 Sebastian Mioduszewski
Sebastian Mioduszewski W tym artykule zajmiemy się pobieraniem danych z najważniejszych dla każdego pozycjonera narzędzi ze stajni Google – Google Analytics (także w najnowszej jego odsłonie, czyli v4) oraz Google Search Console. Zaczniemy od liczb, które są na co dzień dla nas konieczne. Dodatkowo użyjemy gotowych i darmowych narzędzi, jakimi są biblioteki: searchConsoleR oraz googleAnalyticsR.
Z tego artykułu dowiesz się:
-
Jak instalować potrzebne biblioteki?
-
Jak nie instalować bibliotek, które już masz?
-
Jak pobierać dane z Google Analytics (także jego najnowszej wersji – v4)?
-
Jak zebrać dane z panelu Google Webmaster Tools?
-
Jak zacząć pracę z API udostępnianymi przez Google?
Po lekturze poprzedniego wpisu pamiętasz już (jeśli nie, to zapraszam do lektury – Język programowania R dla każdego SEOwca. Pozycjonuj, programuj i patrz na wyniki):
-
Czym jest R i jak pomoże Ci w pracy
-
Czym są biblioteki w R (i czemu ich potrzebujesz)
Pobieramy dane z Google Search Console
Aby korzystać z biblioteki w R potrzebujemy ją zainstalować (można to ominąć, ale rekomenduję instalację) i załadować do pamięci (dokładnie w tej kolejności). Proces instalacji w większości wypadków trwa do kilkunastu sekund. Mimo tego, w kodzie poniżej, najpierw będziemy sprawdzać czy już nie posiadasz bibliotek, które nas interesują. Jeśli tak, to będziemy od razu przechodzić do kroku drugiego, którym jest załadowanie wybranej biblioteki do pamięci operacyjnej komputera.
Krok 1. Poniższy kod zapisuje jako wektor (przewodnik po typach danych w R: https://towardsdatascience.com/data-types-in-r-8124c3b2afe6) nazwę potrzebnej nam biblioteki:
packages <- c("searchConsoleR"," googleAnalyticsR")
kod 1.1
Krok 2. Sprawdzamy, czy potrzebne biblioteki są zainstalowane na Twoim komputerze (jeśli któraś z koniecznych bibliotek nie jest zainstalowana, to następuje jej instalacja)
install.packages(setdiff(packages, rownames(installed.packages())))
kod 1.2
Krok 3. Autoryzacja. Jest to oczywiste, ale warto przypomnieć, że w ten sposób będziemy mieć dostęp tylko do danych witryn, które są dostępne na naszym koncie Search Console.
Robimy to przez użycie jednej prostej komendy:
scr_auth()
kod 1.3
Kod dla kroków 1, 2 i 3 jest dostępny tutaj.
Następne kroki zależą od tego, czy pierwszy raz na danym komputerze pobieramy dane przy pomocy tej biblioteki.
Za pierwszym razem następuje otwarcie w przeglądarce okna logowania do konta Google. Narzędzie GSC używa autoryzacji poprzez protokół oAuth. Dzięki temu zobaczysz standardowe okno logowania Google.
Po udanym zalogowaniu należy jeszcze wyrazić zgodę na dostęp aplikacji Search Console do Twojego konta Google.
Prośba taka ma miejsce tylko przy pierwszym logowaniu na danym urządzeniu. W jego trakcie tworzony jest plik JSON zawierający dane logowania. Dzięki temu kolejne logowania następują zdecydowanie szybciej (R pobiera już dane logowania zapisane w pliku JSON).
Od tego momentu mamy pełny dostęp do funkcji związanych z:
- Stronami dodanymi do panelu (pobranie listy wszystkich, dodanie do panelu strony, usunięcie z panelu strony)
-
Mapami witryny (pobranie listy wszystkich, dodanie do panelu witryny, usunięcie z panelu witryny)
-
Błędami raportowanymi w panelu (pobranie przykładów błędów zgłoszonych w panelu, pobranie przykładów adresów URL zawierających zgłoszone błędy)
-
Widocznością naszych witryn w Google (dane te możemy zobaczyć w wymiarach):
– data – tutaj dostajemy informacje, dla jakiego dnia otrzymujemy dane
– kraj – dane na temat lokalizacji geograficznej użytkownika, który zobaczył w wynikach wyszukiwania Twoja stronę
– typ urządzenia – na jakim rodzaju urządzenia w wynikach Google nastąpiło wyświetlenie (dostępne wartości to Desktop, Mobile, Tablet)
– strona – podstrona serwisu, która pojawia się w wynikach wyszukiwania
– wyszukiwana fraza – fraza, po wyszukaniu której, strona znalazła się w Google
– co ciekawe, żaden z wymiarów nie jest konieczny (wtedy dostajemy całościowe dane).
Funkcja search_analytics, której zaraz użyjemy, przyjmuje parametry takie jak:
-
adres URL (parametr konieczny)
-
data początkowa – data, od której chcemy pobierać dane (jeśli ustawisz datę, dla której w panelu nie ma danych, zwrócone zostaną po prostu puste wiersze)
-
data końcowa – data, do której chcesz pobrać dane
-
rodzaj wyników wyszukiwania, dostępne są wartości:
– „web” – standardowe wyniki wyszukiwania
– „image” – graficzne wyniki wyszukiwania
– „video” – wyniki wyszukiwania Google w video
-
walk_data – parametr określający, w jaki sposób chcemy pobierać dane. Przyjmuje on jedną z wartości:
– byBatch – ta opcja działa zdecydowanie szybciej, ale zwraca tylko wyniki, dla których analizowana strona uzyskała kliknięcia (czyli nie jest to dobry pomysł, jeśli chcesz sprawdzić, ile strona uzyskała wyświetleń w Google – wszystkie wyświetlenia bez kliknięć zostaną usunięte)
– byDate – jak już wiesz, ta metoda jest dokładniejsza, jednak wymaga więcej czasu (pobranie informacji o około 10 milionach wyświetleń w Google zajęło mi około godziny). Ograniczeniem, jakie jest narzucone na API, jest pobranie jednorazowo do 25 000 wierszy. Na szczęście dla tych, którzy chcą więcej danych, udostępniona jest opcja umożliwiająca pobieranie w kolejce po 25 000 wierszy i łączenie tak zebranych danych.
Jak sobie poradzić z ograniczeniami GSC?
Opisana biblioteka pobiera dane przy pomocy API GSC, dzięki temu możemy ominąć standardowe ograniczenie panelu GSC pozwalającego pobrać do 1000 wierszy w raporcie. Opcja batching pozwala pobrać wszystkie dane. Jak to już opisałem, dane takie są pobierane partiami liczącymi do 25 000 wierszy.
Pobierając dane z GSC musimy liczyć się z możliwością zgubienia części danych. Dzieje się tak ponieważ, jak tłumaczy Google, system stara się zwrócić wyniki w akceptowalnym czasie. Wynika z tego, że przy źle skonstruowanych zapytaniach (angażujących zbyt wiele zasobów Google za jednym razem) część danych może zostać utracona.
Mając powyższą wiedzę, możemy wykonać pierwsze pełne zapytanie o dane GSC.
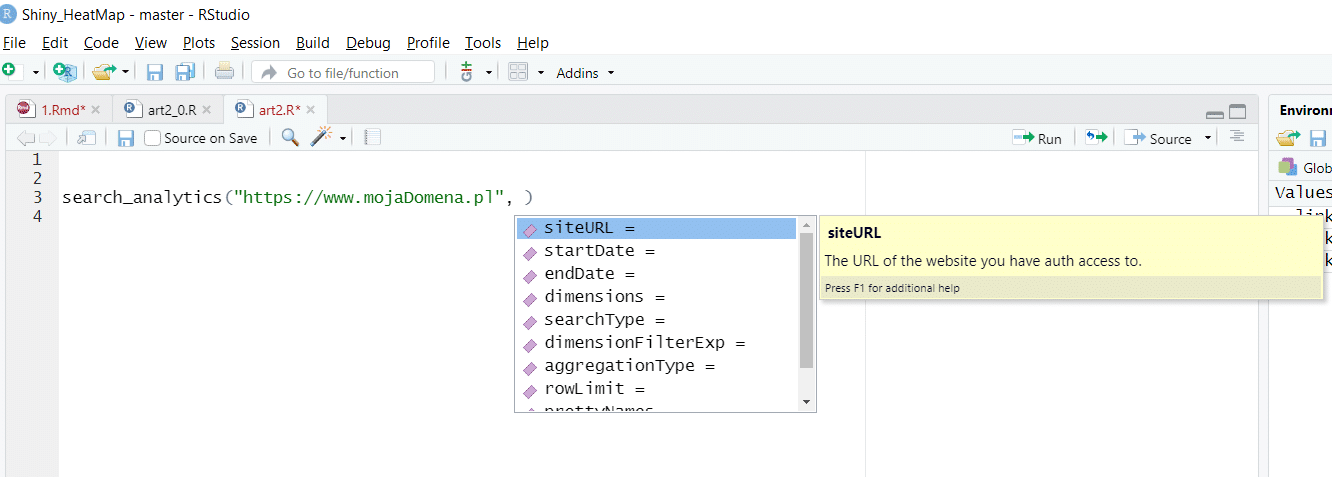
Podpowiedź: Jedną z mocnych funkcji Rstudio jest automatyczne podpowiadanie kodu. Jak widać poniżej, jest to bardzo pomocne przy pracy z biblioteką searchconsoler.
Jak pobrać naprawdę duże ilości danych (ponad milion wierszy) z Google Search Console?
Pobranie takiej ilości danych wymaga:
-
Użycia API (interface GSC ma ograniczenie do 1000 rekordów w raporcie – tak naprawdę pierwszego tysiąca rekordów, co oznacza, że np. zobaczysz tylko najpopularniejsze frazy)
-
Zastosowania w gscR opcji batching (opisana już wyżej)
-
Podzielenia danych – pobranie około 1,5 miliona rekordów zajmuje około 30 minut. Przy dużo większych liczbach możemy potrzebować nawet kilku dni na pobranie wszystkich danych! Rozwiązaniem tego problemu jest stosowanie zastosowanie parametru dimensionFilterExp.
Zawartość tego parametru składa się z filtra i operatora.

Filtr może przyjąć jedną z wartości:
- Country
- Device
- Page
- Query
Dostępne operatory to:
- ~~ (oznaczający zawiera)
- == (oznaczający równa się)
- !~(oznaczający nie zawiera)
- != (oznaczający nie równa się)
Pomysły na filtrowanie:
-
Cały ruch z wybranych urządzeń
-
Cały ruch na wybrane podstrony (np. tylko na stronę główną)
-
Cały ruch z wybranego kraju (np. ruch tylko z Polski)
Filtry, co ważne, można łączyć. Przykładowe filtry złożone, to:
-
Cały ruch z wybranego typu urządzeń na wybraną podstronę
-
Cały ruch od użytkowników z wybranego kraju dla fraz zawierających określony element
Cały skrypt gotowy do skopiowania i uruchomienia dostępny jest tutaj.
Jak szybko pobrać dane z Google Analytics (także w wersji v4) w R?
Krok 1. Tak jak w poprzednim skrypcie, zapisujemy nazwę potrzebnej nam biblioteki.
packages <- c(" googleAnalyticsR")
Krok 2. Tak samo jak opisałem to już przy okazji Google Search Console, sprawdzamy czy potrzebna biblioteka jest zainstalowana na Twoim komputerze.
install.packages(setdiff(packages, rownames(installed.packages())))
Zaczynamy pracę z API Google na poważnie (zakładamy konto w Google Cloud Platform)
Chcąc na poważnie pracować z API dostarczanymi przez Google, powinniśmy założyć konto.
Krok 3. Na tym etapie założymy konto w Google Cloud Platform. Jest to konieczne, aby móc w pełni wykorzystać możliwości API dla Google Analytics. Naszym celem będzie uzyskanie:
- client secret (ciąg znaków dostępny w pliku, który pobierzemy z GCP)
- client ID (ID użytkownika GCP)
W tym celu musimy:
-
Założyć bezpłatne konto w serwisie GCP (tego nie będę tłumaczyć)
-
Uruchomić na koncie GCP obsługę API Google analytics.
W tym celu wybieramy menu Interfejsy API i usługi.
Przechodzimy do opcji Włącz interfejsy API i usługi.

Spośród dostępnych wybieramy poniższe API.

Następnie z menu wybieramy opcję Dane logowania.
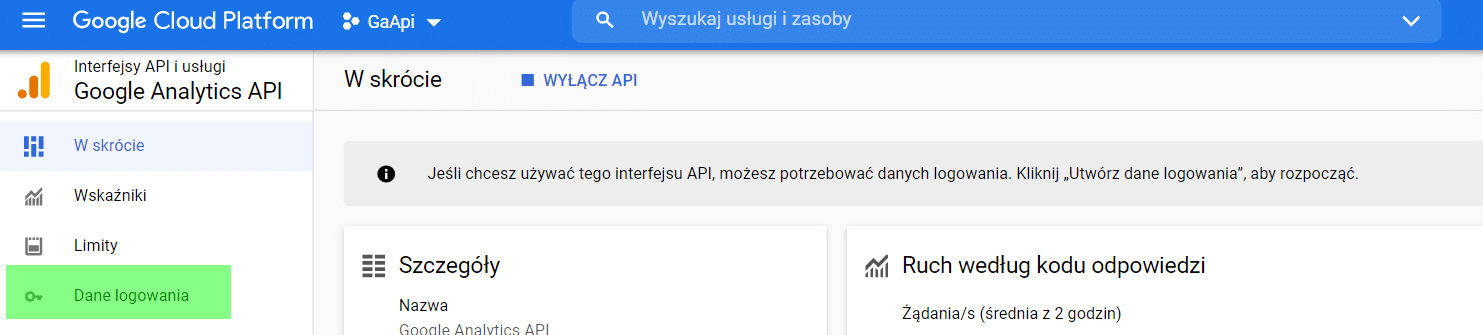
Na pytanie o typ aplikacji wybieramy „Aplikacja komputerowa”.
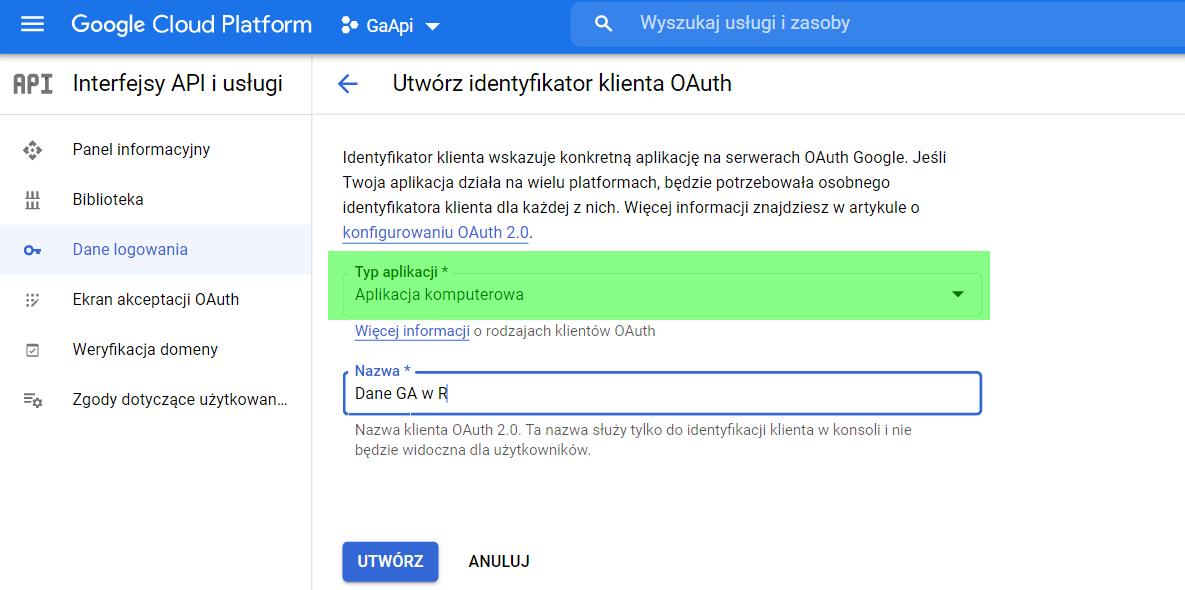
Po uzupełnieniu nazwy i typu aplikacji otrzymujemy identyfikator i tajny klucz dla naszego konta.
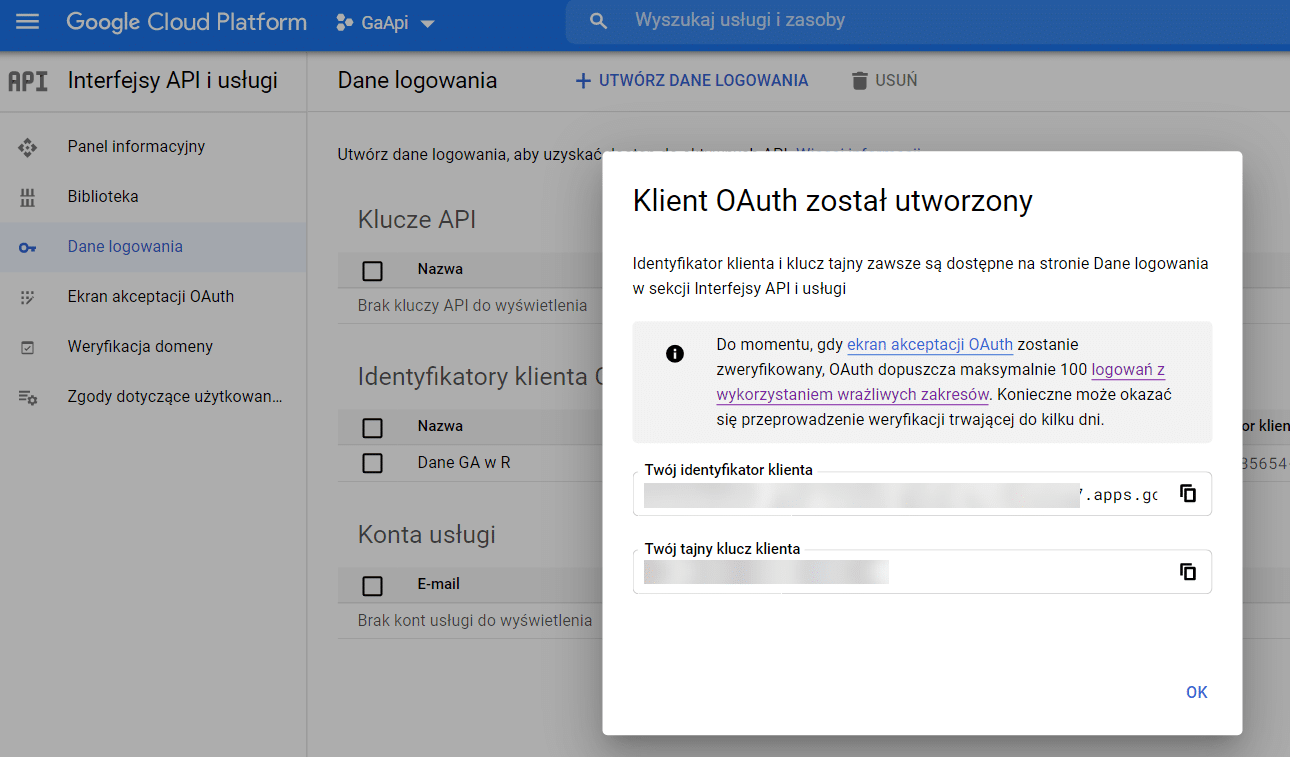
Kolejnym krokiem jest utworzenie konta usługi. Pozwoli to nam wygenerować adres potrzebny do weryfikacji w GA. Konto tej usługi zakładamy poprzez wybranie Administracja > Konta usługi w menu GCP (jak poniżej).
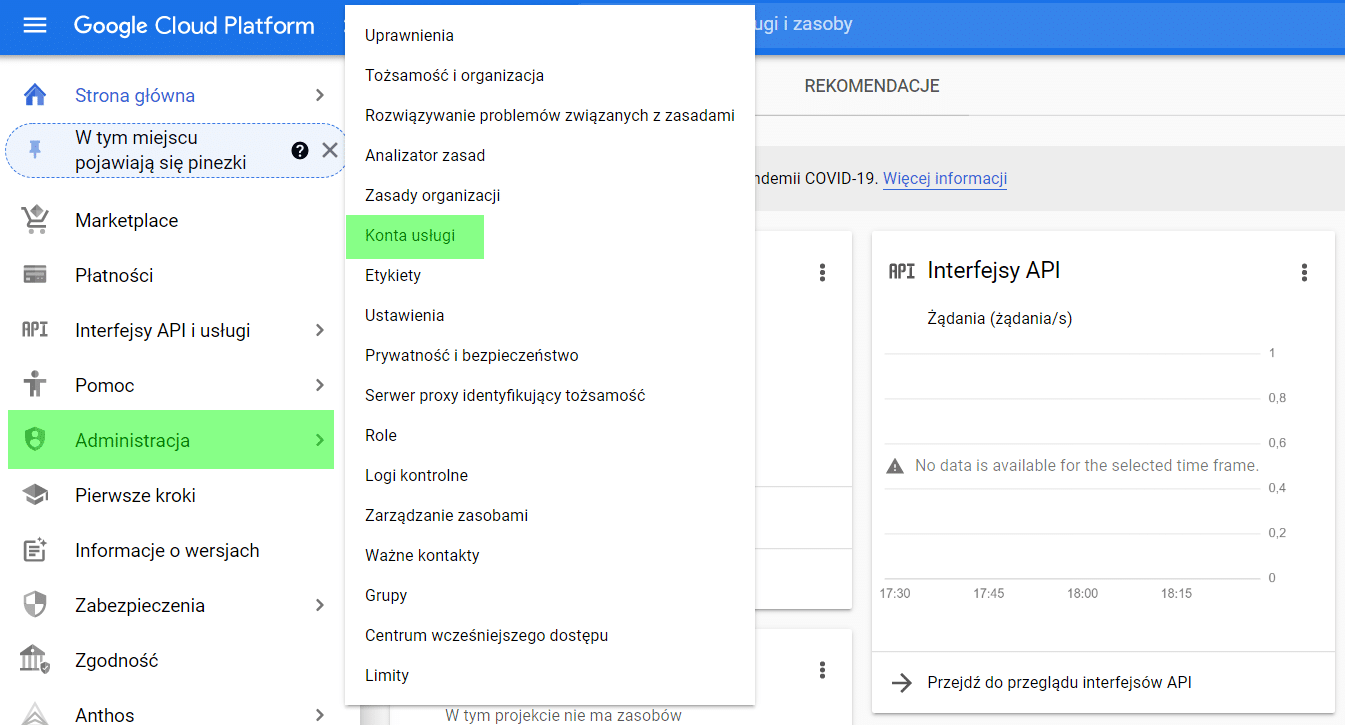
Ostatnim krokiem przygotowawczym jest dodanie adresu użytkownika konta GCP (zaznaczony poniżej) do panelu Google Analytics.
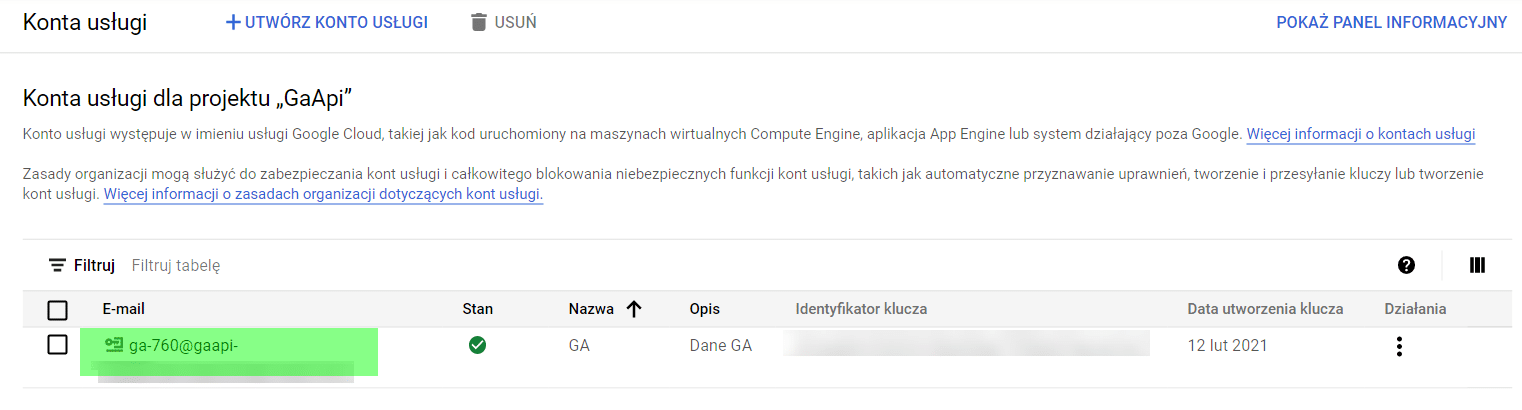
Identyfikator klienta i klucz klienta będą nam potrzebne do autoryzacji. Zapiszemy je jako zmienne w R.
Czym są wymiary i metryki danych
Dla osób mających doświadczenie w pracy z bazami danych, znajomy będzie podział na fakty i wymiary. Ponieważ jeden obraz jest wart więcej niż tysiąc słów, postaram się omówić to obrazowo.
Fakty są zdarzeniami, które są podstawą analizy (np. sprzedaż lub użytkownicy serwisu).
Wymiary opisują fakty. Fakty można rozbijać na wymiary (np. liczba sesji użytkownika).
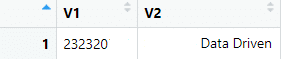
Poniższy podział danych dla GA (pobrane z tej strony) oznacza analizę, gdzie:
Fakt – użytkownicy serwisu
Wymiar – typ użytkownika (tutaj nowy lub powracający)
Metryki – liczba użytkowników, data w formacie (YYYY-MM–DD czyli np. 2021-02-15)
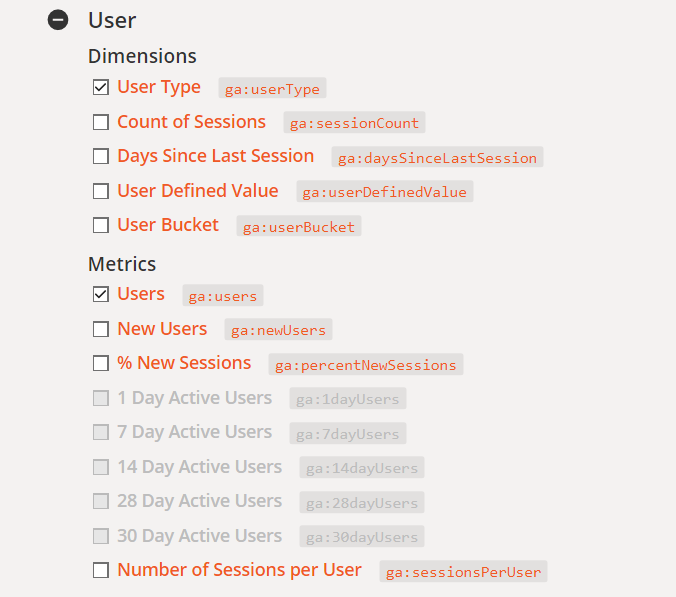
Daje to nam dane takie jak poniższe:
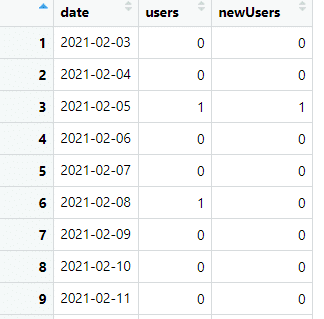
Oraz kod R:

Całość kodu jest dostępna tutaj.
Ograniczenia (próbkowanie oraz ilość danych) w raportach Google Analytics a API
Google Analytics ma ograniczenia związane z próbkowaniem danych (więcej informacji o próbkowaniu tutaj).
Pobierając dane możemy je sprawdzić poprzez użycie parametru anti_sample. Jego zastosowanie powoduje, że system, o ile jest to możliwe (czyli do czasu, gdy nie przekraczamy limitów), będzie zwracał dane nie próbkowane. Poniższy przykład pokazuje informację zwrotną w konsoli R Studio, wskazującą na to, że raport został pobrany bez próbkowania danych.
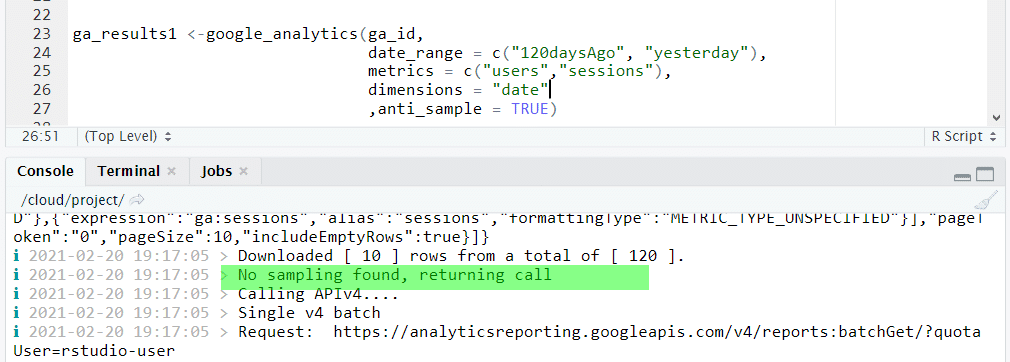
Pobieramy dane
Pobieramy listę kont GA, do których mamy dostęp
Pracę z GA zawsze zaczynam od tego etapu. Pozwala to sprawdzić, czy mój skrypt uzyskał połączenie z API oraz czy mam dostęp do kont, które mnie interesują. Odbywa się to poprzez wywołanie funkcji ga_account_list()
![]()
![]()
Co daje nam obiekt o nazwie my_acc zawierający informacje o widokach danych i kontach GA, do których mamy dostęp. Dzięki temu możemy stworzyć obiekt (w tym wypadku matrycę o nazwie dane_GA) zawierający wszystkie ID widoków danych i nazwy kont, do których mamy dostęp.
![]()
![]()
Daje to nam poniższy obiekt:
Liczba wyników
Domyślnie API zwraca tylko 100 wyników. Liczbę wyników można ustalić poprzez użycie parametru limit. W celu pobrania wszystkich wyników należy parametrowi limit nadać wartość -1.

Zakresy dat
Standardowo zakres dat, jakie pobieramy, ustalamy poprzez parametr date_range. Możliwe jest wybranie więcej niż jednego zakresu danych.

Co bardzo przydatne, zamiast używania konkretnych dat (zawsze w formacie YYYY-MM-DD), możemy używać uniwersalnych parametrów, np. yesterday lub XXdaysAgo. Zwraca on datę XX dni przed dzisiejszą (w miejsce XX wstawiamy konkretną liczbę dni, czyli np. 7 daysAgo daje nam datę sprzed 7 dni).
Filtrowanie danych
Chcąc skrócić czas oczekiwania na dane, warto używać filtrowania. Pozwala ono pobierać tylko wybrane dane. Filtrowanie jest możliwe na dwóch poziomach: metryk i/lub wymiarów (służą do tego parametry met_filters – filtrowanie po metrykach i dim_filters – filtrowanie po wymiarach).
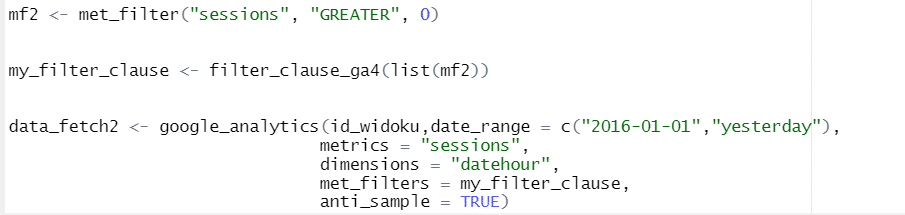
Met_filter() przyjmuje poniższe parametry:
- metric – metryka, przez którą filtrujemy (np. sessions)
- operator – przyjmuje jedną z poniższych wartości :
- „EQUAL” – równa się
- „LESS_THAN” – mniej niż
- „GREATER_THAN” – więcej niż
- „IS_MISSING” – brakuje wartości
- comparisonValue – wartość metryki którą chcemy wyfiltrować lub odfiltrować
- not – jeśli przyjmuje wartość TRUE to w wynikach nie uwzględniamy danych pasujących do filtra.
- Dim_filter() – funkcji tej używamy z parametrami:
- dimension – wymiar przez który filtrujemy (np. rodzaj urządzenia = Desktop lub kraj użytkownika = Polska;
- Operator – działa tak jak w przypadku met_filter i może przyjąć jedną z wartości:
- REGEXP – sprawdzenie, czy podane w expressions pole pasuje do podanego wyrażenia regularnego
- BEGINS_WITH – zaczyna się od podanego filtra
- ENDS_WITH – kończy się podanym filtrem
- PARTIAL – zawiera w sobie podany fragment
- EXACT – ma wartość dokładnie taką samą, jak podana
- NUMERIC_EQUAL – jest liczbą równą podanej
- NUMERIC_GREATER_THAN – jest liczbą większą niż podana
- NUMERIC_LESS_THAN – jest liczbą mniejszą niż podana
- IN_LIST – znajduje się na liście wartości, którą podamy
- Expressions – wyrażenie (liczba lub tekst, którego szukamy w nazwie wymiaru)
- Casesensitive – jeśli ma wartość TRUE, to wielkość liter (duża/mała litera) ma znaczenie
- Not – działa jak w przypadku met_filter.
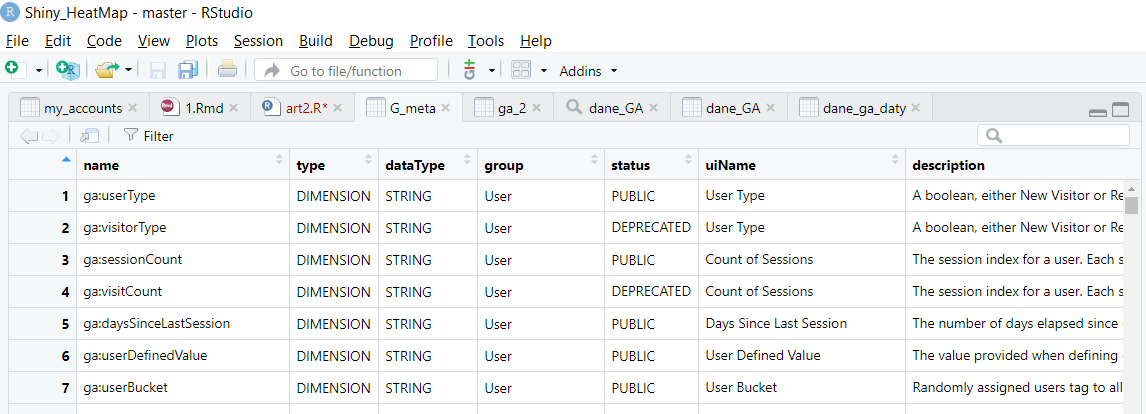
Pełna lista filtrów i wymiarów dostępnych w GA możemy sprawdzić poprzez użycie funkcji ga_meta
Przykład zastosowania:
![]()
![]()
Daje nam obiekt zawierający dokładny opis wszystkich (także tych, które już są wycofane – oznaczone w polu status jako DEPRECATED) wymiarów i metryk.
Po utworzeniu obiektu filtrującego metryki i/lub wymiary należy utworzyć obiekt filtrujący poprzez użycie funkcji filter_clause_ga4. To właśnie tego obiektu używamy w funkcji google_analytics. Dzięki temu możemy budować zaawansowane filtry dla kombinacji więcej niż jednej metryki i/lub wymiaru.
Poniżej filtrujemy dane tak aby zawierały tylko odwiedziny (metryka) z kraju Polska (wymiar o nazwie contry przyjmuje wartość Poland).
Tworzymy filtr dla danych gdzie wymiar country zawiera dokładnie ciąg znaków Poland – czyli odrzucamy wszystkie odwiedziny z krajów innych niż Polska.
![]()
![]()
Tworzymy na podstawie tego filtru obiekt filtrujący:
![]()
![]()
Używamy obiektu filtrującego w funkcji pobierającej dane:

Kod użyty w tej części dostępny jest tutaj.
Podsumowanie
Wielu z nas, pozycjonerów, skupia się na wyszukiwarce Google. Oczywiście narzędzia takie jak Direct Answer dają dużo wiedzy o tym, co dzieje się w wyszukiwarce. Mimo tego podstawą każdej z analiz powinny być dane od samego Google. Swoją przygodę z zastosowaniem programowania w pozycjonowaniu zacząłem właśnie od pobierania danych z opisanego tutaj narzędzia. Dla mnie przełożyło się to na lepsze zrozumienie tego, co dzieje się w wyszukiwarce i koniec końców wyższe pozycje. Jak wszystkie narzędzia, tak i te od Google wymagają zrozumienia możliwości i ograniczeń, aby mogły być dobrze stosowane.
Najważniejsze, o czym musisz pamiętać:
- dane Google analytics nie są w 100% zbieżne z danymi Google Search Console
- dane Google nie udostępniają informacji o konkurentach
- dane Google analytics są zbierane “po Twojej stronie” – dzięki temu możesz przesyłać wiele dodatkowych informacji (np. dla wpisów na blogu nazwisko autora czy nazwę producenta w sklepie)
- dane Google Search Console są zbierane po stronie Google – w związku z tym wystarczy założyć konto, aby zbierać dane.
Dzięki językowi R jesteś w stanie:
- pobrać duże ilości danych (dużo więcej niż zmieścisz w excelu – trochę ponad milion wierszy)
- dane wynikowe wyeksportować (np. do excela)
- połączyć dane z wielu źródeł
- w miarę możliwości ominąć ograniczenia bezpłatnych narzędzi Google
Zachęcam do testowania, komentowania i wdrażania rozwiązań, jakie tutaj opisałem, lub Twoich własnych pomysłów.
Do zobaczenia w SERP-ach!
Dziękujemy za przeczytanie!
Zarejestruj się za darmo i dołącz do ponad 14.000 użytkowników Senuto ????