 Damian Sałkowski
Damian Sałkowski W odpowiedzi na nominację agencji SEO4.net, aby przeprowadzić audyt SEO wybranej strony użytku publicznego, przystąpiliśmy do wyzwania, biorąc pod lupę stronę ZUS-u.
Dokument ten nie został przygotowany na zlecenie ZUS-u. Jest to przykładowy audyt SEO zrealizowany na potrzeby edukacyjne. Audyt przeprowadzony był również live w ramach otwartego webinaru Senuto z serii SEO Lunch. Nagranie znajduje się poniżej:
Omawiając poszczególne problemy witryny, oznaczyliśmy ich priorytet (pilne, średnio pilne, mało pilne) oraz dodaliśmy komentarze wyjaśniające. Najlepiej uczyć się w praktyce, więc zaczynamy!
Uwaga! Niniejszy wpis to jedynie fragment całego audytu. Jeśli chcesz pobrać pełen dokument, zjedź na dół strony.
Wykorzystane narzędzia
Podczas przeprowadzania audytu zostały wykorzystane następujące narzędzia:
- Senuto
- Narzędzia Enterprise Senuto (Content Planner) – kontakt: [email protected]
- Screaming Frog
- Web Developer (wtyczka do chrome)
- Web Archive
- Ahrefs
- Similarweb
- Narzędzie do testowania danych strukturalnych
- Lighthouse
- Narzędzie do testowania dostosowania do urządzeń mobilnych
- Narzędzie do badania duplikacji treści
Narzędzia, które warto wykorzystać dodatkowo (w przypadku tego audytu nie było do nich dostępu lub nie było potrzeby ich używania):
- Google Analytics
- Google Search Console
- Trello
Obecna widoczność w wyszukiwarce
Komentarz:
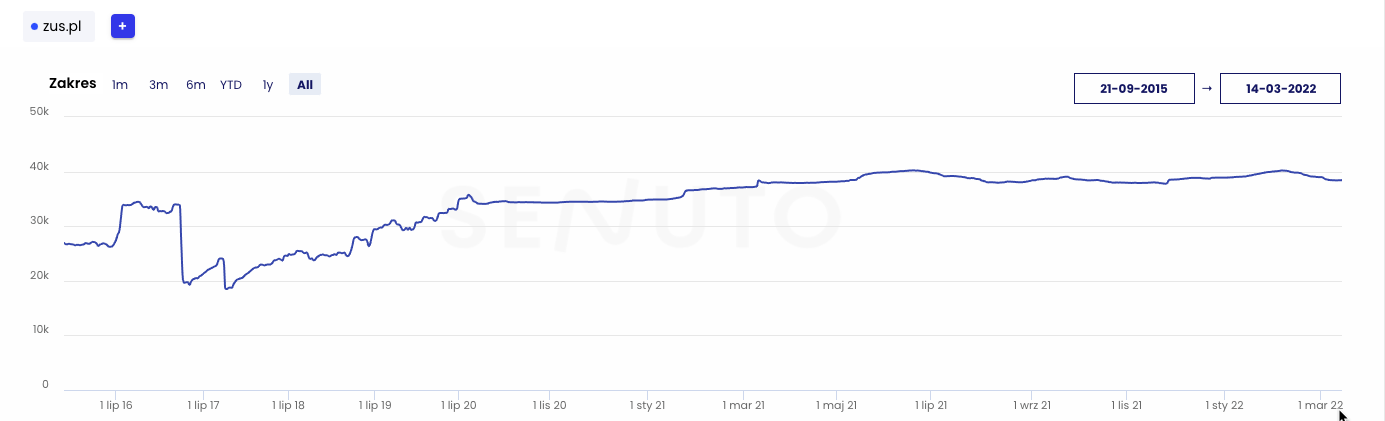
W tej sekcji audytu chodzi o to, aby pokazać obecną sytuację klienta, wyrażoną poprzez ruch z wyszukiwarki. Dzięki temu w przyszłości łatwo będzie się odnieść do okresu sprzed audytu. W tym celu warto wykorzystać:
- Google Analytics
- Google Search Console
- Senuto
Obecna i historyczna widoczność
- 25 700 fraz kluczowych w TOP 3 wyników wyszukiwania
- 38 500 fraz kluczowych w TOP 10 wyników wyszukiwania
- 146 900 fraz kluczowych w TOP 50 wyników wyszukiwania
Estymowany ruch z wyników wyszukiwania wynosi 1,06 mln wizyt miesięcznie. Pod kątem widoczności witryna zajmuje w Polsce 22. miejsce w kategorii “finanse osobiste”.
Warto zwrócić uwagę na spadek widoczności w 2017 roku. Witryna straciła w tamtym okresie aż 57% swojej widoczności. Za pomocą narzędzia Web Archive sprawdziliśmy, że wtedy miała miejsce zmiana serwisu na nową wersję.
Spadek widoczności spowodowany był błędną migracją na nową wersję serwisu (brak przekierowań na nowe adresy). W przyszłości przed istotnymi zmianami w serwisie należy te błędy wykluczyć.
Komentarz:
Na wykresie widoczności Senuto można także sprawdzić, czy przy którejś z aktualizacji algorytmu Google witryna nie otrzymała kary. Jeśli była to kara ręczna, komunikat będzie widoczny również w Google Search Console (teraz zdarza się to wyjątkowo rzadko). W tym przypadku nie mamy dostępu do GSC.
Wykres widoczności wskazuje, że witryna nie straciła ruchu na żadnej aktualizacji algorytmu wyszukiwarki Google.
Widoczność konkurencji
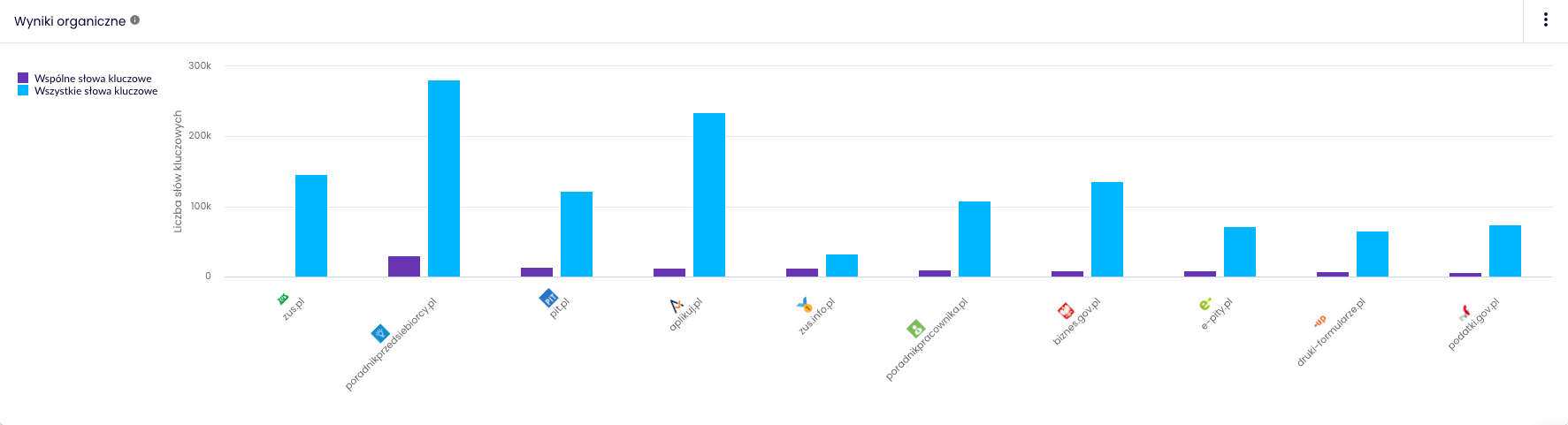
Główną konkurencją witryny ZUS.pl w wynikach wyszukiwania jest:
- poradnikprzedsiebiorcy.pl – 20 167 wspólnych fraz kluczowych
- pit.pl – 8 898 wspólnych fraz kluczowych
- biznes.gov.pl – 7 185 wspólnych fraz kluczowych
Komentarz:
Zus.pl nie ma konkurencji “biznesowej”, w związku z czym jako konkurencję traktujemy serwisy, które dostarczają wiedzę w zakresie praw i obowiązków przedsiębiorców i obywateli. Gdybyśmy robili audyt dla działalności biznesowej, moglibyśmy rozwinąć tę sekcję, gdyż klient najpewniej aspirowałby do tego, aby dogonić/wyprzedzić swoją konkurencję.
Znaczniki meta
Komentarz:
W tej sekcji sprawdzamy takie podstawowe elementy jak:
- znaczniki meta description,
- znaczniki meta title.
Sprawdzamy, czy występują, czy są odpowiednio zbudowane i czy nie duplikują się pomiędzy poszczególnymi podstronami.
Meta description (średnio pilne)
Znacznik meta description to element niewidoczny dla użytkownika serwisu. Jest on jednak widoczny w wyszukiwarce.
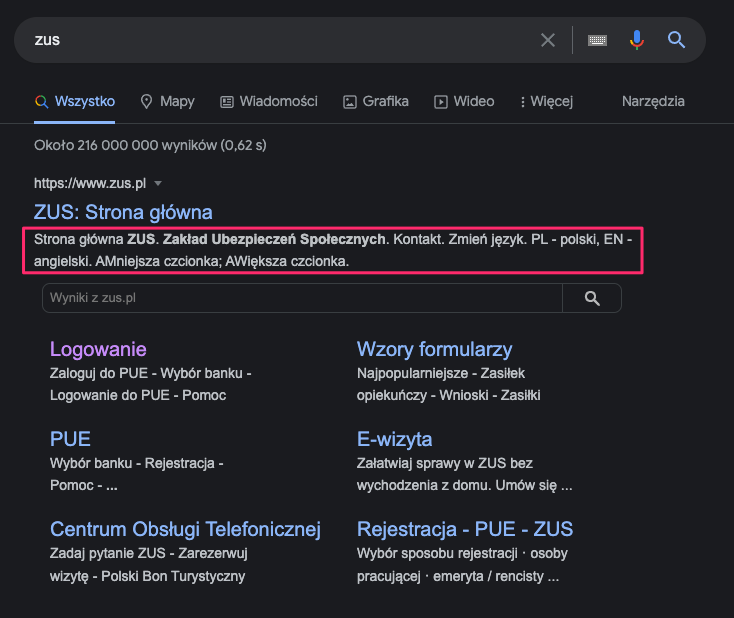
- Znaczniki meta description powinny spełniać następujące wymagania:
- być unikalne pomiędzy podstronami,
- mieć około 156 znaków,
- zachęcać do wejścia na stronę.
Problem
W przypadku witryny ZUS.pl znaczniki meta description nie istnieją. W takiej sytuacji wyszukiwarka Google generuje je sama na podstawie treści strony. Jak widać na załączonym wyżej zrzucie ekranu, nie robi tego zbyt udolnie.
Rozwiązanie problemu
W sekcji <head> serwisu każdej podstrony należy dodać opis meta description.
<meta name="description" content="This is an example of a meta description.This will often show up in search results.">
Dla najważniejszych podstron w serwisie należy utworzyć go ręcznie; dla pozostałych może być to część treści bądź znacznik utworzony wedle wybranego schematu.
Indeksacja
Komentarz:
Podstawowym elementem dobrego SEO jest zapewnienie robotom wyszukiwarki odpowiedniej dostępności witryny. W ramach tej sekcji audytu sprawdzamy, czy wyszukiwarka poprawnie indeksuje serwis i czy w odpowiedni sposób to kontrolujemy.
Mapa witryny
Komentarz:
Jednym z podstawowych elementów w kontekście indeksacji serwisu jest mapa witryny w formacie XML. Co prawda robot wyszukiwarki nie potrzebuje mapy witryny, aby ją poprawnie indeksować, ale w przypadku dużych serwisów jest to dość istotny element. Witryna ZUS.pl jest dość duża.
W każdym z punktów audytu określamy priorytet. W tym przypadku mapa witryny i błędy z nią związane mają średni priorytet. Dokumentacja Google związana z mapami XML znajduje się tutaj.
W tym przypadku nie mogliśmy skorzystać z raportów Google Search Console, gdzie między innymi można zidentyfikować błędy w sitemapie.
Linki do nieistniejących adresów URL w sitemapie (Pilne)
Problem
W sitemapie znajdują się linki do nieistniejących adresów URL.

Dla każdego linku, niezależnie czy on istnieje, generowana jest wersja językowa ru/en oraz kilka innych.
Link taki jak: https://www.zus.pl/ru/firmy przekierowuje poprawnie na wersję /pl strony (przekierowanie 301).
Rozwiązanie
Należy usunąć z sitemapy linki, które w rzeczywistości nie istnieją.
Brak wszystkich podstron w sitemapie (Pilne)
Komentarz:
Gdybyśmy mieli tu dostęp do GSC, moglibyśmy sprawdzić liczbę linków, które znajdują się w sitemapie. W tym przypadku pobraliśmy mapę do Excela i w ten sposób wykonywaliśmy analizę.
Problem
Strona ZUS.pl według wykonanego crawlu ma 66 642 podstron.
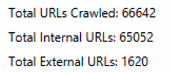
W mapie strony (licząc błędne linki) ujętych jest tylko 6 264 podstron.
Rozwiązanie
Należy umieścić w sitemapie wszystkie podstrony, które powinny być indeksowane przez roboty wyszukiwarek. Jako, że mapa strony docelowo może osiągnąć rozmiar powyżej 50 tysięcy linków, należy utworzyć indeks map witryn i stworzyć dwie mapy.
Dokumentację dotyczącą indeksów map witryn znajdziesz tutaj.
Dodatkowo w pliku robots.txt należy podmienić link – zamiast linku do mapy witryny należy umieścić tam link do indeksu map witryn.
Komentarz:
Kiedy mapy witryny zostaną poprawione, należy je ponownie dodać w narzędziu Google Search Console. W tym przypadku z uwagi na brak dostępu do tego narzędzia nie sugerujemy tego.
Dostęp do poszczególnych podstron
Komentarz:
W tym punkcie skupiamy się na tym, czy witryna nie indeksuje podstron, których nie powinna. Niekiedy zdarza się, że witryny indeksują parametry, filtry, wyniki wyszukiwania i inne podstrony, które powinny zostać oznaczone parametrem noindex.
Indeksowanie słownika (średnio pilne)
Problem
Obecnie serwis umożliwia indeksowanie liter w słowniku pojęć.
Przykłady:
- https://www.zus.pl/slownik/-/letter/B
- https://www.zus.pl/slownik/-/letter/C
Podstrony te nie powinny znajdować się w indeksie z uwagi na fakt, że serwis nie aspiruje do pojawiania się wysoko na frazy takie jak “B” czy “C”. W zakresie indeksacji powinniśmy dbać o to, aby w indeksie były tylko jakościowe podstrony.
Rozwiązanie
W sekcji <head> tych podstron należy umieścić dyrektywę dla robotów.
<meta name="robots" content="noindex" />
Dyrektywa ta spowoduje, że roboty nie będą indeksować tych podstron, ale nadal będą śledzić linki, które się na nich znajdują.
Więcej informacji na temat wspomnianej dyrektywy znajdziesz tutaj.
Indeksowanie wyników wyszukiwania (średnio pilne)
Komentarz:
W zdecydowanej większości przypadków indeksowanie wyników wyszukiwania z wyszukiwarki wewnętrznej serwisu nie jest dobrym pomysłem.
Warto jednak wiedzieć, że istnieją przypadki, kiedy można je z powodzeniem wykorzystać. Jako przykład niech posłuży serwis allegro.pl, którego wewnętrzne wyniki wyszukiwania widoczne są w Google na 2 miliony fraz kluczowych. W przypadku allegro.pl jest to jednak proces zaplanowany i kontrolowany.
W przypadku witryny ZUS.pl indeksowanie wyników wyszukiwania nie ma żadnego sensu. Pomimo tego, że wyniki wyszukiwania nie mają zablokowanego indeksowania, to nie zawsze znajdują się w indeksie wyszukiwarki. Aby to sprawdzić, należy posłużyć się operatorem zaawansowanym w wynikach wyszukiwania.
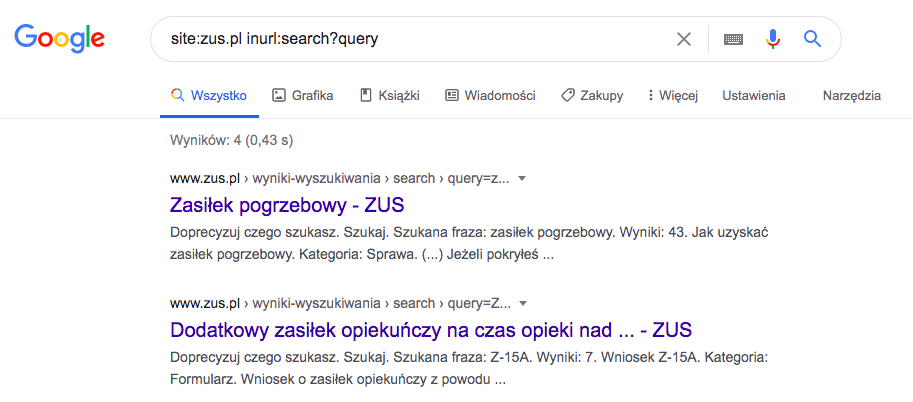
Site:ZUS.pl oznacza, że szukamy tylko w witrynie ZUS.pl, a inurl:search?query to parametr, który pojawia się zawsze w adresie URL, kiedy coś wyszukujemy. Takie zapytanie zawęża nam wyszukiwania tylko do tych adresów URL, które zawierają ten parametr.
Problem
W witrynie indeksowane są wyniki wyszukiwania. Z punktu widzenia SEO powinniśmy zablokować robotom możliwość ich indeksacji. W przypadku witryny ZUS.pl zaindeksowane są tylko 4 wyniki wyszukiwania, co nie stanowi większego problemu, ale jest to pewne zagrożenie w kontekście przyszłości.
Rozwiązanie problemu
W sekcji <head> wyników wyszukiwania należy umieścić dyrektywę dla robotów.
<meta name="robots" content="noindex" />
Dodatkowo warto zablokować wyniki wyszukiwania poprzez plik robots.txt – takie rozwiązanie spowoduje, że robot wyszukiwarki najpewniej w ogóle nie będzie wchodził na te podstrony, dzięki czemu nie będą one marnowały crawl budgetu serwisu, na który w przypadku tak dużych serwisów należy zwrócić uwagę.
W pliku robots.txt powinna znaleźć się dyrektywa:
Disallow: /wyniki-wyszukiwania/*
Dyrektywa ta powinna odnosić się do wszystkich robotów.
Więcej informacji na temat pliku robots.txt znajdziesz tutaj.
Linki z parametrem nie mają znacznika rel=canonical (mało pilne)
Komentarz:
Często mamy do czynienia z sytuacją, że w linkach stosowane są różnego rodzaju parametry. Przykładem mogą być tu parametry UTM, które przekazują informacje o źródle ruchu w serwisie internetowym. Google sugeruje, aby wszystkie linki z parametrami opatrzyć znacznikiem rel=canonical na wersję bez parametrów.
Problem
Adresy URL z parametrem nie zawierają znacznika rel=canonical wskazującego na kanoniczną wersję strony. Obecnie nie jest to problem, ale w przyszłości mogą pojawić się sytuacje, w których linki z parametrem pojawią się w indeksie wyszukiwarki.
Przykład takiego linku: https://www.ZUS.pl/?=seo
Rozwiązanie
Na podstronach z parametrem, w sekcji <head>, należy umieścić link kanoniczny do wersji tej podstrony bez parametru. W przypadku podstrony https://www.ZUS.pl/?=seo powinniśmy umieścić tam dyrektywę.
<link rel="canonical" href="https://www.ZUS.pl" />
Więcej informacji na temat linków kanonicznych (oraz innych metodach ich wdrożenia) znajdziesz tutaj.
Znaczniki hreflang (średnio pilne)
Komentarz:
Jeśli witryna posiada różne wersje językowe strony, to powinniśmy poinformować o tym wyszukiwarkę poprzez użycie znaczników hreflang.
Witryna ZUS.pl posiada różne wersje językowe. W takiej sytuacji Google sugeruje stosowanie znaczników hreflang, które wskazują mu alternatywne wersje poszczególnych podstron w innych językach.
Problem
Obecnie witryna ZUS.pl pomimo różnych wersji językowych nie stosuje znaczników hreflang.
Rozwiązanie problemu
W sekcji <head> serwisu oraz w sitemapie XML należy dodać znaczniki hreflang tak jak na poniższym przykładzie:
<link rel="alternate" hreflang="en-gb" href="http://en-gb.example.com/page.html" /> <link rel="alternate" hreflang="en-us" href="http://en-us.example.com/page.html" /> <link rel="alternate" hreflang="en" href="http://en.example.com/page.html" />
Witryna ZUS.pl nie posiada identycznych kopii w każdym języku, więc znaczniki dodajemy tylko na tych podstronach, które mają idealne odwzorowanie w innych językach.
Opis wdrożenia znacznika hreflang znajdziesz tutaj.
Budżet crawlowania (mało pilne)
Komentarz:
W zakresie budżetu crawlowania błędne podstrony (np. błędy 404) można wydobyć z narzędzia Google Search Console. Dodatkowo warto przeprowadzić analizę logów odwiedzin Googlebota, aby sprawdzić, które podstrony w serwisie odwiedza najczęściej. W tym przypadku nie mieliśmy takiej możliwości, dlatego całość rekomendacji opieramy na crawlu wykonanym w narzędziu Screaming Frog.
Zagadnienie budżetu crawlowania (crawl budget) poruszaliśmy już wyżej w kontekście indeksowania niepotrzebnych podstron czy wyników wyszukiwania. One również wpływają na ten budżet. Celem tego działania jest:
- ograniczenie błędów 404,
- minimalizacja wewnętrznych przekierowań,
- maksymalizacja częstotliwości odwiedzin robota na najważniejszych podstronach,
- wyłączenie z indeksu podstron, które z punktu widzenia SEO nie mają wartości.
Każda witryna ma przez roboty wyszukiwarek przypisaną pewną moc obliczeniową. To moc, którą robot wyszukiwarki jest w stanie poświęcić na indeksowanie naszej witryny. Należy zatem tworzyć witryny tak, aby robot wyszukiwarki indeksował tylko te podstrony, które są wartościowe z punktu widzenia SEO. Te błędne powinny być usuwane lub blokowane.
Przykładowy audyt SEO – pobierz pełen audyt
To nie wszystko, co powinien zawierać audyt SEO. Pobierz dokument audytu, aby sprawdzić, jak zaudytować:
- architekturę informacji na stronie
- szybkość serwisu
- treści na stronie