 Łukasz Rogala
Łukasz Rogala A kúszási költségvetés elemzése minden SEO-szakértő munkaköri feladatai közé tartozik (különösen, ha nagy weboldalakkal foglalkozik). Fontos feladat, amelyet a Google által biztosított anyagok tisztességesen lefednek. Mégis, ahogy a Twitteren is láthatjuk, még a Google munkatársai is lekicsinylik a crawl költségvetés szerepét a jobb forgalom és rangsorolás elérésében:
Igazuk van ebben a kérdésben?
Legfontosabb megállapítások
- A Google crawl költségvetés koncepciója a weboldalak gyakoriságát és az indexelhető URL-ek számát jelenti, melyek a weboldal népszerűségétől és technikai állapotától függően változnak.
- A weboldalak technikai szempontból történő optimalizálása, mint például a sebesség javítása és a hibák kijavítása, növelheti a crawl költségvetést és javíthatja az indexelést.
- A Google Search Console és a Senuto Visibility Analysis hasznos eszközök a crawl költségvetés elemzésében, segítve az SEO szakembereket a weboldaluk teljesítményének javításában.
- A tartalom és a backlinkek minőségének növelése hozzájárulhat a crawl költségvetés növekedéséhez, ami elősegítheti a jobb online láthatóságot és rangsorolást.
- A crawl költségvetés optimalizálása fontos a nagy weboldalak számára, mivel segít a tartalom gyorsabb felfedezésében és a keresőmotorokban való jobb rangsorolás elérésében.
Hogyan dolgozik és gyűjt adatokat a Google?
Ha már a témánál tartunk, idézzük fel, hogyan gyűjti, indexeli és rendszerezi az információkat a keresőmotor. E három lépés szem előtt tartása elengedhetetlen a későbbi, a weboldalon végzett munka során:
1. lépés: a kúszás. Az online források átfésülése azzal a céllal, hogy felfedezzük – és átnavigáljuk – az összes létező linket, fájlt és adatot. Általában a Google a világháló legnépszerűbb helyeivel kezdi, majd más, kevésbé trendi források átvizsgálását folytatja.
2. lépés: Indexelés. A Google megpróbálja meghatározni, hogy miről szól az oldal, és hogy az elemzett tartalom/dokumentum egyedi vagy duplikált anyagnak minősül-e. Ebben a szakaszban a Google csoportosítja a tartalmat, és fontossági sorrendet állít fel (a rel=”canonical” vagy rel=”alternate” tagokban található javaslatok olvasásával vagy más módon).
3. lépés: Kiszolgálás. A szegmentálás és indexelés után az adatok a felhasználói lekérdezésekre válaszul megjelennek. Ekkor a Google az adatokat a megfelelő módon, például a felhasználó tartózkodási helyének figyelembevételével rendezi.
Fontos: a rendelkezésre álló anyagok közül sokan figyelmen kívül hagyják a 4. lépést: tartalom megjelenítés. Alapértelmezés szerint a Googlebot a szöveges tartalmakat indexeli. A webes technológiák folyamatos fejlődésével azonban a Google-nek új megoldásokat kellett kidolgoznia, hogy ne csak „olvasson”, hanem „lásson” is. Erről szól a renderelés. Azt szolgálja, hogy a Google jelentősen javítsa elérését az újonnan indított webhelyek között, és bővítse az indexet.
Megjegyzés: A tartalom renderelésével kapcsolatos problémák lehetnek az oka a sikertelen lánctalálási költségvetésnek.
Próbáld ki a Senuto Suite-ot 14 napig ingyen
Próbáld ki a Senuto Suite-ot 14 napig ingyenMi a crawl költségvetés?
A lánctalpas költségvetés nem más, mint az a gyakoriság, amellyel a lánctalpasok és a keresőmotorok botjai indexelni tudják a webhelyét, valamint az URL-ek teljes száma, amelyekhez egyetlen lánctalpas művelet során hozzáférhetnek. Képzelje el a crawl-büdzsét úgy, mint krediteket, amelyeket egy szolgáltatásra vagy egy alkalmazásra költhet. Ha nem emlékszik arra, hogy „feltöltse” a crawl-büdzsét, a robot lelassul, és kevesebb látogatást fog fizetni Önnek.
A SEO-ban a „töltés” a backlinkek megszerzésébe vagy egy weboldal általános népszerűségének javításába fektetett munkára utal. Következésképpen a crawl költségvetés szerves része a web teljes ökoszisztémájának. Ha jó munkát végez a tartalom és a backlinkek terén, akkor emeli a rendelkezésre álló crawl-büdzsé határát.
A Google a forrásaiban nem vállalkozik a crawl-büdzsé kifejezett meghatározására. Ehelyett a lánctalanítás két alapvető összetevőjére mutat rá, amelyek a Googlebot alaposságát és látogatásainak gyakoriságát befolyásolják:
- crawl rate limit;
- crawl igény.
Mi a crawl ráta limit és hogyan ellenőrizze?
A legegyszerűbben fogalmazva, a crawl rate limit az a számú egyidejű kapcsolat, amelyet a Googlebot létrehozhat, amikor az Ön webhelyét feltérképezi. Mivel a Google nem akarja rontani a felhasználói élményt, korlátozza a kapcsolatok számát, hogy fenntartsa webhelye/szerverének zavartalan teljesítményét. Röviden, minél lassabb a webhelye, annál kisebb a crawl rate limit.
Fontos: A feltérképezési limit a webhelye általános SEO-állapotától is függ – ha webhelye sok átirányítást, 404/410-es hibát vált ki, vagy ha a szerver gyakran küld vissza 500-as státuszkódot, a kapcsolatok száma is csökkenni fog.
A lánctalálási sebességhatár adatait a Google Search Console-ban, a Crawl Stats jelentésben elérhető információkkal elemezheti.
Crawl demand, avagy a webhely népszerűsége
Míg a crawl rate limit a weboldal technikai részleteinek csiszolását igényli, addig a crawl demand a weboldal népszerűségét jutalmazza. Durván szólva, minél nagyobb a weboldalad körül (és rajta) a felhajtás, annál nagyobb a lánctalpas kereslet.
Ebben az esetben a Google két dolgot vesz számba:
- Általános népszerűség – a Google szívesebben futtat gyakori feltérképezéseket azokon az URL-eken, amelyek általában népszerűek az interneten (nem feltétlenül azokon, amelyeken a legtöbb URL-ről van backlink).
- Az indexadatok frissessége – A Google arra törekszik, hogy csak a legfrissebb információkat mutassa be. Fontos: Az egyre több új tartalom létrehozása nem jelenti azt, hogy a teljes lánctalálási költségvetési korlátod emelkedik.
A feltérképezési költségvetést befolyásoló tényezők
Az előző részben a crawl-büdzsét a crawl-ráta limit és a crawl-igény kombinációjaként definiáltuk. Ne feledje, hogy mindkettőről egyszerre kell gondoskodnia, hogy biztosítsa webhelye megfelelő feltérképezését (és ezáltal indexelését).
Az alábbiakban egy egyszerű listát talál a crawl költségvetés optimalizálása során figyelembe veendő pontokról
- Server – a fő kérdés a teljesítmény. Minél kisebb a sebességed, annál nagyobb a kockázata annak, hogy a Google kevesebb erőforrást rendel az új tartalmad indexeléséhez.
- Server válaszkódok – minél nagyobb a 301-es átirányítások és 404/410-es hibák száma a webhelyeden, annál rosszabb indexelési eredményeket kapsz. Fontos: Legyen résen az átirányítási hurkok tekintetében – minden egyes „ugrálás” csökkenti a webhelye feltérképezési sebességének határértékét a robot következő látogatásakor.
- Blokkok a robots.txt-ben – ha a robots.txt direktívákat megérzésre alapozza, akkor indexelési szűk keresztmetszeteket okozhat. Az eredmény: megtisztítja az indexet, de az új oldalak indexelési hatékonyságának rovására (amikor a blokkolt URL-ek szilárdan beágyazódtak a teljes weboldal szerkezetébe).
- Facetes navigáció / munkamenet-azonosítók / bármilyen paraméter az URL-ekben – a legfontosabb, hogy figyeljen azokra a helyzetekre, amikor egy egy paramétert tartalmazó cím tovább paraméterezhető, korlátozások nélkül. Ha ez megtörténik, a Google végtelen számú címhez jut el, és az összes rendelkezésre álló erőforrást a weboldalunk kevésbé jelentős részeire költi.
- Duplikált tartalom – a másolt tartalom (a kannibalizálás mellett) jelentősen rontja az új tartalom indexelésének hatékonyságát.
- Vékony tartalom – ez akkor fordul elő, ha egy oldalon nagyon alacsony a szöveg és a HTML aránya. Ennek következtében a Google az oldalt úgynevezett Soft 404-ként azonosíthatja, és korlátozhatja az oldal tartalmának indexálását (még akkor is, ha a tartalom értelmes, ami például egy egyetlen terméket bemutató, egyedi szöveges tartalom nélküli gyártói oldal esetében előfordulhat).
- Szegény belső hivatkozás vagy annak hiánya.
.
.
Hasznos eszközök a crawl költségvetés elemzéséhez
Mivel a crawl költségvetéshez nincs viszonyítási alap (ami azt jelenti, hogy nehéz összehasonlítani a weboldalak közötti limiteket), felszerelkezzen egy sor olyan eszközzel, amelyet az adatgyűjtés és elemzés megkönnyítésére terveztek.
Google Search Console
A GSC szépen fejlődött az évek során. A crawl költségvetés elemzése során két fő jelentést kell megvizsgálnunk: Index Coverage és Crawl stats.
Indexlefedettség a GSC-ben
A jelentés egy hatalmas adatforrás. Nézzük meg az indexelésből kizárt URL-ekre vonatkozó információkat. Ez egy remek módja annak, hogy megértsük a probléma nagyságrendjét.
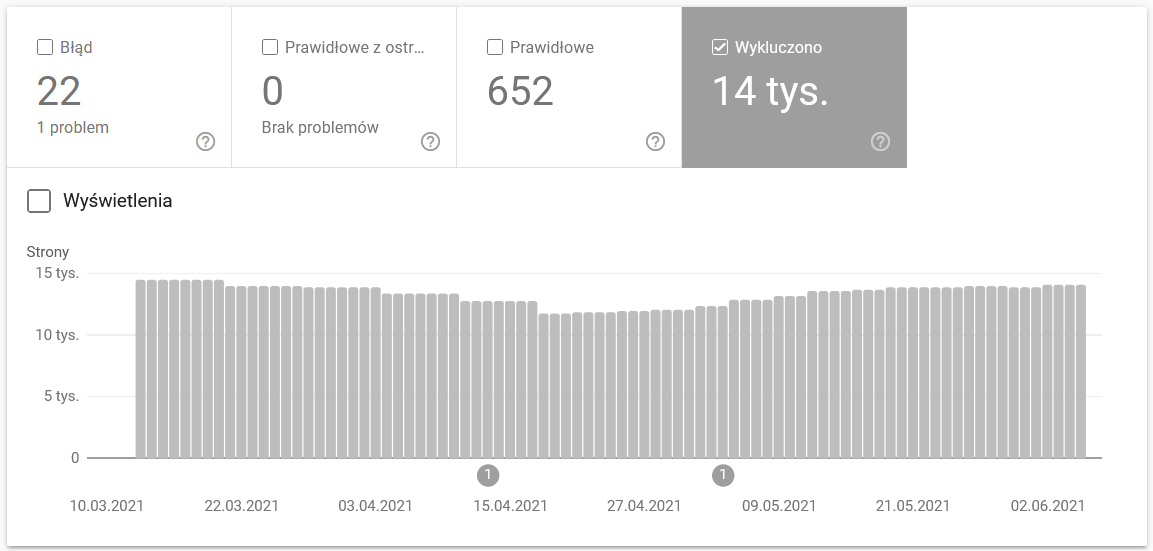
A teljes jelentés egy külön cikket érdemel, ezért most koncentráljunk a következő információkra:
- A „noindex” taggel kizárt oldalak – Általában a több noindex oldal kevesebb forgalmat jelent. Ami felveti a kérdést – mi értelme ezeket a webhelyen tartani? Hogyan lehet korlátozni a hozzáférést ezekhez az oldalakhoz?
- Crawled – currently not indexed – ha ezt látja, ellenőrizze, hogy a tartalom helyesen renderelődik-e a Googlebot szemében. Ne feledje, hogy minden ilyen státuszú URL elpazarolja a feltérképezési költségvetését, mert nem generál szerves forgalmat.
- Felfedezett – jelenleg nem indexelt – az egyik legriasztóbb probléma, amit érdemes a prioritási lista élére helyezni.
- Duplikátum felhasználó által kiválasztott kanonikus nélkül – minden duplikált oldal rendkívül veszélyes, mivel nem csak a feltérképezési költségvetését károsítja, hanem növeli a kannibalizáció kockázatát is.
- Duplikátum, a Google más kanonikust választott, mint a felhasználó – elméletileg nem kell aggódni. Elvégre a Google-nak elég okosnak kell lennie ahhoz, hogy helyettünk is jó döntést hozzon. Nos, a valóságban a Google eléggé véletlenszerűen választja ki a kanonikusokat – gyakran vágja le az értékes oldalakat a kezdőlapra mutató kanonikus val.
- Soft 404 – minden „soft” hiba rendkívül veszélyes, mivel kritikus oldalak eltávolításához vezethet az indexből.
- Duplikátum, a beküldött URL-t nem választották kanonikusnak – hasonlóan a felhasználó által kiválasztott kanonikusok hiányáról szóló állapotjelentéshez.
Crawl statisztikák
A jelentés nem tökéletes, és ami az ajánlásokat illeti, erősen javaslom, hogy játsszon a jó öreg szervernaplókkal is, amelyek mélyebb betekintést nyújtanak az adatokba (és több modellezési lehetőséget).
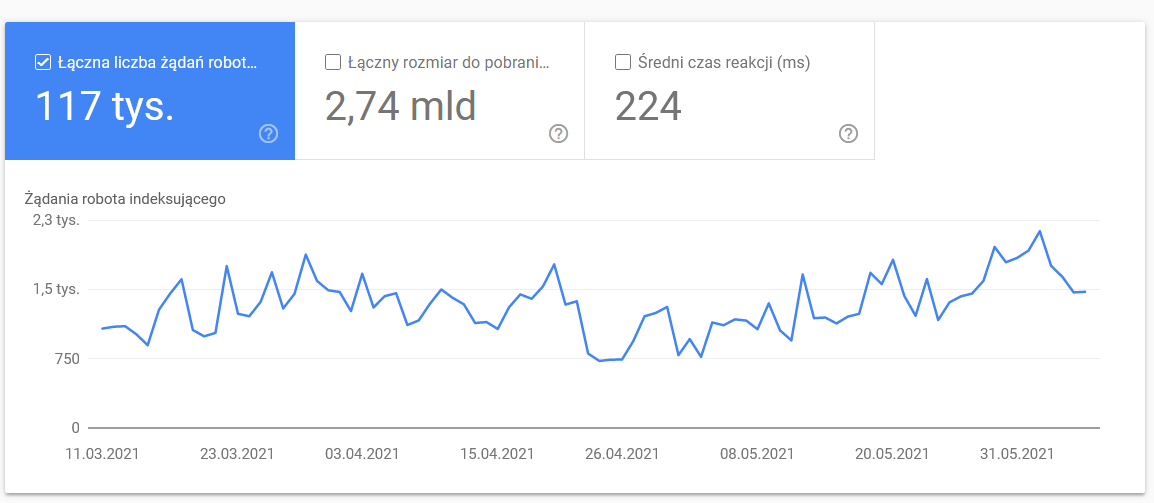
Mint már mondtam, a fenti számokhoz nehéz lesz benchmarkokat keresni. Viszont jó felhívás, hogy közelebbről is megnézd:
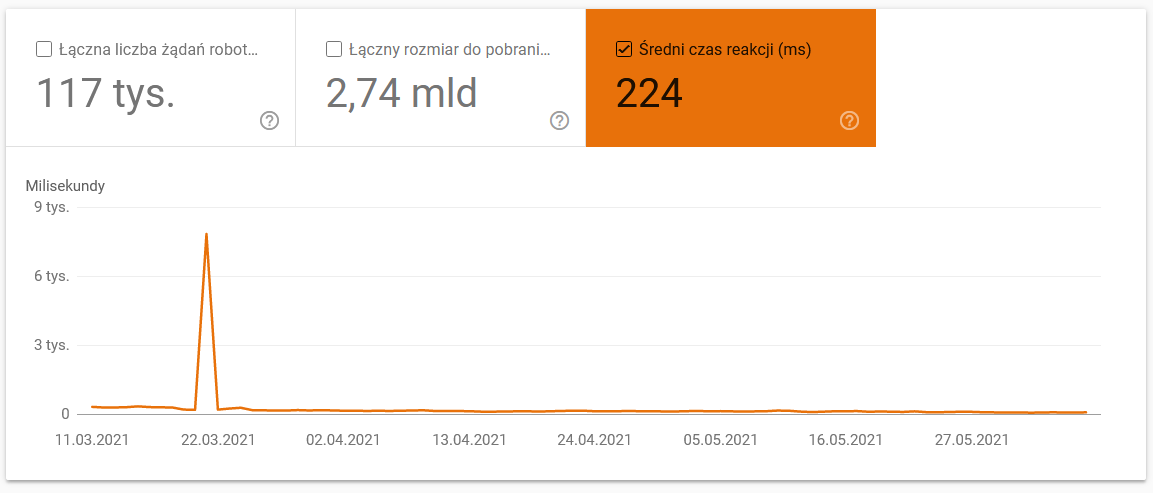
- átlagos letöltési idő. Az alábbi képernyőképen látható, hogy az átlagos válaszidő drámai csapást szenvedett, ami a szerverrel kapcsolatos problémáknak tudható be:
- Crawl válaszok. Nézze meg a jelentést, hogy általánosságban lássa, van-e probléma a weboldalával vagy sem. Fordítson nagy figyelmet az atipikus szerverállapotkódokra, mint például az alábbi 304-es kódokra. Ezek az URL-címek semmilyen funkcionális célt nem szolgálnak, a Google mégis arra pazarolja erőforrásait, hogy végigkússzon a tartalmukon.

- Crawl célja. Általában ezek az adatok nagymértékben függnek a weboldalon található új tartalmak mennyiségétől. A Google és a felhasználó által gyűjtött információk közötti különbségek igencsak lenyűgözőek lehetnek:
Egy újra feltérképezett URL tartalma a Google szemében:
Eközben itt van, amit a felhasználó lát a böngészőben:
Mindenképpen elgondolkodtató és elemzésre ad okot : )
- Googlebot típusa. Itt vannak a weboldaladat látogató botok ezüsttálcán, a tartalmaid elemzésére irányuló motivációikkal együtt. Az alábbi képernyőképen látható, hogy a kérések 22%-a az oldal erőforrásainak betöltésére vonatkozik.
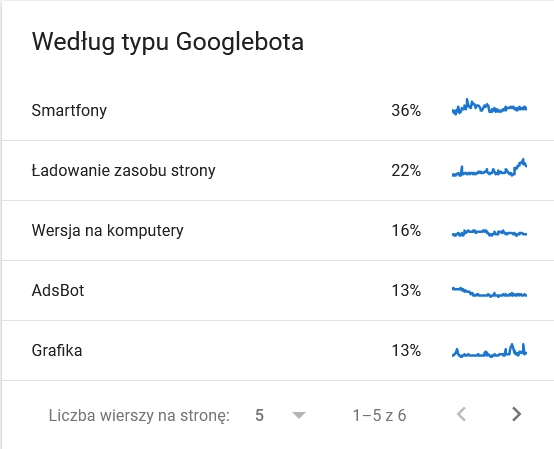
A teljes összeg az időkeret utolsó napjaiban felduzzadt:
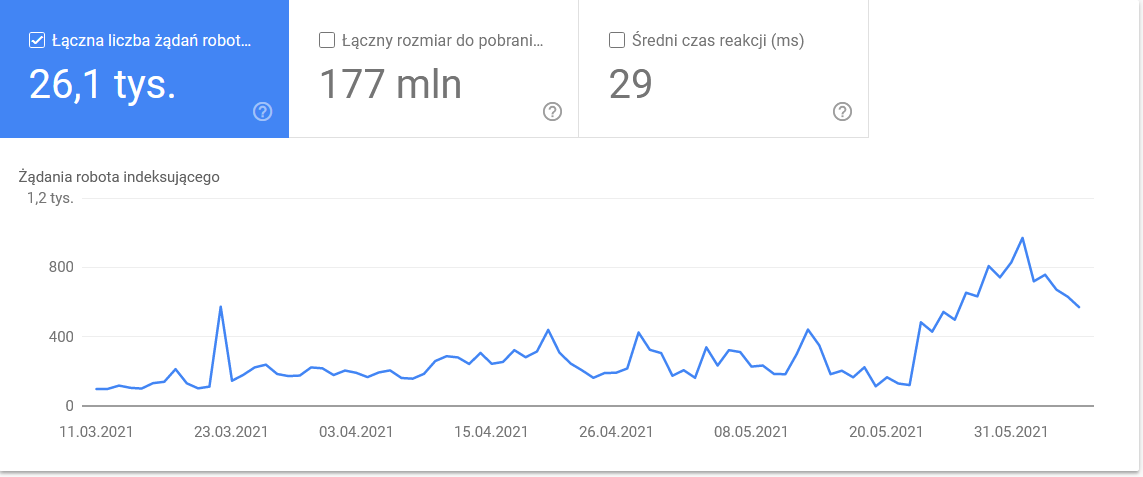
A részletekre pillantva kiderül, hogy melyek azok az URL-ek, amelyek nagyobb figyelmet igényelnek:
Külső lánctalpasok (példákkal a Screaming Frog SEO Spiderből)
A lánctalpasok az egyik legfontosabb eszköz a webhely lánctalpas költségvetésének elemzéséhez. Elsődleges céljuk, hogy utánozzák a lánctalpas robotok mozgását a webhelyen. A szimuláció egy pillantással megmutatja, hogy minden rendben megy-e.
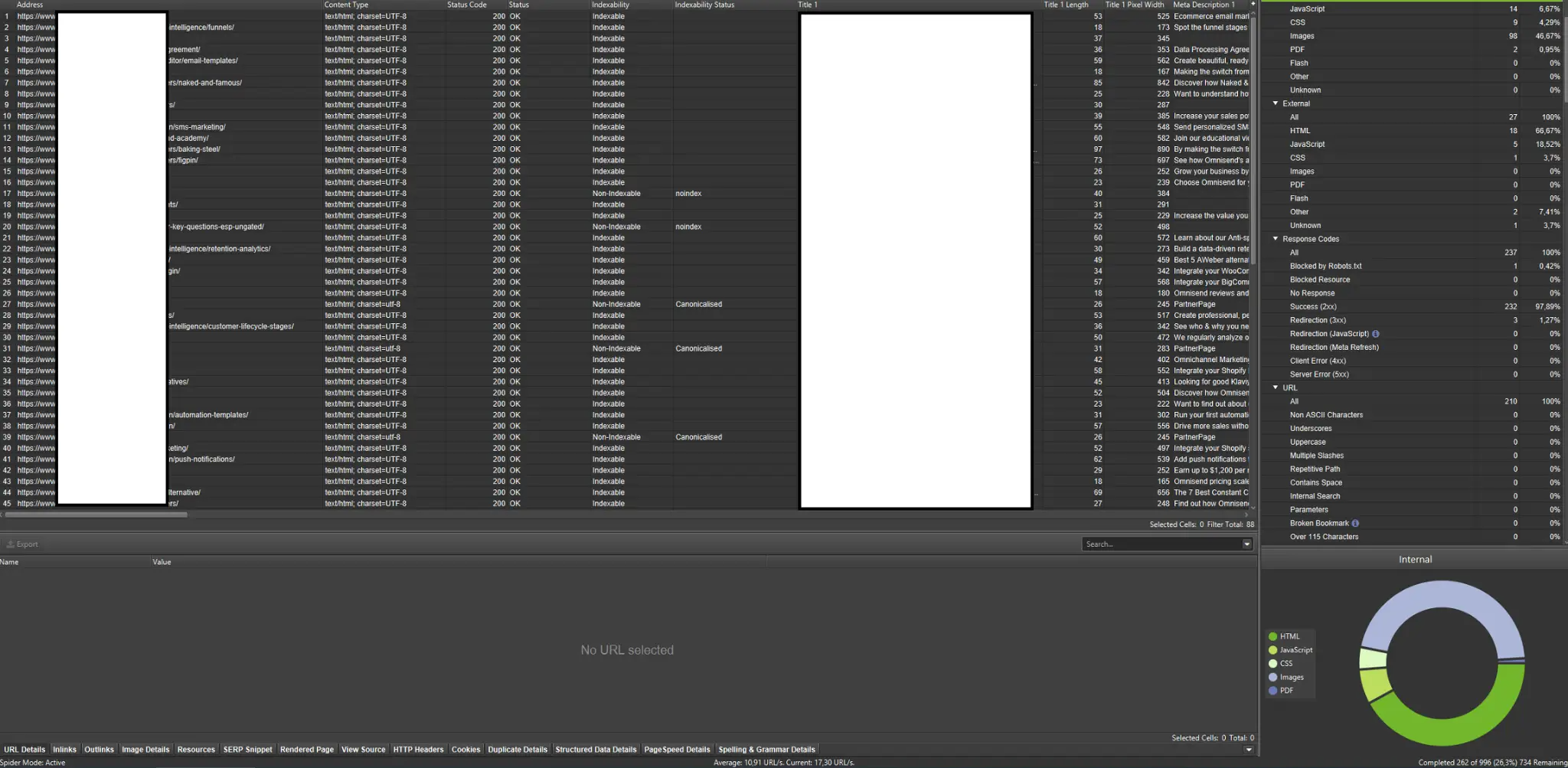
Ha Ön vizuálisan tanul, akkor tudnia kell, hogy a piacon elérhető legtöbb megoldás kínál adatvizualizációt.
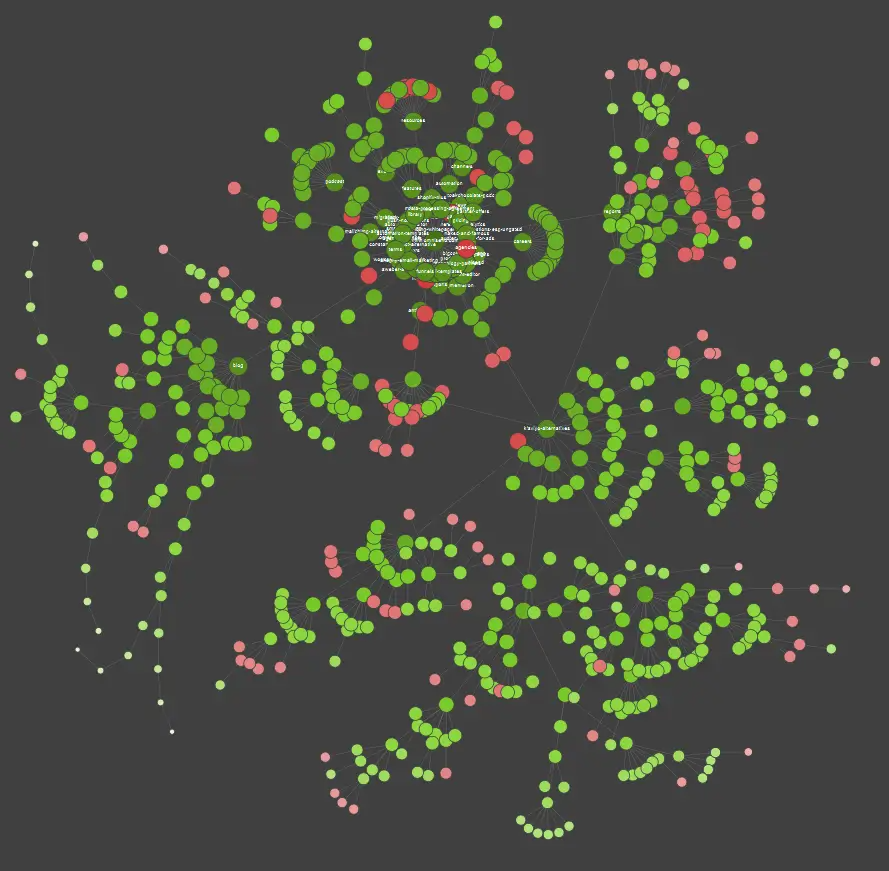
A fenti példában a piros pontok a nem indexelt oldalakat jelölik. Szánjon egy kis időt arra, hogy átgondolja ezek hasznosságát és az oldal működésére gyakorolt hatását. Ha a szervernaplókból kiderül, hogy ezek az oldalak sok időt pazarolnak a Google-ra, miközben nem adnak hozzá értéket – itt az ideje komolyan átgondolni, hogy miért érdemes ezeket az oldalakat a webhelyen tartani.
Fontos: Ha a Googlebot viselkedését a lehető legpontosabban szeretnénk rekonstruálni, a megfelelő beállítások elengedhetetlenek. Itt láthatod a számítógépemről származó mintabeállításokat:
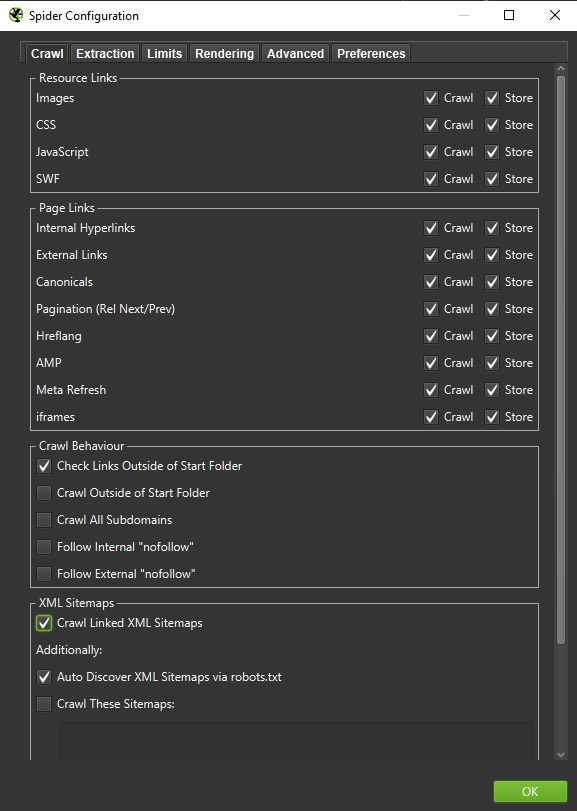
Ha mélyreható elemzést végzünk, jó felhívás két módot tesztelni – csak szöveges, de JavaScriptet is -, hogy összehasonlíthassuk a különbségeket (ha vannak ilyenek).
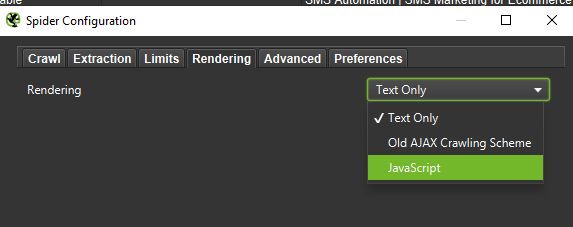
Végezetül, sosem árt, ha a fent bemutatott beállítást két különböző felhasználói eszközön teszteljük:
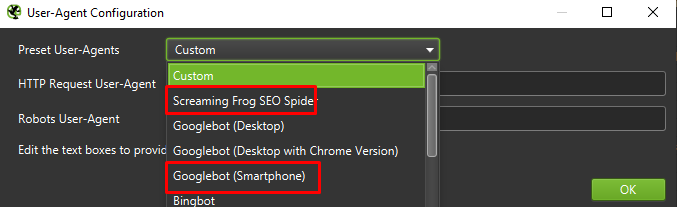
A legtöbb esetben csak a mobilügynök által feltérképezett / megjelenített eredményekre kell összpontosítania.
Fontos: Azt is javaslom, hogy használja ki a Screaming Frog által biztosított lehetőséget, és táplálja a lánctalpasát a GA és a Google Search Console adataival. Az integráció gyors módja annak, hogy azonosítsa a crawl-büdzsé pazarlását, például a potenciálisan felesleges URL-ek jelentős részét, amelyek nem kapnak forgalmat.
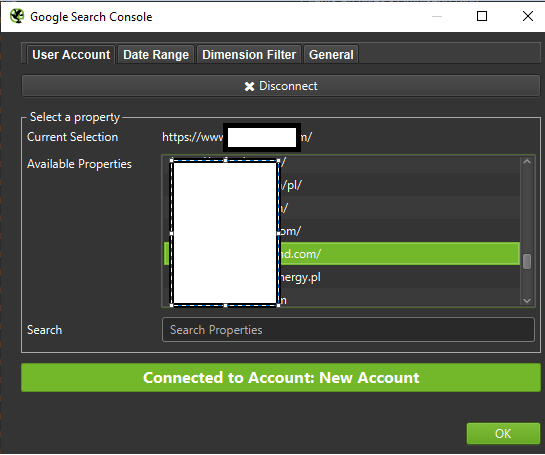
Eszközök naplóelemzéshez (Screaming Frog Logfile és mások)
A szervernapló-elemző program kiválasztása személyes preferencia kérdése. Az általam használt eszköz a Screaming Frog Log File Analyzer. Lehet, hogy nem a leghatékonyabb megoldás (hatalmas naplócsomag betöltése = az alkalmazás akasztása), de nekem tetszik a felülete. A fontos része, hogy utasítsuk a rendszert, hogy csak az ellenőrzött Googlebotokat jelenítse meg.
Tools for visibility tracking
Hasznos segédeszköz, mert segítségével azonosíthatod a legjobban látogatott oldalaidat. Ha egy oldal sok kulcsszóra magasan szerepel a Google-ban (= sok látogatót kap), akkor potenciálisan nagyobb lánctalálási igénye lehet (ellenőrizd a naplókban – valóban több találatot generál a Google erre az adott oldalra?).
A mi céljainkhoz a Senutóban általános jelentésekre – Útvonalak és URL-ek – lesz szükségünk a jövőbeni folyamatos felülvizsgálathoz. Mindkét jelentés elérhető a Láthatóságelemzésben, a Szakaszok fülön. Nézze meg!
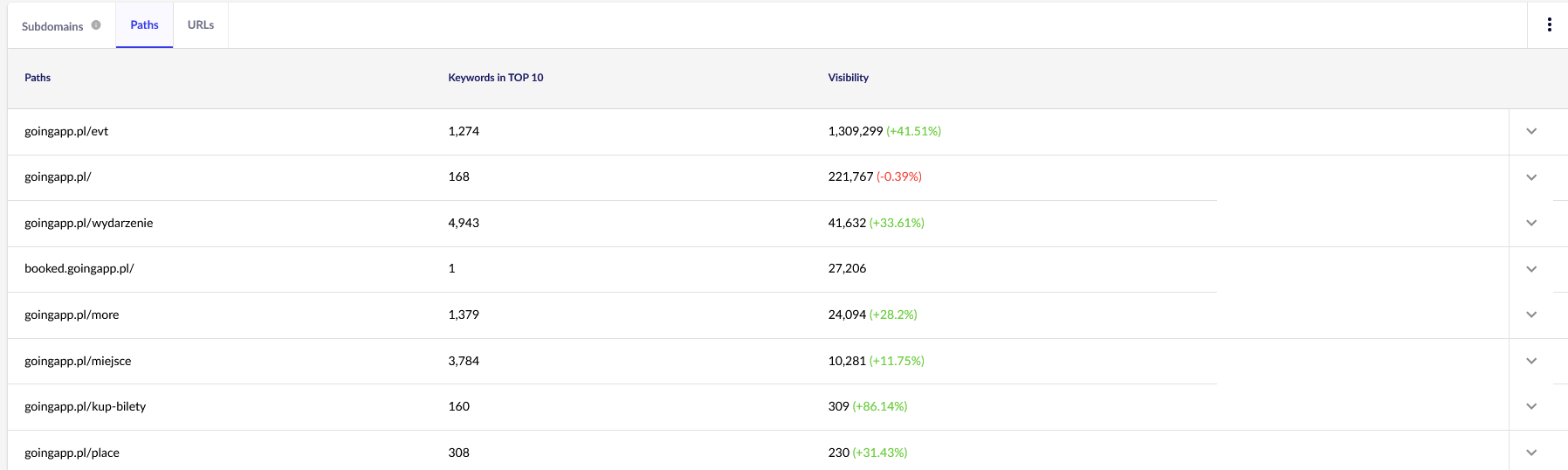
Fő érdekességünk a második jelentés. Rendezzük át, hogy megnézzük a kulcsszavak láthatóságát (azoknak a kulcsszavaknak a listája és összesített száma, amelyekre a weboldalunk a TOP 10-ben szerepel). Az eredmények arra fognak szolgálni, hogy azonosítsuk a lánctalpas költségvetésünk ösztönzésének (és hatékony elosztásának) fő tengelyét.
Tools for backlink analysis (Ahrefs, Majestic)
Ha valamelyik oldaladnak nagy mennyiségű bejövő linkje van, használd a lánctalpas költségvetés optimalizálási stratégiád egyik pilléreként. A népszerű oldalak felvehetik a csomópontok szerepét, amelyek továbbítják a juice-t. Ráadásul egy népszerű oldal, amely tisztességes mennyiségű értékes linkkel rendelkezik, nagyobb eséllyel vonzza a gyakori feltérképezéseket.
Az Ahrefsben szükségünk van az Oldalak jelentésre, pontosabban annak „Legjobbak a linkek alapján” című részére:
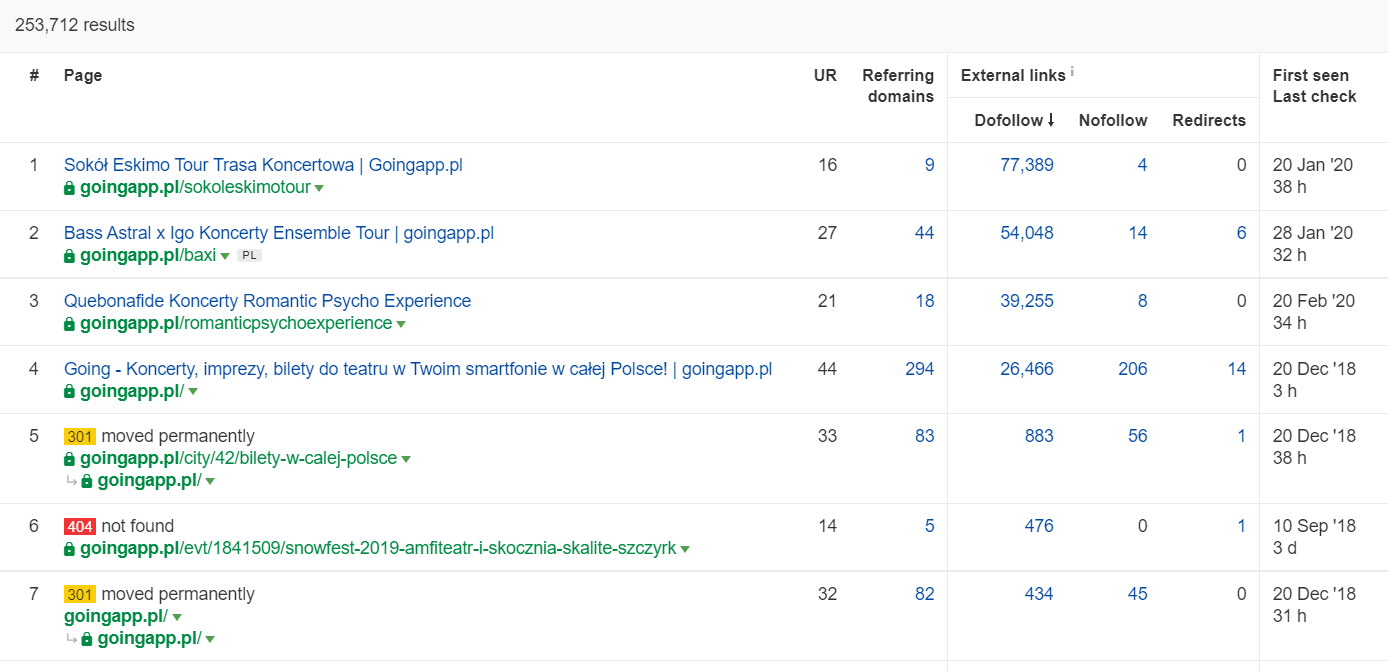
A fenti példa azt mutatja, hogy néhány koncertekkel kapcsolatos LP továbbra is szolid statisztikákat generált a backlinkek tekintetében. Még a világjárvány miatt lemondott koncertek ellenére is kifizetődő a történelmileg erős oldalakat használni, hogy felkeltsük a lánctalpas botok kíváncsiságát, és a webhely mélyebb zugaiba is eljuttassuk a juice-t.
Melyek az árulkodó jelei a lánctalálási költségvetés problémájának?
A felismerés, hogy problémás (túl alacsony) crawl-büdzsével van dolga, nem jön könnyen. Miért? Elsősorban azért, mert a SEO egy rendkívül összetett vállalkozás. Az alacsony helyezések vagy indexelési problémák ugyanúgy lehetnek a közepes linkprofil vagy a megfelelő tartalom hiánya a weboldalon.
Általában a lánctalpas költségvetési diagnosztika magában foglalja az ellenőrzést:
- Mennyi idő telik el a közzétételtől az új oldalak (blogbejegyzések / termékek) indexeléséig, feltételezve, hogy nem kéri az indexelést a Google Search Console-on keresztül?
- Mennyi ideig tartja a Google az érvénytelen URL-eket az indexében? Fontos: az átirányított címek kivételt képeznek – a Google szándékosan tárolja őket.
- Vannak olyan oldalai, amelyek bekerülnek az indexbe, csak hogy később kiesnek?
- Hány időt tölt a Google olyan oldalakkal, amelyek nem generálnak értéket (forgalmat)? Menjen a naplóelemzéshez, hogy megtudja.
Hogyan elemezzük és optimalizáljuk a crawlköltségvetést?
A döntést, hogy belevesse magát a crawl költségvetés optimalizálásába, elsősorban a webhely mérete határozza meg. A Google azt javasolja, hogy általában az 1000 oldalnál kisebb weboldalaknak nem kell gyötrődniük a rendelkezésre álló crawl-korlátok maximális kihasználása miatt. Szerintem akkor érdemes elkezdeni a harcot a hatékonyabb és eredményesebb lánctalpas feltérképezésért, ha a webhelye több mint 300 oldalt tartalmaz és a tartalma dinamikusan változik (például folyamatosan új oldalakat/blogbejegyzéseket ad hozzá).
Miért? Ez SEO-higiénia kérdése. Vezesse be a jó optimalizálási szokásokat és az ésszerű lánctalálási költségvetés-gazdálkodást a kezdeti időkben, és a jövőben kevesebbet kell majd javítania és átterveznie.
Crawl költségvetés optimalizálása. Egy szabványos eljárás
Általánosságban elmondható, hogy a lánctalpas költségvetés elemzésével és optimalizálásával kapcsolatos munka három szakaszból áll:
- Adatgyűjtés, azaz mindannak a folyamatnak az összeállítása, amit a weboldalról tudunk – mind a webmesterektől, mind a külső eszközökből.
- Láthatóságelemzés és az alacsonyan lógó gyümölcsök azonosítása. Mi az, ami óraműpontossággal működik? Mi lehetne jobb? Mely területeken van a legnagyobb növekedési potenciál?
- Javaslatok a kúszóbüdzsére vonatkozóan.
Adatgyűjtés a crawl költségvetés auditálásához
1. Egy teljes weboldal feltérképezése a kereskedelmi forgalomban kapható eszközök egyikével. A cél legalább két crawl elvégzése: az első a Googlebotot szimulálja, míg a másik alapértelmezett felhasználói ügynökként (a böngésző felhasználói ügynöke is megteszi) hozza be a webhelyet. Ebben a szakaszban csak a tartalom 100%-ának letöltése érdekli. Ha azt vesszük észre, hogy a lánctalpas hurokba került (amikor egy napnyi lánctalálás után még mindig csak a weboldal 10%-a van a merevlemezen) – jelezzük, hogy baj van, és leállíthatjuk a lánctalpasítást. Az elemzésre szánt URL-ek ésszerű száma nagy weboldalak esetében 250-300 ezer oldal körül van.
a) Amit keresünk, azok elsősorban a belső 301-es átirányítások, 404-es hibák, de azok a helyzetek is, amikor a szövegeid a vékony tartalom kategóriájába sorolhatók. A Screaming Frog rendelkezik a duplikátum közeli tartalmak felderítésének lehetőségével:
2. Szerver naplók. Az ideális időkeretnek az elmúlt egy hónapot kell átfognia, azonban nagyméretű weboldalak esetében a két utolsó hét is elegendőnek bizonyulhat. A legjobb esetben hozzáférhetünk a korábbi szervernaplókhoz, hogy összehasonlíthassuk a Googlebot mozgását abban az időben, amikor minden flottul ment.
3. Adatexport a Google Search Console-ból. A fenti 1. és 2. pontokkal kombinálva az Index Coverage és a Crawl Stats adatai elég átfogó képet adnak a webhelyen történt eseményekről.
4. Szerves forgalmi adatok. A Google Search Console, a Google Analytics, valamint a Senuto és az Ahrefs által meghatározott top oldalak. Szeretnénk azonosítani az összes olyan oldalt, amely kiemelkedik a tömegből a magas láthatósági statisztikáival, forgalmi volumenével vagy a backlinkek számával. Ezeknek az oldalaknak kell a lánctalpas költségvetésen végzett munkájának gerincét képezniük . Ezek segítségével javítjuk a legfontosabb oldalak feltérképezését.
5. Kézi index felülvizsgálat. Bizonyos esetekben a SEO-szakértő legjobb barátja egy egyszerű megoldás. Ebben az esetben: az egyenesen az indexből vett adatok felülvizsgálata! Jó felhívás, hogy a inurl: + site: operátorok kombinációjával ellenőrizze weboldalát.
Végül össze kell vonnunk az összes összegyűjtött adatot. Általában egy olyan külső lánctalpas programot használunk, amelynek funkciói lehetővé teszik a külső adatok importálását (GSC adatok, szervernaplók és szerves forgalmi adatok).
Láthatósági elemzés és alacsonyan lógó gyümölcsök
A folyamat külön cikket érdemel, de a mai célunk az, hogy madártávlatból lássuk a weboldalra vonatkozó céljainkat és az elért eredményeket. Minden érdekel minket, ami szokatlan: a hirtelen forgalomcsökkenés (ami nem magyarázható szezonális trendekkel) és az organikus láthatóság egyidejű változása. Ellenőrizzük, hogy mely oldalcsoportok a legerősebbek, mert ezek lesznek a mi HUBS-aink, amelyekkel a Googlebotot mélyebbre toljuk a weboldalunkon.
A tökéletes világban egy ilyen ellenőrzésnek le kellene fednie weboldalunk teljes történetét az indulás óta. Mivel azonban az adatmennyiség havonta folyamatosan nő, koncentráljunk az elmúlt 12 hónap láthatóságának és szerves forgalmának elemzésére.
Crawl költségvetés – ajánlásaink
A fent felsorolt tevékenységek az optimalizált weboldal méretétől függően eltérőek lesznek. Ezek azonban a legfontosabb elemek, amelyeket mindig figyelembe veszek a crawl költségvetés elemzésénél. A legfőbb cél a webhely szűk keresztmetszeteinek megszüntetése. Más szóval, a maximális feltérképezhetőség biztosítása a Googlerobotok (vagy más indexelők) számára.
1. Kezdjük az alapoktól – a mindenféle 404/410-es hibák kiküszöbölése, a belső átirányítások elemzése és a belső linkelésből való eltávolítása. Munkánkat egy végső feltérképezéssel zárjuk le. Ezúttal minden linknek 200-as válaszkódot kell visszaküldenie, belső átirányítások és 404-es hibák nélkül.
- Ebben a szakaszban érdemes a backlink jelentésben észlelt összes átirányítási láncot kijavítani.
2. A feltérképezés után győződjünk meg arról, hogy weboldalunk szerkezete mentes a kirívó duplikációktól.
- Az esetleges kannibalizáció ellen is ellenőrizzük – azon problémákon túl, amelyek abból adódnak, hogy ugyanazt a kulcsszót több oldallal célozzuk meg (röviden szólva, már nem tudjuk kontrollálni, hogy melyik oldalt jelenítse meg a Google), a kannibalizáció negatívan befolyásolja a teljes lánctalálási költségvetésünket.
- Az azonosított duplikátumokat egyetlen URL-be tömöríti (általában abba, amelyik magasabb rangsorolást kap).
3. Ellenőrizze, hogy hány URL-hez tartozik a noindex tag. Mint tudjuk, a Google továbbra is képes navigálni ezeken az oldalakon. Csak nem jelennek meg a keresési eredményekben. Igyekezzünk minimalizálni a noindex címkék arányát a weboldalunk szerkezetében.
- Egy blog például címkékkel szervezi a struktúráját; a szerzők állítása szerint a megoldást a felhasználói kényelem diktálja. Minden bejegyzést 3-5 címkével látnak el, amelyeket következetlenül osztanak ki és nem indexelnek. A naplóelemzésből kiderül, hogy ez a harmadik legtöbbet kúszó struktúra a weboldalon.
4. A robots.txt felülvizsgálata. Ne feledje, hogy a robots.txt végrehajtása nem jelenti azt, hogy a Google nem jeleníti meg a címet az indexben.
- Ellenőrizze, hogy a blokkolt címszerkezetek közül melyeket láncolja még be a rendszer. Lehet, hogy ezek leválasztása okoz szűk keresztmetszetet?
- Eltávolítsa az elavult/szükségtelen irányelveket.
5. Elemezze a nem kanonikus URL-ek mennyiségét a webhelyén. A Google már nem tekinti a rel=”canonical” t kemény direktívának. Sok esetben az attribútumot a keresőmotor egyenesen figyelmen kívül hagyja (a paraméterek rendezése az indexben – még mindig egy rémálom).
6. Elemezze a szűrőket és a mögöttes mechanizmusukat. A listák szűrése a legnagyobb fejfájást okozza a lánctalálási költségvetés optimalizálásánál. Az e-kereskedelmi vállalkozások tulajdonosai ragaszkodnak a bármilyen kombinációban alkalmazható szűrők bevezetéséhez (például szín + anyag + méret + elérhetőség… szerinti szűrés a sokadik alkalommal). Ez a megoldás nem optimális, és a minimumra kell korlátozni.
7. Információs architektúra a weboldalon – olyan, amely figyelembe veszi az üzleti célokat, a forgalmi potenciált és a jelenlegi linkprofilt. Dolgozzunk abból a feltételezésből, hogy az üzleti céljaink szempontjából kritikus tartalomra mutató linknek az egész webhelyen (minden oldalon) vagy a főoldalon láthatónak kell lennie. Itt természetesen leegyszerűsítünk, de a honlap és a felső menü / sitewide linkek a legerősebb mutatók a belső linkelésből származó érték kiépítésében. Ugyanakkor igyekszünk elérni az optimális domain-szétterjedést: célunk az a helyzet, amikor bármelyik oldalról elindíthatjuk a lánctalálatot, és mégis ugyanannyi oldalra jutunk el (minden URL-hez MINIMUM egy bejövő linknek kell tartoznia).
- A robusztus információs architektúra kialakítására való törekvés a crawl költségvetés optimalizálásának egyik kulcseleme. Ez lehetővé teszi, hogy a bot erőforrásainak egy részét felszabadítsuk egy helyről, és átirányítsuk őket egy másik helyre. Ez egyben az egyik legnagyobb kihívás is, mivel az üzleti érdekeltek együttműködését igényli – ami gyakran hatalmas csatározásokhoz és a SEO-ajánlásokat aláásó kritikákhoz vezet.
8. Tartalom renderelése. Kritikus azon weboldalak esetében, amelyek célja, hogy a belső linkelésüket a felhasználói viselkedést rögzítő ajánlórendszerekre alapozzák. Mindenekelőtt a legtöbb ilyen eszköz cookie-fájlokra támaszkodik. A Google nem tárol cookie-kat, így nem kap testreszabott eredményeket. A végeredmény: A Google mindig ugyanazt a tartalmat látja, vagy egyáltalán nem lát tartalmat.
- Egy gyakori hiba, hogy a Googlebot nem férhet hozzá a kritikus JS/CSS tartalmakhoz. Ez a lépés az oldal indexelésével kapcsolatos problémákhoz vezethet (és a Google idejét pazarolja a nem elérhető tartalom megjelenítésére).
9. Weboldal teljesítménye – Core Web Vitals. Bár szkeptikus vagyok a CWV hatását illetően a webhelyek rangsorolására (több okból is, többek között a kereskedelmi forgalomban kapható eszközök sokfélesége és az internetkapcsolat változó sebessége miatt), ez az egyik olyan paraméter, amelyet leginkább érdemes megvitatni egy kódolóval.
10. Sitemap.xml – ellenőrizze, hogy működik-e, és tartalmazza-e az összes kulcsfontosságú elemet (semmi mást, csak a 200-as státuszkódot visszaküldő kanonikus URL-eket).
- A sitemap.xml optimalizálásához az első ajánlásom az, hogy az oldalakat típus vagy – ha lehetséges – kategória szerint ossza fel. A felosztás teljes kontrollt biztosít a Google mozgása és a tartalom indexelése felett.