 Piotr Skrzypek
Piotr Skrzypek Brak strony w Google oznacza, że wyszukiwarka nie jest w stanie jej zidentyfikować i tym samym wyświetlić użytkownikom treści, produktów lub usług, które oferujesz. Wraz ze wzrostem liczby witryn oraz zmieniającymi się algorytmami problemy z indeksacją stron zdarzają się coraz częściej, ale większości z nich możesz łatwo zapobiec lub rozwiązać, jeśli tylko zmienisz swoją strategię działania.
W pierwszej kolejności sprawdź, czy plik robots.txt nie zawiera blokad oraz, czy w kodzie strony nie zastosowano tagu noindex. Do popularnych przyczyn problemów z indeksacją należą również brak linków wewnętrznych i zewnętrznych (szczególnie w przypadku nowych stron), problemy z wersją mobilną oraz brak pliku sitemap.xml. Jeśli problemy z indeksacją nie wynikają z błędów technicznych, zwróć szczególną uwagę na jakość treści na stronie, ponieważ to często w niej tkwi problem. Do typowych przyczyn należą niewielka liczba produktów w kategorii sklepu, opisy niewnoszące wartości dla użytkownika, masowo generowane treści (np. przez AI), oferty opisane jednym zdaniem lub zduplikowane treści – to wszystko może sprawiać, że Google nie chce zaindeksować strony.
A ponieważ indeksacja jest pierwszym krokiem do widoczności, upewnij się, że Twoja strona jest łatwo dostępna i dobrze postrzegana przez wyszukiwarkę.
Czym jest indeksowanie stron?
Indeksowanie stron w Google to proces, w którym roboty indeksujące, zwane również crawlerami oraz botami, przeszukują strony internetowe, analizują ich strukturę i treść. Dane te służą algorytmom do oceny jakości, przydatności oraz zgodności witryny z aktualnymi wytycznymi Google. Na tej podstawie decydują, czy dodać stronę do indeksu, czyli bazy danych wyników wyszukiwania, czy nie.
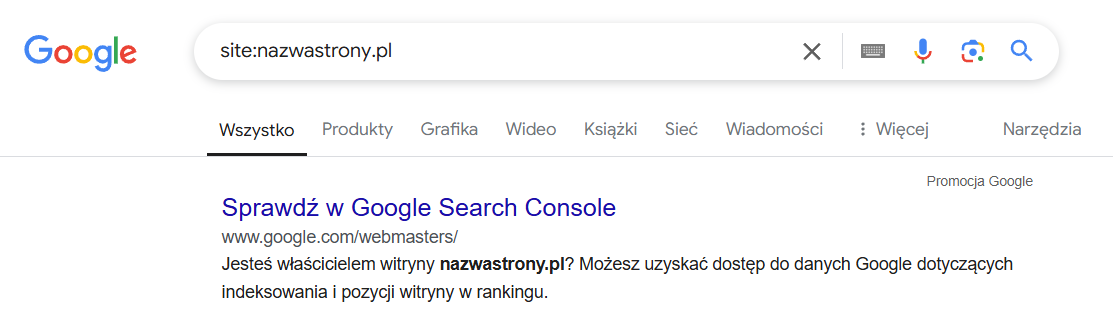
Jak sprawdzić, czy Twoja strona jest zaindeksowana? Wystarczy wpisać nazwę swojej strony do okna wyszukiwarki z komendą site, czyli na przykład: site:nazwastrony.pl – jeśli adres pojawi się w wynikach wyszukiwania, to znaczy, że Twoja strona została zaindeksowana.
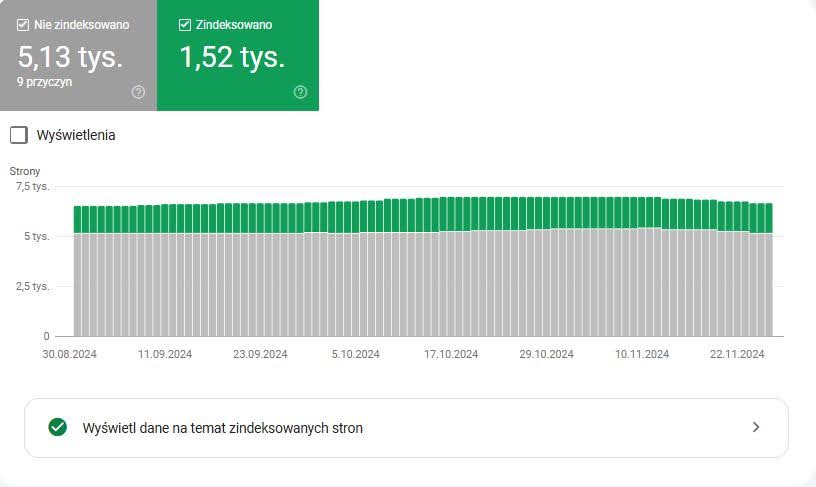
Drugim sposobem jest weryfikacja raportu „Indeksowanie stron” w Google Search Console.
Samo indeksowanie jest natomiast częścią większego procesu, który składa się z trzech etapów.
- Crawling – polega na analizie (skanowaniu) witryny przez roboty Google, które podążają za linkami między stronami (lub ręcznymi zgłoszeniami tych stron, których właściciele mogą dokonywać za pomocą Google Search Console).
- Indeksowanie – jest to dodawanie witryny do indeksu, czyli bazy danych Google, która jest podstawą wyników wyszukiwania, z których później korzystasz Ty oraz Twoi odbiorcy.
- Ranking – wynika z kolejności, w jakiej zindeksowane witryny wyświetlają się w organicznych wynikach wyszukiwania. Pozycja strony w rankingu zależy od stopnia dopasowania jej zawartości do zapytania wpisanego przez użytkownika w wyszukiwarkę.
Dlaczego indeksowanie jest tak ważne?
Jeśli zablokujesz lub utrudnisz robotom Google crawling oraz indeksację, Twoja strona nie będzie mogła wyświetlić się w wynikach wyszukiwania. Pozostanie niewidoczna zarówno dla wyszukiwarki, jak i użytkowników, co uniemożliwi Ci dotarcie do potencjalnych klientów, osiągnięcie dobrego współczynnika konwersji (sprzedaży lub zapytań), na którym przecież zależy Ci najbardziej.
Jeśli więc chcesz zoptymalizować witrynę pod kątem wyszukiwarki, w pierwszej kolejności zweryfikuj, czy roboty będą w stanie ją przeskanować i zaindeksować.
Dlaczego problemy z indeksacją stron zdarzają się coraz częściej?

Na świecie jest ponad miliard stron internetowych [1]. Przy takiej liczbie witryn, która zresztą stale rośnie, Google stoi przed wyzwaniem – jego zasoby obliczeniowe, jeśli chodzi o indeksację każdego nowego adresu URL, są po prostu ograniczone. Dlatego właśnie indeksuje przede wszystkim strony o wysokiej jakości i wartości dla użytkowników. Niektóre witryny, szczególnie z dużą liczbą niskiej jakości podstron, mogą być częściowo pomijane – zjawisko to określa się mianem Index Bloat.
Jak samodzielnie zgłosić stronę do wyszukiwarki Google?
Jeśli chcesz szybko dodać swoją stronę lub konkretny adres URL do wyszukiwarki Google, najlepszym narzędziem do tego jest Google Search Console. Proces jest prosty i wymaga jedynie kilku kroków.
- Wklej interesujący Cię adres URL strony lub podstrony w główny pasek wyszukiwarki i naciśnij Enter.
- Jeśli wybrany adres nie został jeszcze zaindeksowany, pojawi się komunikat „Adres URL nie znajduje się w Google”.
- Kliknij przycisk „Poproś o zaindeksowanie”. Google sprawdzi, czy strona jest dostępna do indeksacji (np. czy nie jest blokowana przez plik robots.txt lub inne ustawienia).
- Po chwili zobaczysz komunikat: „Przesłano prośbę o zaindeksowanie”. Oznacza to, że Twoja strona została zgłoszona do uwzględnienia w wyszukiwarce.
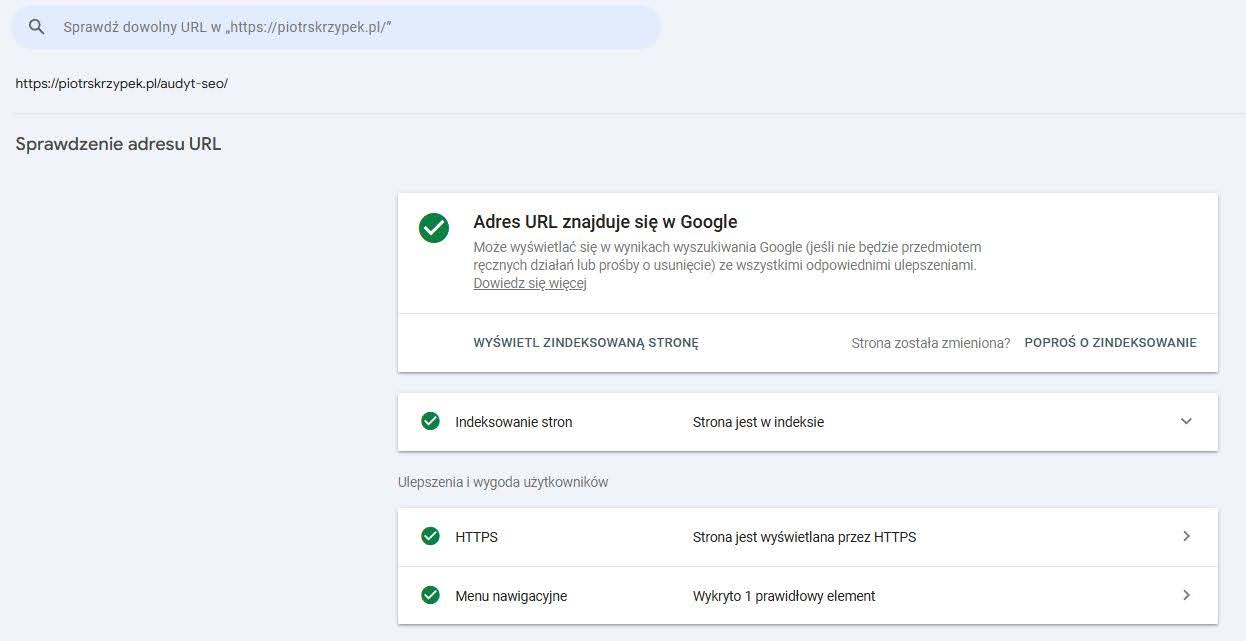
Jeśli strona jest już zaindeksowana, to po wklejeniu linku wyświetli się poniższy komunikat.
Jeśli wprowadzisz zmiany na stronie i chcesz, aby roboty Google przeskanowały ją jeszcze raz, możesz zgłosić ją do ponownej indeksacji. Procedura jest identyczna jak w przypadku zgłaszania nowego adresu URL. Po przesłaniu prośby Googlebot ponownie przeanalizuje zawartość strony i zaktualizuje informacje w indeksie. Aktualizacja wyników wyszukiwania może zająć od kilku godzin do kilku dni, więc nie martw się, jeśli zmiany nie pojawią się natychmiast.
Ręczne zgłaszanie strony do Google nie zawsze jest konieczne. W większości przypadków wyszukiwarka samodzielnie znajdzie Twoją witrynę, zwłaszcza jeśli inne strony internetowe prowadzą do niej linki lub aktywnie promujesz swój serwis w sieci. Roboty Google regularnie przeszukują internet, aby indeksować nowe treści, więc Twoja strona powinna prędzej czy później trafić do wyników wyszukiwania. Mimo to ręczne zgłoszenie przydaje się, kiedy zależy Ci na przyspieszeniu tego procesu, na przykład po opublikowaniu nowego artykułu na blogu, świeżo dodanej usługi lub innych kluczowych treści, które powinny jak najszybciej pojawić się w indeksie wyszukiwarki.
Jednak w przypadku większej liczby stron, takich jak setki nowych produktów w sklepie internetowym, ręczne zgłaszanie każdego adresu URL staje się niepraktyczne i czasochłonne. W takich sytuacjach najlepszym rozwiązaniem pozostaje automatyczne przesłanie mapy witryny (sitemap.xml) do Google Search Console.
Z czego mogą wynikać problemy z indeksacją?
I. Thin content
Do najczęstszych problemów z indeksowaniem należą te związane z treścią. Dlaczego? Ponieważ Google opiera swoje algorytmy na ocenie treści, aby określić, które strony będą najbardziej przydatne i adekwatne do zapytań użytkowników.
Duplikacja treści
Wiele stron internetowych mierzy się z duplikacją treści ze względu na błędy techniczne w swojej strukturze. Może to wynikać między innymi z braku ustawienia tagu kanonicznego oraz dostępności tej samej treści pod różnymi adresami URL, co zobaczysz na poniższych przykładach.
- Strony mogą być dostępne pod adresami z i bez www – www.example.com oraz example.com
- Adresy mogą funkcjonować z i bez protokołu HTTPS – http://example.com oraz https://example.com
- Poszczególne wersje językowe nie mają poprawnego atrybutu hreflang – example.com oraz example.de
Możesz tego uniknąć, jeśli wprowadzisz odpowiednie przekierowania stałe typu 301 na główny adres URL domeny oraz poprawisz konfigurację hreflang, by w ten sposób kierować użytkowników do odpowiednich wersji językowych.
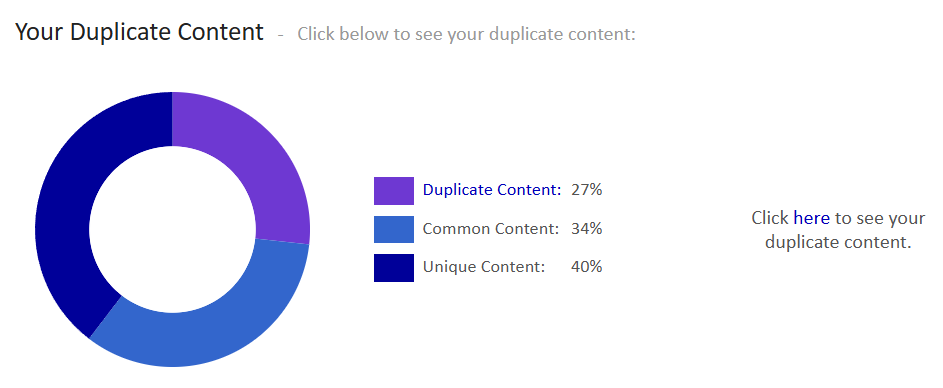
Utrudnieniem w indeksacji może być też duplikacja treści w CMS-ie wynikająca z automatycznego generowania stron lub nieprawidłowej konfiguracji szablonu, która sprawia, że np. opisy produktów znajdują się w kategoriach i kartach produktu. Unikaj też zewnętrznej duplikacji, czyli kopiowania treści z innych witryn bez ich modyfikacji oraz publikacji tych samych treści na różnych witrynach bez wyraźnego oznaczenia (np. publikacji artykułu blogowego na zewnętrznym portalu jako artykułu sponsorowanego).
Niska jakość treści
Niby wszyscy już wiemy, że content musi spełniać określone standardy, które aktualizacja algorytmu Helpful Content Update z 2023 roku podniosła jeszcze bardziej, jednak wiele osób, zamiast tworzyć treści dla użytkowników i z rozsądkiem je optymalizować, priorytetowo traktuje boty lub po prostu próbuje (błędnie) oszczędzić swój czas i pieniądze.
Zbyt mało treści lub jej całkowity brak
Może być tak, że roboty zaindeksują Twoją stronę, ale nie znajdą na niej wartościowej treści. Wtedy przypiszą ją w Google Search Console do kategorii „Page indexed without content”. W takiej sytuacji skup się jednak na jakości, a nie ilości – unikaj tworzenia treści wyłącznie w celu „wypełnienia strony”, tylko stopniowo dodawaj content, który odpowiada na pytania lub potrzeby Twojej grupy docelowej.
Keyword stuffing
Keyword stuffing polega na przesycaniu treści na stronie internetowej nadmierną liczbą słów kluczowych, co utrudnia lekturę użytkownikom i obniża tym samym komfort korzystania ze strony. Naraża Cię też na spadek pozycji strony w rankingu wyników wyszukiwania oraz ograniczoną efektywność indeksowania. Umieszczaj więc słowa kluczowe w strategicznych miejscach, ale z umiarem – w pierwszych zdaniach tekstu, w nagłówkach oraz raz na jakiś czas w treści, ale zawsze w nawiązaniu do kontekstu.
Cloacking
Ukrywanie treści, bo tym jest cloacking, polega na tym, że roboty i użytkownicy widzą ten sam adres URL, ale zaprezentowany w zupełnie inny sposób. Technikę tę wykorzystuje się np. po to, by publikować treści przesycone frazami niewidoczne z perspektywy użytkownika.
Wszystkie te praktyki wpływają negatywnie nie tylko na indeksację, ale również na jakość wyników wyszukiwania Google, które stają się coraz gorsze [2] m.in. z powodu przesadnie zoptymalizowanego spamu SEO.
II. Blokady przed indeksacją: plik robots.txt oraz tag noindex
Tag noindex informuje roboty Google, że mają nie uwzględniać danej strony w indeksie wyszukiwania. W teorii więc pomaga kontrolować proces indeksowania.
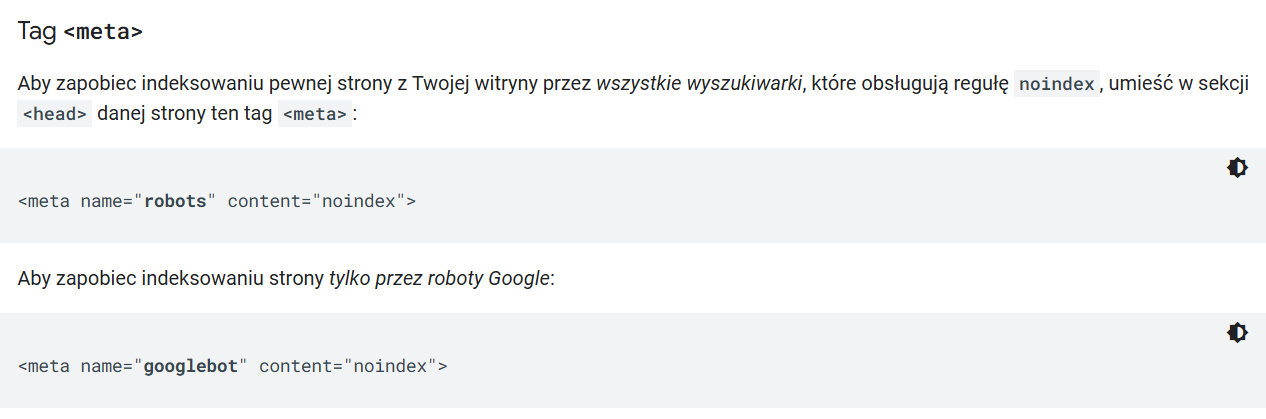
Niestety często zdarza się jednak, że podczas tworzenia nowej strony, deweloperzy blokują ją przed indeksacją tagiem noindex i zapominają go usunąć przy wdrożeniu. Jak rozwiązać ten problem?
- Jeśli zauważysz w Google Search Console, że strona, która powinna być zaindeksowana, jest oznaczona tagiem noindex, usuń go z kodu HTML.
- Upewnij się, że wtyczka CMS, z której korzystasz, np. Yoast SEO, nie wprowadza domyślnie tagu na stronach, które powinny być widoczne w wynikach wyszukiwania.
Twój problem z indeksacją może również wynikać z nieprawidłowej konfiguracji pliku robots.txt. Reguluje on dostęp do poszczególnych części witryny, np. pozwala zablokować dostęp do podstron ze zduplikowanymi treściami. Jednak błędna konfiguracja może prowadzić do niezamierzonego zablokowania stron, które powinny być indeksowane. Jak sobie z tym poradzić?
- Sprawdź plik robots.txt pod kątem obecności dyrektywy Disallow, która mogła zablokować robotom dostęp do całej witryny. W zamian zastosuj dyrektywę Allow, która go odblokuje
- Może być też tak, że dyrektywa Disallow zablokowała wybrane podstrony – w takiej sytuacji usuń ten zapis.
III. Problemy z linkowaniem wewnętrznym
Linki wewnętrzne pomagają robotom Google poruszać się po Twojej stronie – ułatwiają nawigację i identyfikację struktury witryny. Jeśli tych linków nie ma lub jest ich niewiele, to boty mogą mieć problem z indeksowaniem stron. Co jeszcze będzie ją utrudniało?
- Uszkodzone linki (ang. broken links) – prowadzą do nieistniejących stron, obniżają jakość doświadczenia użytkowników (UX) i negatywnie wpływają na SEO oraz indeksację. Żeby je zidentyfikować, skorzystaj z narzędzi takich jak Screaming Frog lub Google Search Console. Następnie zastąp uszkodzone linki poprawnymi adresami URL lub usuń je, jeśli nie są potrzebne.
- Orphan pages (tj. osierocone strony) – to strony, które nie mają żadnych linków wewnętrznych prowadzących do nich, przez co są niewidoczne dla robotów wyszukiwarek i trudne do znalezienia dla użytkowników. Aby rozwiązać ten problem, zaktualizuj strukturę witryny, dodając linki wewnętrzne włączające te strony do logicznej hierarchii nawigacyjnej. Upewnij się, że każda podstrona ma co najmniej jeden link wewnętrzny prowadzący ze strony głównej lub podstrony.
- Tag nofollow – służy m.in. do oznaczania linków wewnętrznych, które nie powinny przekazywać mocy rankingowej, np. polityki prywatności czy strony logowania. Błędnie zastosowany tag nofollow, sprawia, że roboty nie podążają za takim linkiem. Jeśli podejrzewasz taką sytuację, przeanalizuj witrynę za pomocą narzędzi SEO takich jak Ahrefs czy Screaming Frog, aby zidentyfikować niepotrzebne atrybuty nofollow i usuń je, jeżeli blokują indeksację kluczowych podstron.
- Niska jakość linków – linki wewnętrzne pomagają nie tylko w nawigacji, ale także w dystrybucji tzw. link juice, czyli mocy rankingowej między stronami w witrynie. Linkuj strategicznie, a więc do podstron powiązanych tematycznie ze stroną, z której wychodzi link. Upewnij się też, że anchory, czyli teksty linków, są opisowe i jasno wskazują na zawartość strony, do której prowadzą. Unikaj linków wewnętrznych ukrytych pod ogólnymi wyrażeniami, takimi jak „zobacz”, „tutaj”, a zamiast tego użyj frazy: „sprawdź naszą ofertę na buty sportowe”.
- Błędna struktura strony – zbyt głębokie osadzenie podstron może skomplikować robotom Google i użytkownikom drogę do danej kategorii. Zgodnie z rekomendacjami użytkownicy powinni dotrzeć do każdej podstrony ze strony głównej za pomocą maksymalnie trzech kliknięć – nie jest to jednak absolutna konieczność. Dużo ważniejsze jest zapewnienie łatwego dostępu do kluczowych podstron za pomocą czytelnej nawigacji i uproszczonej struktury witryny.
IV. Brak lub błędy w pliku sitemap.xml
Roboty Google potrzebują czytelnych kierunkowskazów, dlatego musisz stworzyć plik sitemap.xml. Możesz do tego wykorzystać różne narzędzia do automatycznego generowania map, np. XML Sitemaps Generator, a następnie przesłać go ręcznie za pośrednictwem Google Search Console i uwzględnić odnośnik w pliku robots.txt.
Dlaczego sitemap.xml jest ważny?
Plik sitemap.xml pozwala botom Google:
- zidentyfikować wszystkie kluczowe podstrony Twojej witryny,
- znaleźć nowe strony, które nie mają jeszcze linków wewnętrznych,
- dotrzeć do podstron głęboko osadzonych w strukturze witryny,
- skuteczniej zarządzać crawl budgetem, kierując roboty na najważniejsze strony.
Częste błędy w pliku sitemap.xml
Jeśli jednak w pliku sitemap.xml pojawią się błędy, prawdopodobnie będziesz mieć problem z indeksacją. Które z nich są najczęstsze?
Dodanie do pliku adresów URL, które:
- zostały wcześniej zablokowane przez robots.txt, co dostarcza botom sprzecznych informacji,
- są nieaktualne – nie mają przekierowań lub nie istnieją, przez co mogą obniżać efektywność indeksacji,
- są zduplikowane, co sprzyja nieefektywnemu korzystaniu z crawl budgetu oraz problemom z kanibalizacją treści.
2. Zbyt duża liczba adresów URL w jednym pliku (ponad 50 000), z czym możesz sobie poradzić, np. rozdzielając sitemap.xml na kilka plików i tworząc indeks map. Problem z indeksacją może dodatkowo pogorszyć niska jakość tych linków.
3. Błędy w formatowaniu, które utrudniają poprawne odczytanie mapy strony, np. brak zamknięcia znacznika <url>. Zweryfikuj plik za pomocą narzędzi do walidacji, np. XML Sitemap Validator.
Regularnie aktualizuj też plik, aby odzwierciedlał zmiany na stronie (np. dodanie nowych podstron czy usunięcie starych), co może Ci pomóc poprawić indeksację.
V. Brak dopasowania strony do urządzeń mobilnych
Jeśli Twoja strona internetowa nie jest dostosowana do urządzeń mobilnych, musisz się liczyć z prawdopodobieństwem niższej pozycji w wynikach wyszukiwania. Dlaczego?
Mobile first index to strategia Google, zgodnie z którą boty oceniają witryny przede wszystkim pod kątem tego, jak wyświetlają się na urządzeniach mobilnych – to właśnie z nich najczęściej korzystają użytkownicy, więc roboty traktują to priorytetowo. Zresztą obecnie około 76,17% najpopularniejszych witryn na świecie jest dostosowanych do urządzeń mobilnych [3], co pokazuje, że część stron nadal może mieć w tym obszarze pracę do wykonania.
Jak możesz poprawić responsywność swojej witryny, a tym samym pozycję w rankingu?
- Skonfiguruj meta tag viewport, dzięki któremu treści będą się skalowały do rozmiaru ekranu urządzenia.
- Zadbaj o zgodność strony internetowej ze standardami ADA, czyli o jej dostępność dla wszystkich użytkowników, również osób z niepełnosprawnościami (np. poprzez dodanie tekstu ALT do obrazów).
- Umieszczaj przyciski nawigacyjne oraz buttony CTA w zasięgu kciuka (Thumb Zone Design) oraz w rozmiarze od 42 px do 72 px w zależności od ich priorytetu.
- Skorzystaj z narzędzi, takich jak np. Lighthouse, aby sprawdzić, jak Twoja strona działa na urządzeniach mobilnych.
Dlaczego warto zadbać o mobilną wersję strony?
Google faworyzuje responsywne strony w wynikach wyszukiwania, ponieważ oferują one użytkownikom lepsze doświadczenia. Poprawiając responsywność witryny:
- zwiększysz widoczność w Google, co przełoży się na większy ruch organiczny,
- poprawisz współczynnik konwersji, ponieważ użytkownicy będą łatwiej korzystać z Twojej strony,
- zmniejszysz współczynnik odrzuceń, ponieważ strona będzie szybka i intuicyjna.
VI. Za długi czas ładowania strony
Zbyt długi czas ładowania generuje rocznie 2,6 miliarda dolarów strat w sprzedaży [4]. Obniża też zaangażowanie użytkowników, a raczej na wzrost współczynnika odrzuceń (bounce rate). Przede wszystkim jednak jest jednym ze wskaźników Core Web Vitals, które od 2021 roku są częścią algorytmu Google i mierzą jakość doświadczeń użytkowników.
Twoje problemy z indeksacją mogą więc wynikać ze zbyt niskiej prędkości witryny. W efekcie może się zmniejszyć liczba podstron, które będą w stanie przeskanować boty, a to może czasowo wykluczyć z indeksu istotne dla Ciebie podstrony.
Orientacja Google na doświadczenia użytkowników sprawia, że zapewnienie odpowiedniej prędkości działania witryny powinno być jednym z Twoich priorytetów. Oczywiście wszystko w granicach rozsądku – śrubowanie wyników pochodzących z testów wykonanych w laboratoryjnych warunkach może nie przynieść realnych korzyści użytkownikom ani poprawy pozycji w wynikach wyszukiwania.
Żeby zweryfikować prędkość ładowania swojej strony, skorzystaj z PageSpeed Insights. Co zrobić, jeśli okaże się, że masz nad czym pracować?
- Zmniejsz liczbę żądań HTTP, optymalizując kod strony i usuwając nieużywane pliki CSS lub JavaScript, lub łącząc określone zasoby.
- Skompresuj pliki JavaScript i CSS, np. za pomocą narzędzi takich jak CSS Minifier czy JavaScript Compression Tool.
- Zastosuj lazy loading dla obrazów i filmów, aby ładować tylko te elementy, które są widoczne na ekranie w pierwszej kolejności.
- Zmniejsz rozmiar obrazów i korzystaj z wydajniejszych formatów, które oferują lepszą kompresję niż JPG czy PNG, np. AVIF lub WebP; kompresuj obrazy bez utraty jakości za pomocą narzędzi, takich jak np. TinyPNG.
- Zadbaj o wdrożenie Content Delivery Network (CDN), aby przyspieszyć ładowanie strony.
- Włącz cache przeglądarki, który zapewni szybsze ładowanie strony powracającym użytkownikom.
VII. Błędy w pliku .htaccess
Plik .htaccess to narzędzie konfiguracyjne w serwerach, które działają na platformie Apache. Odpowiada za ustawienia na poziomie serwera, które wpływają na to, jak serwer obsługuje żądania. Jak ma się do problemów z indeksowaniem witryny? Umożliwia zarządzanie m.in. dostępem do stron oraz określonych folderów czy plików, przekierowaniami (np. z http na https), a także kompresją plików.
Jego nieprawidłowa konfiguracja może mieć negatywny wpływ na indeksowanie oraz działanie całej witryny. Co dokładnie może powodować problemy?
- Sprawdź obecność reguł blokujących dostęp robotom Google
- Deny from all – blokuje dostęp wszystkim, w tym robotom
- Disallow: / – w pliku robots.txt blokuje całą stronę, ale podobna reguła może występować w pliku .htaccess
- Zweryfikuj, czy plik znajduje się w poprawnym katalogu, a serwer Apache ma włączoną jego obsługę.
- Sprawdź, czy nieprawidłowe ustawienia przekierowań nie doprowadziły do pętli przekierowań, np. strona A przekierowuje na stronę B, a ta ponownie na stronę A. Możesz to zrobić za pomocą narzędzi takich jak np. Redirect Checker.
- Zablokowanie ważnych zasobów – błędna konfiguracja może blokować pliki, takie jak obrazy, JavaScript czy CSS, co utrudnia robotom Google prawidłowe renderowanie i ocenę strony.
VIII. Przekroczony crawl budget
Crawl budget określa liczbę adresów URL, którą mogą skanować boty w określonych ramach czasowych oraz częstotliwość, z jaką mogą indeksować stronę. Problem z jego optymalizacją jednak przede wszystkim dużych witryn, w tym sklepów internetowych z rozbudowaną ofertą.

Co wpływa na wielkość crawl budgetu? To między innymi wydajność serwera, liczba przekierowań, zduplikowany content, zbyt wiele stron niskiej jakości, czy nawigacja fasetowa bez ograniczeń, co może sprawić, że roboty Google wykorzystają dostępne zasoby na podstrony, na których Ci nieszczególnie zależy.
Jeśli podejrzewasz problemy z indeksowaniem swojej strony:
- sprawdź Crawl Stats report, z którego dowiesz się między innymi, czy Google ma trudności z dostępem do Twojej witryny,
- upewnij się w Google Search Console, czy roboty miały trudności z dostępem do strony, np. przez błędy 5xx, 4xx,
- usuń wszystkie zbędne adresy URL z pliku sitemap.xml,
- upewnij się, że nie blokujesz ważnych stron w pliku robots.txt,
- popraw wydajność serwera tak, aby Google mogło szybciej skanować Twoją witrynę,
- kontroluj nawigację fasetową, wprowadzając kanoniczne adresy URL lub blokując nieistotne parametry w pliku robots.txt,
- pozbądź się tzw. thin contentu.

Choć optymalizacja budżetu indeksowania dotyczy głównie dużych witryn, mniejsze strony również mogą odnieść z tego tytułu korzyści. Skuteczne zarządzanie crawl budgetem:
- zwiększa efektywność indeksowania przez boty Google,
- poprawia widoczność w wynikach wyszukiwania,
- zmniejsza ryzyko marnowania zasobów indeksacyjnych na strony niskiej jakości.
IX. Strony zwracające błędy z kodami 4xx i 5xx
Strony, które zawierają błędy z kodami 4xx (błędy po stronie użytkownika) i 5xx (błędy po stronie serwera) utrudniają indeksację stron, ponieważ sygnalizują robotom problemy z dostępem do zasobów lub ich brak. Jeśli wiele podstron zwraca np. błąd 404 lub 500, boty niepotrzebnie tracą czas na próby ich przeskanowania, zamiast indeksować wartościowe treści.
Zbyt duża liczba błędów może też sugerować, że masz źle skonfigurowaną witrynę, a to negatywnie wpływa na ocenę jej jakości i wrażenia użytkowników. Jak możesz uniknąć tych problemów?
- Monitoruj błędy w Google Search Console – regularnie sprawdzaj raporty indeksowania i naprawiaj błędy 4xx i 5xx.
- Zadbaj o większą stabilność serwera – upewnij się, że infrastruktura serwerowa jest odpowiednio skalowana i zoptymalizowana pod kątem obciążenia.
- Stosuj kod statusu 503 wyłącznie w krótkotrwałych sytuacjach, np. z powodu prac serwisowych – dołącz do niego nagłówek Retry-After, który poinformuje Google, kiedy strona będzie ponownie dostępna.
- Wprowadź monitoring i automatyczne zarządzanie błędami 4xx i 5xx – skorzystaj z narzędzi takich jak Pingdom czy UptimeRobot, by otrzymywać alerty o błędach i szybciej na nie reagować.
- Analizuj logi serwera – może to wymagać współpracy z hostingodawcą / deweloperem lub czy zespołem IT, ale pomocne może być też narzędzie Screaming Frog SEO Log File Analyser.

X. Błędne lub niezrozumiałe skrypty JavaScript
Dynamiczne ładowanie strony (AJAX, czyli asynchroniczny JavaScript i XML) eliminuje konieczność odświeżania strony np. kiedy użytkownik doda produkt do koszyka, który aktualizuje się automatycznie. Żeby boty były w stanie zaindeksować całą zawartość strony, skrypty muszą być przetwarzane w odpowiedniej kolejności. Jeśli skrypt jest zbyt skomplikowany lub błędny, boty mogą go zignorować, i w ten sposób opóźnić indeksację strony.
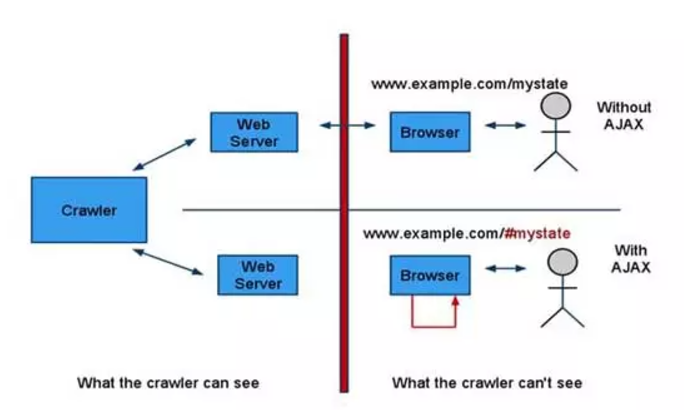
Co generuje takie problemy?
- Błędy składniowe, np. brakujące lub źle umieszczone nawiasy bądź średniki.
- Niepoprawne porównania i kontrole równości, które mogą prowadzić do błędów w logice skryptu.
- Złożone skrypty mogą być przetwarzane przez roboty bardzo wolno lub wcale.
- JavaScript często wymaga dodatkowych plików lub danych do działania, np. JSON. Jeśli te zasoby są niedostępne, strona może nie załadować treści.
- Client-Side Rendering (CSR) sprawia, że początkowo roboty widzą pustą stronę HTML, co może opóźnić indeksację.
Co możesz poprawić?
- Sprawdź poprawność kodu JavaScript – należy pozbyć się błędów składniowych i logicznych w kodzie.
- Zadbaj o uproszczenie skryptów, eliminując zbędny kod i minimalizując pliki JavaScript.
- Włącz Server-Side Rendering (SSR) – tak, aby roboty Google mogły zobaczyć treść już na etapie ładowania strony; opcjonalnie możesz zastosować też prerendering, aby dostarczyć robotom wersję HTML z załadowanymi treściami.
- Zweryfikuj renderowanie w Google Search Console – zrobisz to w narzędziu „Sprawdzanie adresów URL”.
XI. Brak tagu canonical lub jego nieprawidłowe wdrożenie
Tag canonical informuje roboty, którą wersję strony powinny traktować jako główną, gdy istnieją jej duplikaty lub strony z podobną treścią. Dlaczego warto określić kanoniczny adres URL? W ten sposób wyraźnie wskażesz, który adres powinien być widoczny w wynikach wyszukiwania, a boty Google nie będą traciły czasu na indeksowanie duplikatów.
Rel=canonical jest jednak dla Google wyłącznie wskazówką, a nie dyrektywą, która zobowiązywałaby wyszukiwarkę do wyświetlania wskazanej strony. Sugestia będzie skuteczna tylko, jeśli wskazana przez Ciebie strona została już zaindeksowana. Może się jednak zdarzyć, że Google poprzez swoje algorytmy uzna za kanoniczny inny adres, ale możesz to bez problemu zweryfikować w Google Search Console.
Dlaczego możesz mieć trudności z identyfikacją błędu? Błędne ustawienie tagu może nie być widoczne na pierwszy rzut oka – zdarza się, że jest trochę jak wkradający się do kodu „chochlik”. Nieprawidłowe tagi znajdziesz z pomocą takich narzędzi jak wspomniane GSC oraz Ahrefs czy Screaming Frog.
Do jakich problemów może dochodzić w związku z implementacją tagu kanonicznego?
1. Brak wdrożenia rel=canonical
Brak tagu canonical może skutkować indeksacją podstron z parametrami i bez nich, np. stron powstałych w wyniku filtrowania lub sortowania. To prowadzi do duplikacji treści, co w efekcie może spowodować usunięcie powielonych podstron z indeksu Google. Aby się przed tym zabezpieczyć, najlepiej ustawić tzw. self-canonical.
2. Ustawienie tagu canonical wskazującego inną stronę
Jeżeli na stronie, którą chcesz zaindeksować, dodasz tag canonical z linkiem do innej strony, poinformujesz roboty, że oryginalna treść znajduje się pod kanonicznym URL-em i to ten adres chcesz dodać do indeksu. Co możesz z tym zrobić?
- Link kanoniczny to tzw. miękkie przekierowanie, więc taka sytuacja może doprowadzić do usunięcia podstrony z indeksu Google. Jeśli zależy Ci na wykluczeniu konkretnej strony z wyników wyszukiwania, rozważ przekierowania stałego typu 301.
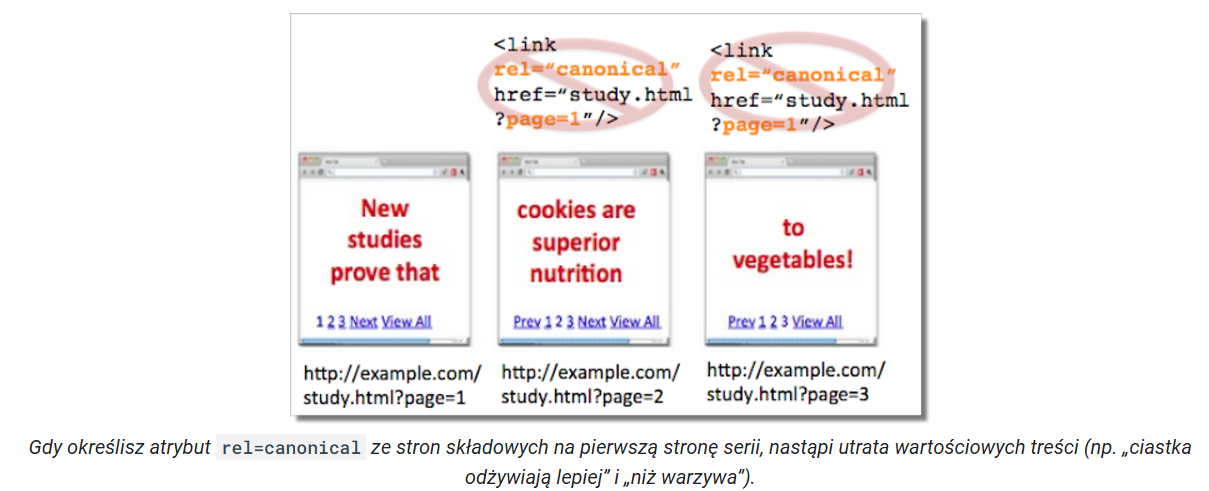
3. Nieprawidłowa implementacja canonical w paginacji
W przypadku paginacji popularnym błędem jest ustawienie tagu canonical wskazującego stronę pierwszą na 2, 3, 4, itd. stronie paginacji [5]. Może to doprowadzić do usunięcia z indeksu kolejnych stron oraz wyindeksowania produktów, ponieważ stronicowanie jest jedną ze ścieżek dojścia do produktów dla robotów Google.
4. Nieprzemyślane użycie tagu w stronach produktów z wariantami
Kilka rozmiarów czy kolorów przypisanych do tego samego produktu to standardowa sytuacja w e-commerce. Tego rodzaju podstrony mogą mieć różne adresy URL, ale niemal identyczną treść. W takiej sytuacji lepiej zastosować tag canonical, który wskaże główną stronę. Jeśli jednak te warianty mają unikalne cechy (opisy, metadane), warto potraktować je jako oddzielne strony.
5. Wskazanie na nieistniejącą stronę
Kiedy w rel=canonical znajduje się odnośnik do strony, która nie istnieje (błąd 404) lub zawiera błędy (np. pętle przekierowań), boty mogą pominąć zarówno stronę kanoniczną, jak i podstronę, która na nią wskazuje.
6. Konflikty między tagami canonical
Do problemów z indeksacją może doprowadzić sytuacja, w której strona A wskazuje na stronę B jako kanoniczną, a strona B na stronę A – są to tzw. pętle kanoniczne. Wówczas najlepiej ustalić jedną wersję kanoniczną dla każdej ze stron.
7. Nieprawidłowe umiejscowienie tagu canonical
Jeśli umieścisz tag canonical w sekcji <body> lub w innych nieprawidłowych miejscach, roboty mogą go nie rozpoznać. Tag powinien się znajdować w sekcji <head> dokumentu HTML. Jak wygląda przykładowa struktura?
<link rel =”canonical” href=”https://xyz.pl/kategoria/produkt/”/>
Stosowanie względnych ścieżek (np. /kategoria/produkt/) może prowadzić do niepotrzebnych komplikacji, szczególnie jeśli strona działa w różnych domenach lub wersjach protokołów (HTTP/HTTPS).
8. Wskazanie strony głównej lub jednej podstrony jako kanonicznej
W niektórych systemach zarządzania treścią (CMS) lub szablonach stron, tag canonical generuje się automatycznie Zdarza się wówczas, że wszystkie strony witryny wskazują jako kanoniczną stronę główną lub jedną podstronę, co prowadzi do wykluczenia z indeksacji reszty witryny.
9. Problemy przy wdrożeniu wielojęzyczności
Na stronach wielojęzycznych tag canonical powinien być zgodny z ustawieniami hreflang. Upewnij się też, że tag na każdej stronie odnosi się do właściwej wersji językowej. Jeżeli strona w języku polskim będzie wskazywała jako kanoniczną wersję w języku angielskim, może to doprowadzić do błędów w indeksacji.

XII. Kara od Google, o której nie wiesz
Google nakłada filtry na strony internetowe ręcznie lub algorytmicznie – robi to, jeśli zostały naruszone wytyczne dotyczące metod pozycjonowania. Jeśli kara wynika ze zmian w algorytmie, nie dowiesz się o niej z raportu w Google Search Console (GSC). Sygnałem, że do tego doszło, będzie nagły spadek widoczności i ruchu witryny w wynikach wyszukiwania, który zauważysz, monitorując sytuację w Google Analytics, GSC lub innych narzędziach SEO takich jak Senuto czy Ahrefs.
Z jakich powodów Google nakłada kary najczęściej?
- Treści niskiej jakości, również te, których nie tworzył człowiek (to nie oznacza, że nie możesz korzystać ze sztucznej inteligencji, ale rób to mądrze – zadbaj o weryfikację merytoryczną i redakcję tak, by tekst był unikalny, oraz wartościowy i czytelny dla odbiorców).
- Nienaturalne linki wychodzące oraz ich nadmiar.
- Pozyskiwanie w krótkim czasie dużej liczby niskiej jakości linków zwrotnych.
- Przekierowania ukryte przed botami Google.
Zobacz, czy Google nie nałożyło na Twoją stronę kary. Żeby to zrobić, zaloguj się do GSC i sprawdź raport Ręczne działania, który pokaże Ci historię dotyczącą Twojej witryny. Trwa to zaledwie chwilę, a może dać bardzo cenną informację. Warto wspomnieć, że tego typu kary w praktyce zdarzają się coraz rzadziej i bardzo mało stron otrzymuje takie powiadomienia. Jeśli jednak raport potwierdzi Twoje przypuszczenia, sprawdź, jakie dokładnie naruszenia wytycznych wykryło Google, a następnie usuń błędy i przede wszystkim zmień strategię działania. Kiedy już wprowadzisz zmiany, prześlij do Google prośbę o ponowną weryfikację witryny.
Problemy z indeksowaniem – podsumowanie
World Wide Web Size Project szacuje, że Google zaindeksowało około 50 miliardów stron internetowych [6], a co minutę właściciele uruchamiają 175 nowych stron internetowych [7], co daje około 252 000 witryn dziennie. Roboty Google muszą mierzyć się z olbrzymim wyzwaniem, jakim jest zarządzanie tym ogromnym zbiorem danych. Choć na trudności po stronie Google nie masz bezpośredniego wpływu, istnieje wiele sposobów, aby usprawnić indeksację swojej witryny.
W przypadku większości trudności związanych z indeksowaniem możesz coś zrobić. Część z nich wynika z banalnych wręcz sytuacji – nowych stron Google nie indeksuje od razu, a to może budzić obawy u właścicieli witryn oczekujących szybkich wyników. W tym wypadku wystarczy jednak uzbroić się w cierpliwość, bo indeksowanie trwa od kilku dni do nawet kilku tygodni.
Miej też na uwadze, że najczęściej problemy z indeksacją stron nie są jednorazowe. Mają prawo się powtarzać – szczególnie jeśli masz rozbudowaną witrynę. Kluczem do sukcesu jest trzymanie ręki na pulsie, czyli wdrażanie i regularny monitoring elementów takich jak wartościowy content, przemyślane linkowanie wewnętrzne, zarządzanie przekierowaniami czy umiejętne wykorzystanie tagu rel=canonical, by poprawić indeksowanie.
[1] https://siteefy.com/how-many-websites-are-there/
[2] https://seo.ai/blog/are-google-search-results-getting-worse-study
[3] https://siteefy.com/how-many-websites-are-there/#How-Many-Websites-Are-Mobile-Friendly
[4] https://www.invisionapp.com/inside-design/statistics-on-user-experience/
[5] https://developers.google.com/search/blog/2013/04/5-common-mistakes-with-relcanonical?hl=pl
[6] https://siteefy.com/how-many-websites-are-there/#How-Many-Websites-Are-on-Google
[7] https://siteefy.com/how-many-websites-are-there/