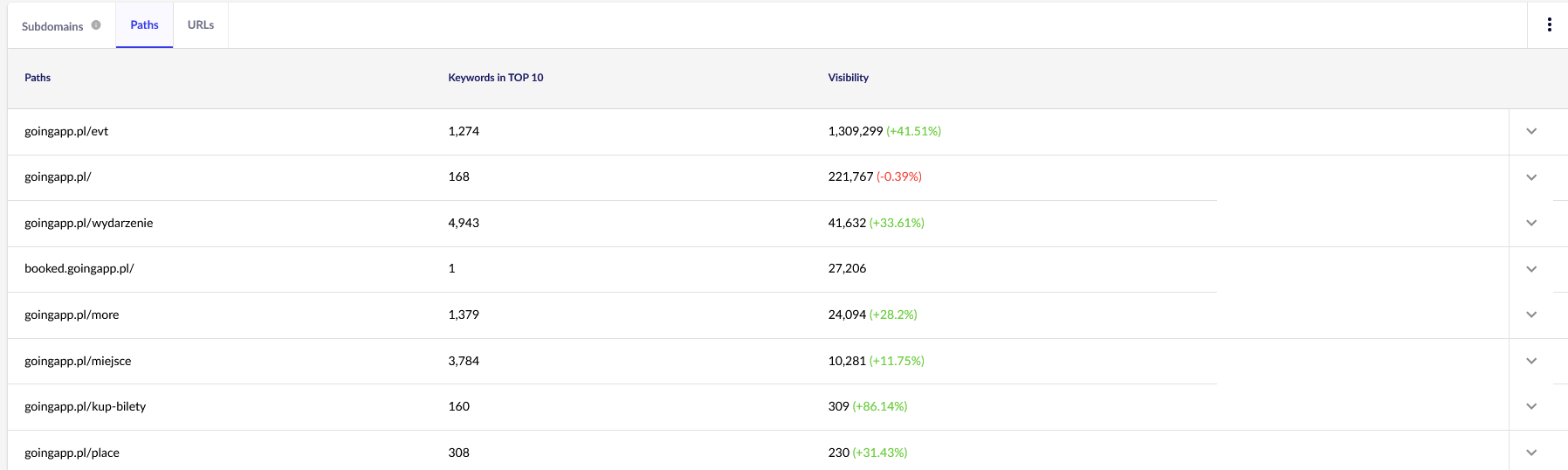
Să sortăm raportul „URL-uri” pentru a examina vizibilitatea cuvintelor cheie, concentrându-ne pe lista și numărul total de cuvinte cheie pentru care site-ul nostru se clasează în TOP 10. Aceste rezultate ne vor ajuta să identificăm axa principală pentru stimularea și alocarea eficientă a bugetului nostru de crawl.
Instrumente pentru analiza backlink-urilor (Ahrefs, Majestic)
Dacă una dintre paginile dumneavoastră beneficiază de un număr mare de linkuri de intrare, aceasta ar trebui să fie un pilon al strategiei de optimizare a bugetului de crawl. Paginile populare pot funcționa ca hub-uri, transferând autoritate (juice) către alte pagini. În plus, paginile populare cu un fond solid de linkuri valoroase au șanse mai mari să atragă crawlere frecvente.
În Ahrefs, folosiți raportul „Pages” și, în mod special, secțiunea „Best by links” pentru a identifica paginile cu cele mai multe linkuri de intrare și a maximiza eficiența alocării bugetului de crawl.
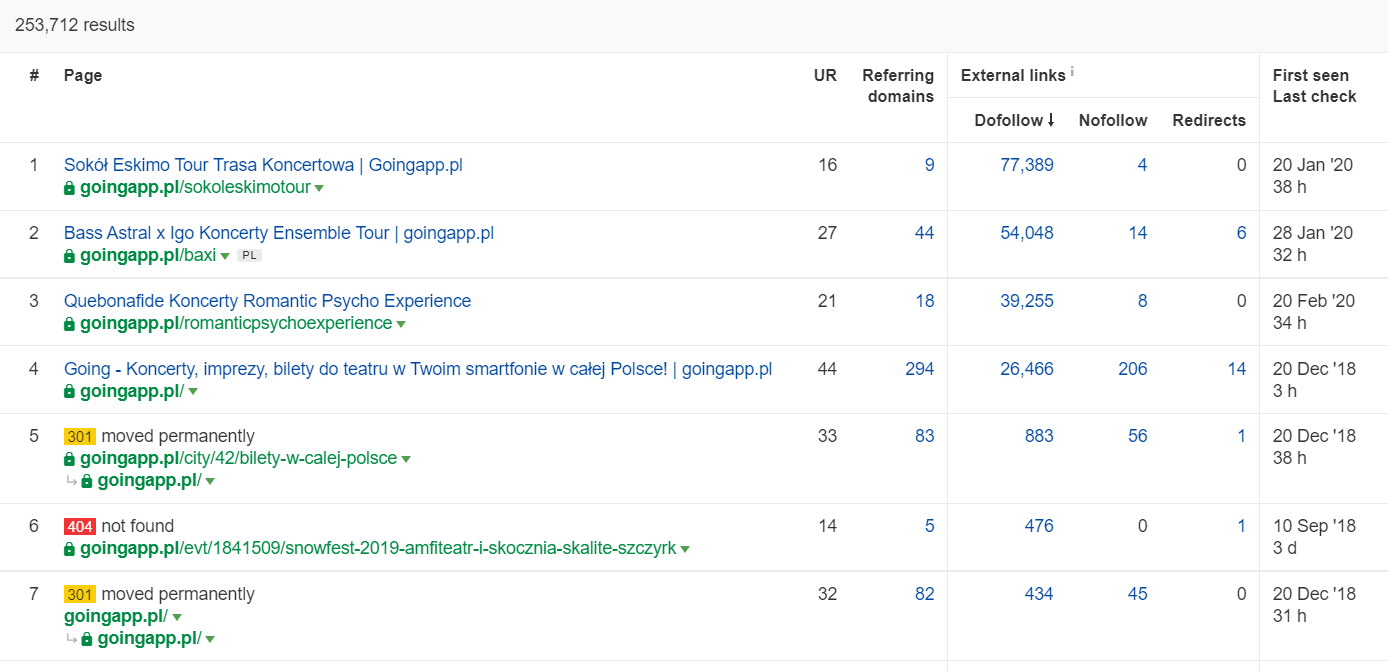
Exemplul de mai sus ilustrează că anumite pagini legate de concerte continuă să genereze statistici solide pentru backlink-uri. Chiar și în contextul anulării concertelor din cauza pandemiei, este în continuare benefic să folosești pagini cu o istorie solidă pentru a atrage atenția roboților de crawling și a răspândi autoritatea în colțurile mai adânci ale site-ului dumneavoastră.
Semne revelatoare ale unei probleme de buget de crawling
Identificarea unui buget de crawl problematic (excesiv de scăzut) poate fi dificilă din cauza complexității SEO. Clasamentele scăzute sau problemele de indexare pot fi cauzate de un profil de linkuri slab sau lipsa de conținut adecvat.
Pentru diagnosticare, verificați următoarele aspecte:
- Timpul de la publicare până la indexare: Cât timp durează pentru ca noile pagini (articole de blog, produse) să fie indexate, presupunând că nu solicitați indexarea prin Google Search Console?
- Durata de păstrare a URL-urilor invalide în index: Cât timp păstrează Google URL-urile invalide în index? Notați că adresele redirecționate sunt o excepție, deoarece Google le stochează intenționat.
- Pagini care dispar din index: Aveți pagini care sunt indexate doar pentru a dispărea ulterior?
- Timpul petrecut pe paginile fără valoare: Cât timp petrece Google pe paginile care nu generează trafic? Analizați jurnalele pentru a afla acest lucru.
Cum să analizăm și să optimizăm bugetul de crawl
Decizia de a optimiza bugetul de crawl depinde în principal de dimensiunea site-ului dumneavoastră. Google sugerează că site-urile cu mai puțin de 1000 de pagini nu ar trebui să se concentreze excesiv pe maximizarea limitelor de crawl disponibile. În opinia mea, ar trebui să vizați o optimizare eficientă a crawl-ului dacă site-ul dumneavoastră are mai mult de 300 de pagini și conținutul se schimbă frecvent (de exemplu, adăugați constant pagini noi sau articole de blog).
Motivul este simplu: este o chestiune de igienă SEO. Implementând bune practici și gestionând eficient bugetul de crawl de la început, veți avea mai puțin de corectat și reproiectat în viitor.
Optimizarea bugetului de crawl: Procedura standard
În general, activitatea de analiză și optimizare a bugetului craw constă în trei etape:
Colectarea datelor pentru un audit al bugetului de crawl
1. Crawl complet al site-ului web: Realizați două tipuri de crawl-uri:
- Un crawl cu simularea Googlebot: Acest crawl trebuie să imite comportamentul Googlebot pentru a evalua cum indexează Google site-ul dvs.
- Un crawl cu agentul utilizator implicit: Acesta simulează accesul unui browser obișnuit.
Obiectivul principal este să descărcați 100% din conținutul site-ului. Dacă observați că procesul de crawl intră într-o buclă (de exemplu, după o zi, crawlerul a indexat doar 10% din site), este un semn că există o problemă și ar trebui să opriți crawl-ul. Pentru site-uri mari, un număr rezonabil de URL-uri pentru analiză este de aproximativ 250-300 de mii de pagini.
a) Criterii de căutare: Concentrați-vă pe identificarea următoarelor aspecte:
- Redirecționări interne 301: Verificați dacă există redirecționări nejustificate care pot afecta bugetul de crawl.
- Erori 404: Identificați paginile care nu sunt găsite și care pot împiedica crawl-ul eficient.
- Conținut subțire: Căutați paginile cu un raport text/HTML foarte mic, care pot fi considerate de Google ca având valoare scăzută.
Screaming Frog oferă opțiunea de a detecta conținutul aproape duplicat, ceea ce poate fi util în această etapă.
2. Crawl complet al site-ului web: Realizați două tipuri de crawl-uri:
- Un crawl cu simularea Googlebot: Simulează comportamentul Googlebot pentru a evalua cum indexează Google site-ul dvs.
- Un crawl cu agentul utilizator implicit: Simulează accesul unui browser obișnuit.
Obiectivul principal este să descărcați 100% din conținutul site-ului. Dacă observați că procesul de crawl intră într-o buclă (de exemplu, după o zi, crawlerul a indexat doar 10% din site), este un semn că există o problemă și ar trebui să opriți crawl-ul. Pentru site-uri mari, un număr rezonabil de URL-uri pentru analiză este de aproximativ 250-300 de mii de pagini.
a) Criterii de căutare: Concentrați-vă pe identificarea următoarelor aspecte:
- Redirecționări interne 301: Verificați dacă există redirecționări nejustificate care pot afecta bugetul de crawl.
- Erori 404: Identificați paginile care nu sunt găsite și care pot împiedica crawl-ul eficient.
- Conținut subțire: Căutați paginile cu un raport text/HTML foarte mic, care pot fi considerate de Google ca având valoare scăzută.
Screaming Frog oferă opțiunea de a detecta conținutul aproape duplicat, ceea ce poate fi util în această etapă.
3. Jurnalele serverului: Ideal, analizați jurnalele serverului pentru ultima lună. În cazul site-urilor mari, ultimele două săptămâni pot fi suficiente. Accesul la jurnalele istorice ale serverului poate fi de asemenea util pentru a compara mișcările Googlebot în perioade mai favorabile.
4. Exporturi de date din Google Search Console: Folosiți datele din rapoartele Index Coverage și Crawl Stats pentru a obține o descriere detaliată a activității de crawling pe site-ul dvs.
5. Date despre traficul organic: Analizați paginile de top folosind Google Search Console, Google Analytics, Senuto și Ahrefs. Identificați paginile cu vizibilitate ridicată, volum mare de trafic sau număr mare de backlink-uri. Aceste pagini ar trebui să fie prioritare în optimizarea bugetului de crawl.
6. Revizuirea manuală a indexului: Utilizați combinația de operatori inurl: + site: pentru a verifica indexarea paginilor și pentru a obține o imagine clară a modului în care Google vede site-ul dvs.
Fuzionarea datelor colectate: Integrați toate datele din crawlere externe, jurnalele serverului, Google Search Console și datele de trafic organic. Folosiți un crawler extern care permite importul de date pentru a obține o imagine de ansamblu completă și a dezvolta strategii de optimizare.`
Analiza vizibilității și identificarea paginilor importante
Deși acest proces merită un articol dedicat, scopul nostru de astăzi este să obținem o imagine de ansamblu asupra obiectivelor și progreselor site-ului nostru web. Ne concentrăm pe aspectele neobișnuite, cum ar fi scăderile bruște de trafic care nu pot fi explicate prin tendințe sezoniere, precum și schimbările concomitente în vizibilitatea organică. Este esențial să identificăm grupurile de pagini cele mai performante, deoarece acestea vor deveni punctele noastre de plecare pentru a dirija Googlebot mai adânc în site-ul nostru.
Ideal, o astfel de analiză ar acoperi întregul istoric al site-ului nostru, începând de la lansare. Cu toate acestea, având în vedere creșterea continuă a volumului de date, ne vom concentra pe analiza vizibilității și a traficului organic din ultimele 12 luni.
Recomandări pentru optimizarea bugetului de crawling
Activitățile menționate mai sus variază în funcție de dimensiunea site-ului web, dar ele reprezintă aspectele fundamentale pe care le iau întotdeauna în considerare atunci când analizez bugetul de crawling. Scopul principal este de a elimina blocajele de pe site-ul dvs., asigurând astfel o crawlabilitate maximă pentru Googlebot sau alți agenți de indexare.
1. Începem prin abordarea elementelor de bază: eliminarea tuturor erorilor 404/410, analiza redirecționărilor interne și îndepărtarea acestora din link-urile interne. Finalizăm cu un crawl de verificare pentru a ne asigura că toate legăturile returnează un cod de răspuns 200, fără redirecționări interne sau erori 404.
- În această etapă, este recomandat să corectăm și lanțurile de redirecționare identificate în raportul de backlink-uri.
2. După finalizarea crawl-ului, asigurați-vă că structura site-ului este lipsită de duplicate evidente.
- Verificați și eventualele probleme de canibalizare a cuvintelor cheie. Canibalizarea poate afecta negativ întregul buget de crawling, nu doar prin crearea unei competiții între paginile care vizează același cuvânt cheie, dar și prin impactul său asupra eficienței crawling-ului.
- Consolidați duplicatele identificate într-un singur URL, de obicei, cel care are o clasare mai bună.
3. Analizați câte URL-uri sunt marcate cu eticheta noindex. Deși Google poate naviga aceste pagini, ele nu apar în rezultatele căutării. Este important să minimizăm numărul de pagini cu eticheta noindex din structura site-ului nostru.
- De exemplu, un blog poate organiza structura cu etichete care, deși sunt utile pentru utilizatori, pot fi etichetate și neindexate. Analiza logurilor poate arăta că aceste etichete sunt printre cele mai accesate structuri de pe site.
4. Verificați fișierul robots.txt. Implementarea acestuia nu garantează că Google nu va indexa adresele respective.
- Examenați care dintre structurile de adrese blocate sunt încă accesate și verificați dacă eliminarea acestora provoacă blocaje. Îndepărtați directivele învechite sau nefolositoare.
5. Analizați volumul de URL-uri necanonice de pe site-ul dvs. Google nu consideră atributul rel=”canonical” ca fiind o directivă strictă în multe cazuri, iar acest atribut poate fi ignorat de motorul de căutare. În special, parametrii de sortare pot reprezenta un coșmar.
6. Examinați filtrele și funcționalitatea acestora. Filtrarea listărilor este o problemă majoră în optimizarea bugetului de crawling. Proprietarii de site-uri de comerț electronic insista adesea să implementeze filtre aplicabile în combinații variate (de exemplu, filtrare după culoare, material, mărime, disponibilitate). Aceasta nu este o soluție optimă și ar trebui limitată la minimum.
7. Arhitectura informațională a site-ului web ar trebui să reflecte obiectivele de afaceri, potențialul de trafic și profilul de linkuri actual. Ideal, un link către conținutul esențial pentru obiectivele afacerii ar trebui să fie vizibil la nivelul întregului site sau pe pagina principală. Pagina de start și meniul de sus sau linkurile de nivel superior sunt cei mai importanți indicatori în construirea valorii din linkurile interne. În același timp, trebuie să ne asigurăm de o răspândire optimă a domeniului, astfel încât fiecare pagină să fie accesibilă de la orice altă pagină.
- Dezvoltarea unei arhitecturi de informații robuste este crucială pentru optimizarea bugetului de crawling. Aceasta ne permite să alocăm resursele bot-ului într-un mod mai eficient. Totuși, implementarea acesteia poate fi o provocare, deoarece necesită cooperarea părților interesate, ceea ce poate duce la dezbateri intense și critici care subminează recomandările SEO.
8. Redarea conținutului este esențială pentru site-urile care se bazează pe sisteme de recomandare ce captează comportamentul utilizatorilor. Majoritatea acestor instrumente se bazează pe fișiere cookie, pe care Google nu le stochează, ceea ce poate duce la vizualizarea aceleași versiuni de conținut sau la lipsa de conținut vizibil.
- Este o greșeală frecventă să blochezi accesul Googlebot-ului la conținutul JS/CSS critic, ceea ce poate cauza probleme cu indexarea paginilor.
9. Performanța site-ului web – Core Web Vitals. Deși sunt sceptic în privința impactului Core Web Vitals asupra clasamentului site-ului din cauza diversității dispozitivelor și a variabilității vitezei de conectare la internet, este un parametru important care merită să fie discutat cu un programator.
10. Sitemap.xml – Verificați funcționalitatea sitemap.xml pentru a vă asigura că include toate elementele cheie și nu conține decât URL-uri canonice care returnează un cod de stare 200.
- Recomandarea mea pentru optimizarea sitemap.xml este să împărțiți paginile în funcție de tip sau, atunci când este posibil, de categorie. Acest lucru vă va oferi un control mai bun asupra mișcărilor și indexării conținutului de către Google.