 Damian Sałkowski
Damian Sałkowski Audyt treści to jedno z zadań, które specjaliści SEO wykonują na co dzień. Rzadko staje się przed sytuacją, w której serwis nie ma treści i można zaplanować wszystko od początku, zgodnie ze sztuką. Najczęściej serwis ma już jakąś treść, którą należy zoptymalizować. W tym artykule pokażę proces od A do Z, który pozwoli Ci przeprowadzić zaawansowany audyt istniejącej treści. Na końcu artykułu znajdziesz również przykład gotowego audytu, na którym możesz bazować podczas pracy na własnych projektach.
Krok 1. Pozyskanie adresów URL
W pierwszym kroku należy pozyskać wszystkie adresy URL, które zawierają opublikowane treści. W tym przypadku będziemy robić audyt treści na blogu Senuto. Adresy URL można pozyskać na kilka sposobów.
Sposób numer 1: crawl serwisu wykonany za pomocą takiego narzędzia jak Screaming Frog czy Sitebulb.
Sposób numer 2: pozyskanie adresów z mapy strony XML. W przypadku witryny Senuto mamy oddzielną mapę strony, która zawiera wszystkie posty na naszym blogu (https://www.senuto.com/pl/post-sitemap.xml). Taką mapę generują wszystkie popularne wtyczki do WordPressa. Jeśli nie masz mapy, która zawiera wyłącznie wpisy blogowe, musisz poddać adresy dodatkowej obróbce. Kiedy już masz adres sitemapy, możesz wykorzystać Google Sheets do zaczytania adresów.
Wykorzystuje tu formułę:
=IMPORTXML("https://www.senuto.com/pl/post-sitemap.xml", "//*[local-name() ='url']/*[local-name() ='loc']")

*Po kilku sekundach w arkuszu powinny pojawić się adresy URL z sitemapy. Jeśli formuła nie zadziała, zamień “,” na “;”.
Sposób numer 3: Pobranie adresów URL z Senuto. W raporcie pozycje możesz założyć filtr, który pokaże tylko adresy URL zawierające blog. W ten sposób pominiesz jednak artykuły, które nie są widoczne na żadne frazy kluczowe.
Nie masz jeszcze konta w Senuto?
Kliknij >>tutaj<< i korzystaj za darmo przez 2 tygodnie!
Przed przejściem do kolejnego kroku dodaj jeszcze identyfikator numeryczny do każdego adresu URL. Ten identyfikator pozwoli łączyć dane dla adresów URL z wielu źródeł.

Doszliśmy do momentu, w którym mamy już zebrane wszystkie adresy URL artykułów z bloga. Możemy przejść do dalszego kroku.
Krok 2. Podstawowe informacje o adresach URL
W tym kroku chcemy pobrać podstawowe informacje o adresach URL, które na późniejszym etapie będą nam potrzebne. Chodzi tu o:
- Znaczniki title
- Nagłówki
- Daty publikacji
- Linki kanoniczne
- Znaczniki meta robots
- Odległość od strony głównej
- Długość treści
- Liczby linków wewnętrznych
- Liczby linków zewnętrznych
- Inne elementy
Jedyny sposób na określenie tych wszystkich danych to zrobienie crawlu serwisu (np. za pomocą Screaming Frog). Jeśli jednak pominiemy w tym wszystkim linki, to możemy ograniczyć się tylko do pracy w Google Sheets. Poniżej znajdziesz formuły, które pobiorą te dane do Arkusza Google.
- Znacznik title:
=IMPORTXML(B2,"//title")
– w B2 znajduje się URL. Przeciągając formułę w dół, zastosujemy ją dla wszystkich adresów URL.

*W przypadku listy zawierającej więcej niż 200 adresów URL ten sposób się nie sprawdzi.
- Znacznik H1:
=IMPORTXML(A2,"//h1")
– W A2 znajduje się URL. Formuła pobierze wszystkie dopasowane elementy (wszystkie nagłówki H1). Jeśli chcemy pobrać tylko pierwszy nagłówek H1, powinniśmy użyć formuły
=IMPORTXML(A2,"(//h1)[1]")
- Znaczniki H2:
=IMPORTXML(A2,"//h2")
- Link kanoniczny:
=IMPORTXML(A2,"//link[@rel='canonical']/@href")
- Znacznik meta robots:
=IMPORTXML(A2,"//meta[@name='robots']/@content")
W wielu przypadkach do audytu przydać mogą nam się dodatkowe elementy ze strony takie jak: autor tekstu, data jego publikacji, liczba komentarzy, kategoria, tagi etc. W tym przypadku również możemy się posłużyć Google Sheets. W formule Import XML możemy podać ścieżkę xPath, z której arkusz ma pobrać dane. Poniżej widać to na przykładzie bloga Senuto.
Taką ekstrakcję możemy wykonać dla dowolnego elementu ze strony. W narzędziach takich jak Screaming Frog również jest to możliwe i działa w taki sam sposób. Przy konfiguracji crawla w menu configuration >> custom >> extraction możemy określić dane, które chcemy pobrać.
Jeśli pobrałeś do swojego audytu daty publikacji treści, to w oddzielnej kolumnie użyj formułę =TODAY(), która wstawi do wiersza wartość dzisiejszej daty. Następnie odejmij tę datę od daty publikacji artykułu.

Ten konkretny tekst ma dokładnie 2 dni. Posłuży nam to potem do zbadania zależności pomiędzy widocznością tekstów a datą ich publikacji.
Wszystkie dane, które tu opisałem znajdziesz w szablonie Google Docs, który znajduje się na końcu artykułu. Do ich zebrania użyłem narzędzia Screaming Frog oraz formuł Google Sheets.
Na końcu artykułu znajdziesz również gotowy szablon do wykorzystania podczas własnego audytu.
Wskazówka: w Senuto pracujemy właśnie nad narzędziem, które pozwoli robić takie operacje na Twojej liście adresów URL. Powinno się ono pojawić na początku 2021 roku.
Krok 3. Dane o widoczności adresów URL
W tym kroku zbieramy dane o widoczności adresów URL. W dwóch wymiarach:
- Statystyki – informacja, na ile fraz kluczowych w TOP3/TOP10 widoczne są nasze adresy URL
- Frazy – informacja, na jakie frazy widoczne są poszczególne adresy
Wykorzystamy tu narzędzie Analiza URL w Senuto, które zostało stworzone do tego celu.
W pierwszym kroku pobieram statystyki dla listy adresów URL.

Dane importuję do bazowego pliku Google Sheets i za pomocą funkcji WYSZUKAJ.PIONOWO dopasowuję dane. Doszły nam 3 kolumny:
- TOP 3 – liczba fraz kluczowych, które adres URL ma w TOP 3
- TOP 10 – liczba fraz kluczowych, które adres URL ma w TOP 10
- Widoczność – estymowana miesięczna liczba wizyt dla artykułu z SEO
W drugim kroku skorzystam ponownie z tego samego narzędzia, ale zamiast statystyk pobiorę wszystkie frazy, na które widoczne są adresy URL z listy. Frazy umieszczam w oddzielnej zakładce.
Krok 4. Dane o frazach, na które widoczne są adresy URL
W kolejnym kroku do naszego pliku dodamy informację o frazach, na które widoczne są nasze artykuły.
Znów posłużymy się tu tym samym narzędziem w Senuto – Analiza URL (zamiast trybu statystyki wybierz tryb frazy kluczowe).
Frazy, które pobrałem z narzędzia, znajdują się w zakładce “frazy” w pliku.
Krok 5. Dane o linkach z ahrefsa
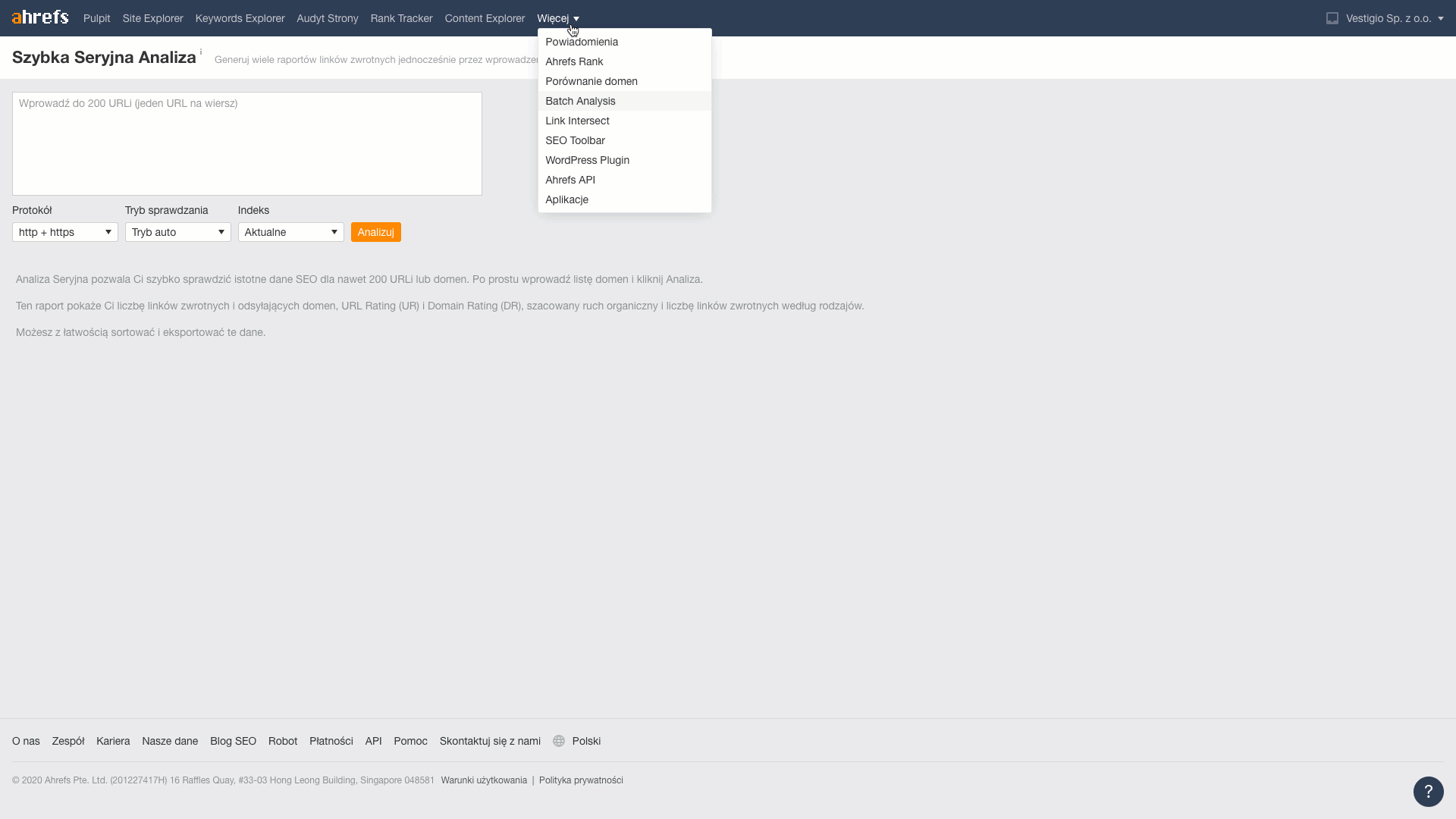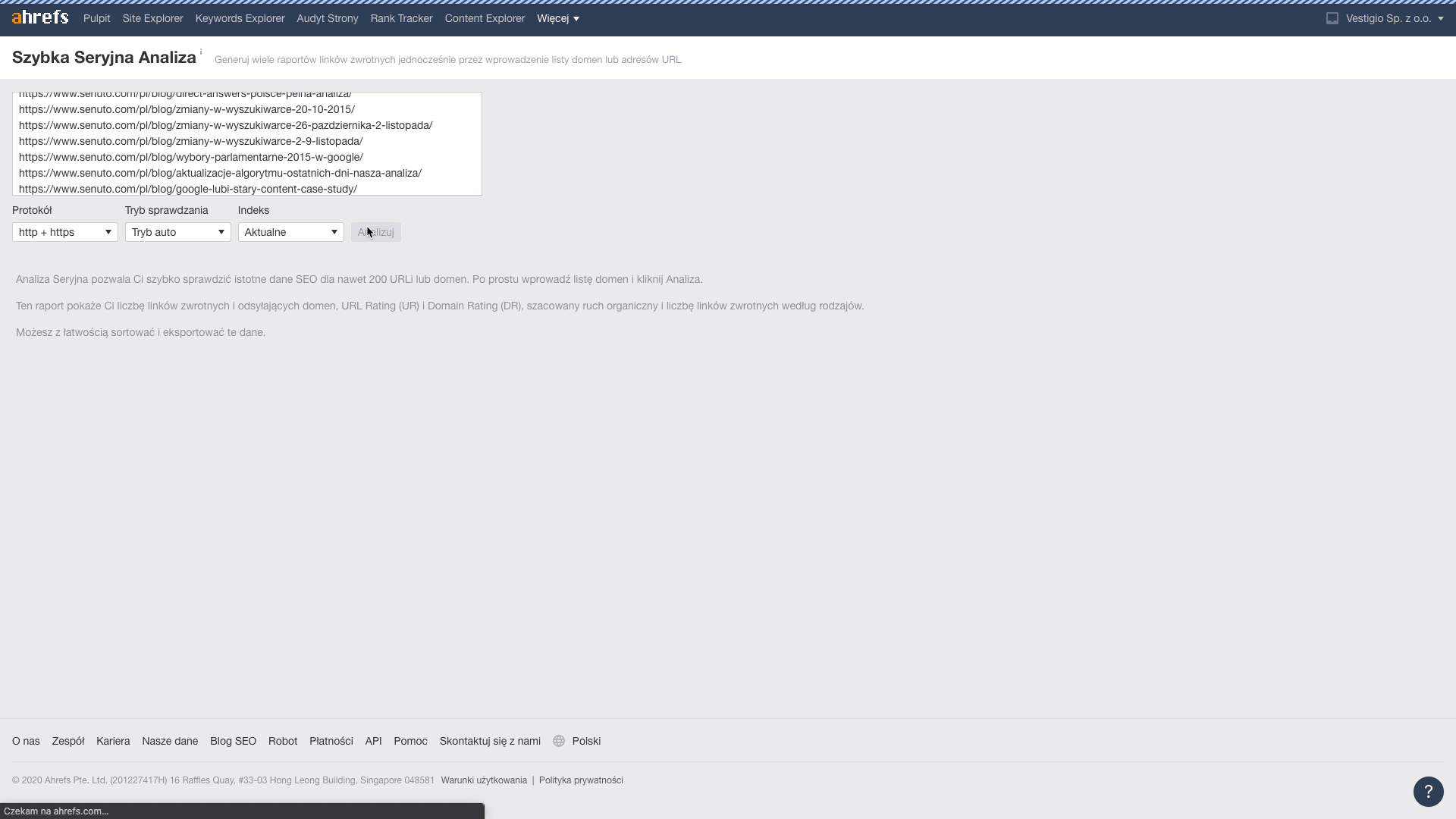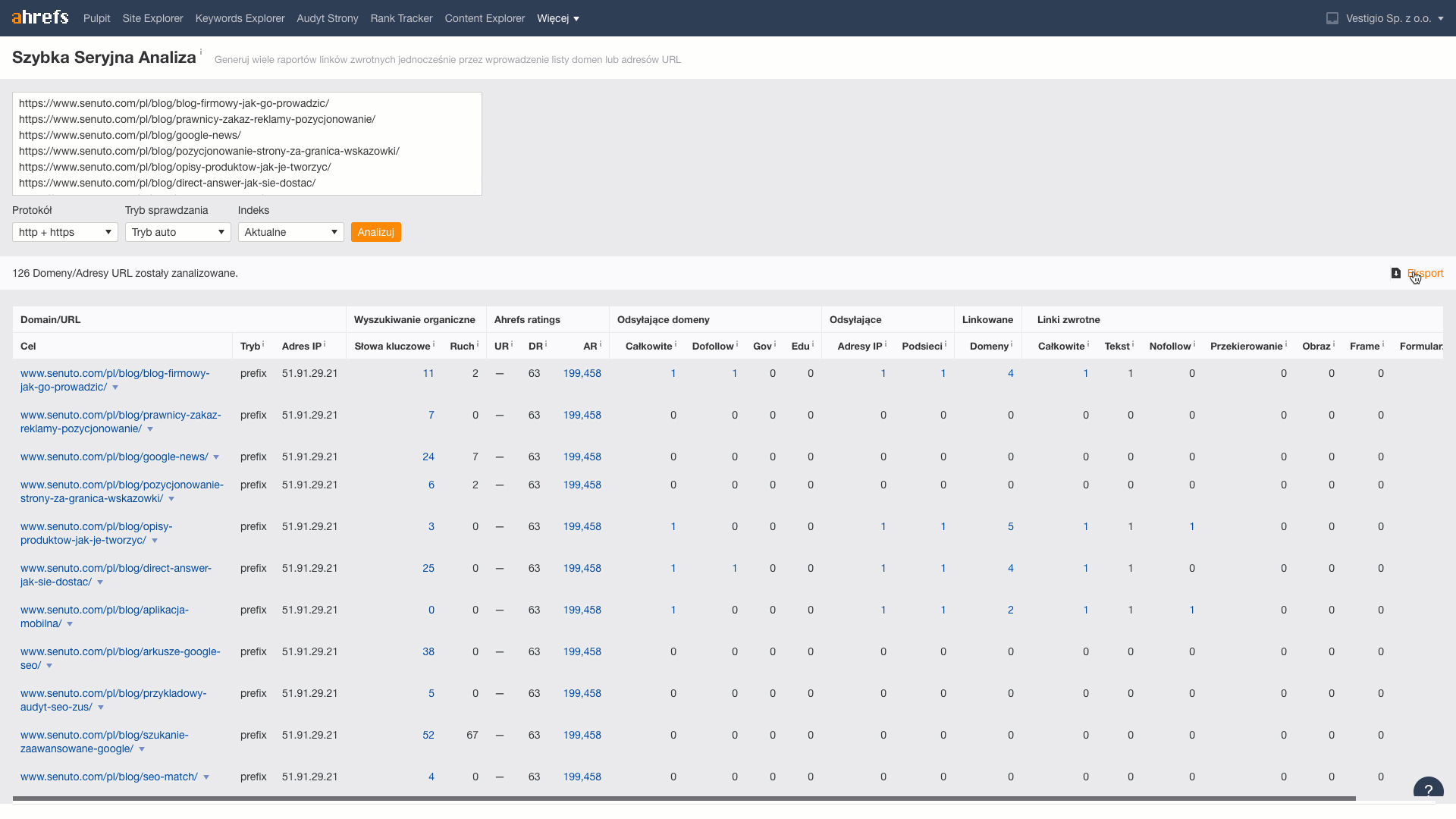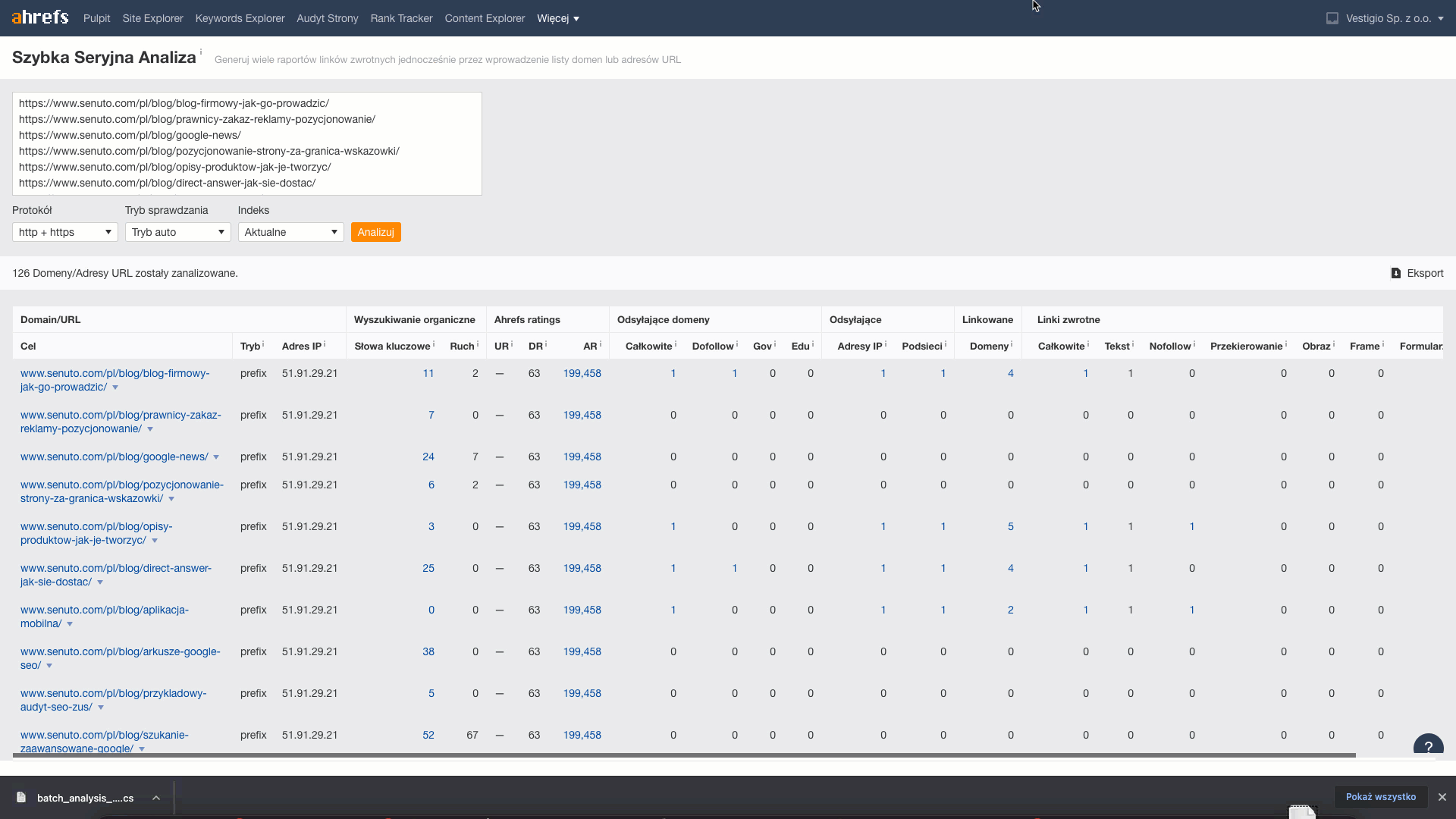
W tym kroku dla każdego adresu URL pobieramy informację o liczbie linków i domen, które do niego prowadzą. W tym celu wykorzystamy narzędzie Batch Analysis wchodzące w skład narzędzia Ahrefs.
Z pobranych danych do arkusza przenoszę metryki: Reffering domains (informacja z ilu domen linki prowadzą do artykułu), Total backlinks (liczba linków prowadzących do artykułu).
Krok 6. Keyword Gap
W tym kroku chcemy dla każdego artykułu wyznaczyć frazy kluczowe, na które powinien być widoczny, a jeszcze nie jest. Taką analizę nazywa się powszechnie analizą “keyword gap”.
Do tego celu potrzebować będziemy informacji o głównej frazie artykułu – to słowo kluczowe, na które artykuł powinien być widoczny (kolumna Main Keyword w arkuszu). W tym przypadku zrobiłem to ręcznie, ale możesz też użyć nagłówków H1, tagów czy innych elementów, które z reguły zawierają tę frazę. Nie każdy artykuł na blogu pisany jest z zamysłem SEO, a więc nie każdy w naszym arkuszu ma główną frazę. Dodałem dodatkową kolumnę “Tekst SEO?” aby wiedzieć, który tekst pisany był z zamysłem SEO, a który nie.
Proces do pobrania tych danych wygląda następująco:
- Krok 1 – pobieram TOP 20 wyników z SERP dla każdej frazy oznaczonej jako main keyword.
- Krok 2 – pobieram wszystkie frazy, na które widoczne są adresy URL znajdujące się w TOP 20 na wybrane wcześniej frazy.
- Krok 3 – sprawdzam pozycję mojej domeny na te frazy.
- Krok 4 – łączę dane za pomocą identyfikatora tak, aby wiedzieć, które frazy przypisane są do którego artykułu.
W ten sposób w zakładce “keyword gap” pojawiły się 9482 frazy kluczowe. Na bazie tych informacji jestem teraz w stanie wyliczyć potencjał graniczny każdego artykułu (maksymalną średnią miesięczną liczbę wyszukiwań dla artykułu) oraz liczbę fraz, na którą powinien być on widoczny.
W tym celu tworzymy tabelę przestawną (zakładka “Keyword GAP – Statystyki”). W tej zakładce dla każdego ID wyznaczyliśmy liczbę fraz przypisaną do artykułu oraz potencjał wyznaczony jako suma wyszukiwań wszystkich fraz. Następnie do zakładki “Dane” zaciągam te informacje (kolumna AI oraz AJ) i dodaję kolumnę AK, która liczy maksymalny potencjał ruchu dla danego artykułu oraz kolumnę AL, która liczy, jaki potencjał dany artykuł już wykorzystał.
Jeśli posortuję teraz po kolumnie AL, to mogę uszeregować artykuły w kolejności największego pozostałego potencjału do wykorzystania. Mogę również zrobić podwójne sortowanie po kolumnie AK oraz AL, aby wyznaczyć artykuły z wysokim potencjałem, w którym wykorzystany potencjał jest niski. Natomiast za pomocą ID w zakładce “Keyword gap” mogę wyznaczyć frazy, których w danym artykule brakuje.
Wskazówka: Obecnie pracujemy w Senuto nad narzędziem, które pozwoli Ci pobrać TOP 20 wyników na dowolną frazę. Taki dodatek pojawi się również w naszej integracji z Google Sheets. W międzyczasie możesz to zrobić za pomocą narzędzia Historia SERP lub API Senuto.
Krok 7. Analiza konkurentów
W naszej analizie musimy przyjrzeć się również konkurencji. We wcześniejszym kroku pobrałem TOP 20 wyników z SERP na każdą frazę z audytu. Dane te znajdują się w zakładce “TOP 20”. Dla każdego z adresów URL pobrałem również długość jego treści.
Ta informacja pozwoli nam określić, czy długość naszej treści względem konkurencji nie jest zbyt krótka. Z tej zakładki utworzyłem 2 tabele przestawne w zakładce “Długość treści” – pierwsza tabela mierzy średnią długość treści w TOP 20, natomiast druga średnią długość treści w TOP 3. Przeniosłem te dane również do zakładki “Dane” do kolumn Y-AC gdzie wyznaczyłem również na bazie średniej długości treści z TOP 3, czy tekst nie jest za krótki.
Pamiętaj, że długość treści w większości przypadków nie ma większego znaczenia dla rankingu. Sprawdzimy to w dalszej części tej analizy.
Wskazówka: Obecnie pracujemy w Senuto nad narzędziem, które pozwoli Ci pobrać TOP 20 wyników na dowolną frazę. Taki dodatek pojawi się również w naszej integracji z Google Sheets. W międzyczasie możesz to zrobić za pomocą narzędzia Analiza SERP.
Krok 8. Zależności
Kolejnym krokiem w analizie jest zbadanie zależności pomiędzy różnymi cechami. Dzięki temu dowiemy się, które dane w audycie powinny mieć najwyższy priorytet. Badamy tu korelację liniową dwóch zmiennych. Korelacja operuje w zakresie -1 (brak korelacji) do 1 (silna korelacja). W zakresie >0.3 można już mówić o korelacji dwóch zmiennych.
Korelację znajdziesz w zakładce “Dashboard” w kolumnie B-C w wierszu 92-98. Do wyznaczenia korelacji używamy funkcji =CORREL.
Jak widzisz, w tym przypadku nie występują silne korelacje pomiędzy żadnymi metrykami, co spowodowane jest przez małą ilość danych – próbka to zaledwie nieco ponad 80 artykułów. Widać jedynie korelację pomiędzy liczbą fraz w TOP 10 a długością artykułu – to wydaje się naturalne, ponieważ im dłuższy jest artykuł, tym więcej fraz z długiego ogona łapie. Nie przekłada się to jednak na widoczność.
Krok 9. Dane o ruchu z Google Search Console
Dla każdego adresu URL warto pobrać również informację o tym, jak dużo kliknięć z wyników wyszukiwania miał w ostatnim czasie (w naszym przypadku to 6 miesięcy). Stworzyłem oddzielną zakładkę “Dane GSC”, w której pobrałem te informacje.
Wykorzystałem do tego celu wtyczkę do Google Sheets Search Analytics for Sheets – pobiera ona dane dla wszystkich adresów URL. Za pomocą funkcji WYSZUKAJ.PIONOWO przeniosłem te informacje do zakładki “Dane”.
Krok 10. Duplikaty
Podczas tworzenia audytu zauważyłem, że w trzech przypadkach main keyword dla artykułów jest taki sam, co oznacza, że trzy artykuły mają swoją kopię.
Przeniosłem dane za pomocą funkcji query do zakładki “Duplikaty”. W tej zakładce stworzyłem kolumnę J i w pierwszym wierszu wstawiłem wartość “1”. W kolejnym wstawiłem formułę:
=if(C3=C2, J2, J2+1)
– ta formuła sprawdza, czy wartość wiersza C3 jest równa wartości wiersza C2 (czy main keyword jest taki sam). Jeśli wartości są identyczne, to pobiera wartość wiersza J2 (ID); jeśli nie, to dodaje do niego 1. Dzięki temu wiersze, które będą miały ten sam main keyword, będą miały te same ID i łatwo je będzie wyłapać. Mogę teraz zrobić tabelę przestawną po wartości ID oraz liczbie jego wystąpień i zdecydować, co zrobić z tymi treściami.
Prezentacja danych
Ważną częścią każdego audytu jest też prezentacja danych. Dlatego też w audycie znalazła się zakładka “Dashboard”, w której zebrałem wszystkie najważniejsze informacje. Korzystałem tu głównie z funkcji query.
Funkcje Google Sheets, których używaliśmy
Aby sprawnie tworzyć takie audyty jak ten przykładowy, należy umieć poruszać się w środowisku arkuszy kalkulacyjnych (wszystkie działają podobnie). Upewnij się, że potrafisz korzystać z następujących funkcji:
- WYSZUKAJ.PIONOWO: https://support.google.com/docs/answer/3093318?hl=pl
- Tabele przestawne: https://support.google.com/docs/answer/1272900?co=GENIE.Platform%3DDesktop&hl=pl
- Query: https://support.google.com/docs/answer/3093343?hl=pl
- Import XML: https://support.google.com/docs/answer/3093342?hl=pl
- Formatowanie warunkowe: https://support.google.com/docs/answer/78413?co=GENIE.Platform%3DDesktop&hl=pl
Gotowy szablon do pobrania
Chcesz wiedzieć, jak może wyglądać taki audyt w wersji do wysłania klientowi? W takim razie przyjrzyj się przykładowemu audytowi, który przeprowadziłem dla ZUS.pl.
Uwaga! Zwróć uwagę, że powyższy przykład został wykonany 4 lata temu. Od tego czasu w dziedzinie SEO naprawdę dużo się zmieniło. W związku z tym taki dokument warto odświeżyć i dopasować do dzisiejszych standardów. Niemniej – punkt startu masz. I to naprawdę solidny.
Co dalej?
To nie koniec pracy. Dane, które tu zebraliśmy, należy przekuć na wnioski. To, co mi się udało zauważyć, to:
- Niektóre treści na blogu Senuto są zduplikowane (są o tym samym).
- Wykorzystaliśmy tylko 1% całego potencjału, jaki mają artykuły.
- W wielu miejscach artykuły należy uzupełnić o dodatkowe frazy kluczowe (to wiem z analizy keyword gap).
- Duża część artykułów ma poniżej 10 linków wewnętrznych – będziemy musieli nad tym popracować.
Jeśli taki audyt miałby wylądować u klienta, potrzebny byłby dodatkowy plik .pdf z opisem poszczególnych informacji, bądź też spis zadań, które należy zrealizować. Do naszego pliku moglibyśmy zaciągać jeszcze inne informacje, np. nagłówki konkurentów, ich znaczniki title etc. Na tym jednak poprzestaniemy. Moim celem było zaprezentowanie workflow, jakim można się posłużyć. W Senuto pracujemy nad takimi narzędziami, które ten workflow będą wspierać, abyś mógł tworzyć audyty treści jak najszybciej.