 Sebastian Mioduszewski
Sebastian Mioduszewski V tomto článku se podíváme na získávání dat z nejdůležitějších nástrojů ze stáje Google pro SEO – Google Analytics (i v nejnovější verzi, tj. v4) a Google Search Console. Začneme čísly, která jsou pro nás nezbytná na denní bázi. Dále budeme využívat hotové a bezplatné nástroje, kterými jsou knihovny: searchConsoleR a googleAnalyticsR.
.
Z tohoto článku se dozvíte:
- .
-
Jak nainstalovat potřebné knihovny?
.
-
Jak nenainstalovat knihovny, které již máte?
-
Jak stáhnout data z Google Analytics (včetně jeho nejnovější verze – v4)?
-
Jak získat data z panelu Nástroje Google pro webmastery?
-
Jak začít používat rozhraní API poskytované společností Google?
.
.
.
.
Po přečtení předchozího příspěvku si již pamatujete (pokud ne, zvu vás k přečtení – programovací jazyk R pro každého SEO. Pozice, programujte a sledujte výsledky):
-
Co je to R a jak vám pomůže ve vaší práci
.
-
Jaké jsou knihovny v R (a proč je potřebujete)
- .
Nejdůležitější body
- Článek ukazuje, jak nainstalovat a používat knihovny searchConsoleR a googleAnalyticsR pro práci s Google Analytics a Google Search Console v R.
- Je vysvětleno, jak provést autorizaci a stahování dat z Google Search Console pomocí funkce
search_analytics. - Pro práci s Google Analytics API je nutné vytvořit účet na Google Cloud Platform, povolit Google Analytics API a získat přístupové klíče.
- R umožňuje sbírat velké množství dat, exportovat výsledky a kombinovat data z různých zdrojů, což je užitečné pro SEO analýzu.
- Senuto nabízí nástroje jako Visibility Analysis, které vám pomohou sledovat viditelnost vašich webových stránek a analyzovat konkurenci.
Získáváme data z Google Search Console
.
Abychom mohli knihovnu v R používat, musíme ji nainstalovat (můžete to obejít, ale doporučuji instalaci) a načíst do paměti (přesně v tomto pořadí). Proces instalace ve většině případů trvá do několika desítek sekund. Přesto v níže uvedeném kódu nejprve zkontrolujeme, zda knihovny, které nás zajímají, ještě nemáte. Pokud ano, přejdeme rovnou k druhému kroku, kterým je načtení vybrané knihovny do operační paměti počítače.
Krok 1. Následující kód zapíše název knihovny, kterou potřebujeme, jako vektor (průvodce datovým typem v R: https://towardsdatascience.com/data-types-in-r-8124c3b2afe6):
balíčky <- c("searchConsoleR"," googleAnalyticsR")
.
kód 1.1
Krok 2. Zkontrolujte, zda jsou v počítači nainstalovány potřebné knihovny (pokud některá z potřebných knihoven není nainstalována, je nainstalována).
install.packages(setdiff(packages, rownames(installed.packages())))
kód 1.2
Krok 3. Autorizace. To je samozřejmé, ale stojí za to připomenout, že tímto způsobem budeme mít přístup pouze k datům webu, která jsou k dispozici v našem účtu Search Console.
Provedeme to pomocí jednoho jednoduchého příkazu:
scr_auth()
.
kód 1.3
Kód pro kroky 1, 2 a 3 je k dispozici zde. .
Další kroky závisí na tom, zda se na daném počítači jedná o první načtení dat pomocí této knihovny.
Poprvé je to tehdy, když se v prohlížeči otevře okno pro přihlášení k účtu Google. Nástroj GSC používá ověřování prostřednictvím protokolu oAuth. V důsledku toho se zobrazí standardní přihlašovací okno Google..
Po úspěšném přihlášení musíte ještě odsouhlasit, aby aplikace Search Console měla přístup k vašemu účtu Google.
Takový požadavek se uskuteční pouze při prvním přihlášení na daném zařízení. Během něj se vytvoří soubor JSON obsahující přihlašovací údaje. Díky tomu probíhají další přihlášení mnohem rychleji (R již stahuje přihlašovací údaje uložené v souboru JSON).
Od tohoto okamžiku máme plný přístup k funkcím souvisejícím s:
- .
- Stránky přidané do panelu (stažení seznamu všech, přidání stránky do panelu, odebrání stránky z panelu)
-
Mapy stránek (načtení seznamu všech, přidání do panelu stránek, odebrání z panelu stránek)
.
-
Chyby nahlášené v panelu (stažení příkladů chyb nahlášených v panelu, stažení příkladů adres URL obsahujících nahlášené chyby)
-
Viditelnost našich stránek v Googlu (tyto údaje můžeme zobrazit v rozměrech):
.
– datum – zde získáme informaci o tom, za jaký den jsme data získali
– země – údaje o zeměpisné poloze uživatele, který viděl vaše stránky ve výsledcích vyhledávání
– typ zařízení – na jakém typu zařízení ve výsledcích Google došlo k zobrazení (k dispozici jsou hodnoty Desktop, Mobile, Tablet)
– stránka – podstránka webové stránky, která se zobrazuje ve výsledcích vyhledávání
– hledaná fráze – fráze, po jejímž vyhledání byla stránka nalezena v Google
– Zajímavé je, že žádný z rozměrů není nutný (pak získáme celkové údaje).
Funkce search_analytics, kterou se chystáme použít, přijímá parametry jako např:
- .
-
adresa URL (nezbytný parametr)
.
-
počáteční datum – datum, od kterého chcete získat data (pokud zadáte datum, pro které nejsou v panelu žádná data, budou vráceny jednoduše prázdné řádky)
-
konečné datum – datum, ke kterému chcete stáhnout data
-
typ výsledků vyhledávání, dostupné hodnoty:
.
– „web“ – standardní výsledky vyhledávání
– „image“ – grafické výsledky vyhledávání
– „video“ – výsledky vyhledávání Google ve videu
-
procházka_data – parametr určující, jakým způsobem chceme data získat. Nabývá jedné z hodnot:
– byBatch – tato možnost funguje mnohem rychleji, ale vrací pouze výsledky, na které analyzovaná stránka získala kliknutí (tj. není to dobrý nápad, pokud chcete zkontrolovat, kolik kliknutí stránka získala na Googlu – všechna kliknutí bez kliknutí budou odstraněna)
– byDate – jak již víte, tato metoda je přesnější, ale vyžaduje více času (získání informací o 10 milionech zobrazení na Googlu mi trvalo asi hodinu). Omezení kladené na rozhraní API spočívá v tom, že může načíst maximálně 25 000 řádků najednou. Naštěstí pro ty, kteří chtějí více dat, je k dispozici možnost zařadit 25 000 řádků najednou do fronty a takto získaná data spojit.
Jak se vypořádat s omezeními GSC?
.
Popisovaná knihovna získává data pomocí API GSC, takže můžeme obejít standardní omezení panelu GSC, které nám umožňuje získat až 1 000 řádků v sestavě. Možnost dávkování nám umožňuje stáhnout všechna data. Jak jsem popsal, taková data se stahují v dávkách až do 25 000 řádků.
Při stahování dat z GSC musíme počítat s možností ztráty části dat. Je to proto, že jak vysvětluje společnost Google, systém se snaží vrátit výsledky v přijatelném čase. Z toho vyplývá, že při špatně sestavených dotazech (zapojujících příliš mnoho zdrojů Google najednou) může dojít ke ztrátě některých dat.
S výše uvedenými znalostmi můžeme provést první úplný dotaz na data GSC..
Nápověda: Jednou ze silných stránek aplikace Rstudio je automatická nápověda kódu. Jak můžete vidět níže, je to velmi užitečné při práci s knihovnou searchconsoler.
Jak stáhnout opravdu velké množství dat (více než milion řádků) z Google Search Console?
.
Stažení takového množství dat vyžaduje:
-
Použití rozhraní API (rozhraní GSC má omezení na 1 000 záznamů v sestavě – vlastně prvních 1 000 záznamů, což znamená, že například uvidíte pouze nejoblíbenější fráze)
- .
-
Použití možnosti dávkování v gscR (popsáno již výše)
-
Dávkování dat – stažení asi 1,5 milionu záznamů trvá asi 30 minut. Při mnohem větším počtu můžeme potřebovat i několik dní na stažení všech dat! Řešením tohoto problému je použití parametru dimensionFilterExp.
.
Obsah tohoto parametru se skládá z filtru a operátoru.

Filtr může nabývat jedné z hodnot:
- Země
- Zařízení
- Stránka
- Dotaz
K dispozici jsou tyto operátory:
- ~~ (což znamená obsahuje)
- == (znamená rovná se)
- !~(význam neobsahuje)
- != (znamená nerovná se)
.
.
.
.
Filtrování myšlenek:
-
Všechen provoz z vybraných zařízení
.
-
Všechen provoz na vybraných podstránkách (např. jen na domovské stránce)
-
Všechen provoz z vybrané země (např. pouze provoz z Polska)
- .
Důležité je, že filtry lze kombinovat. Mezi příklady složených filtrů patří např:
-
Všechen provoz z vybraného typu zařízení na vybranou podstránku
.
-
Všechen provoz od uživatelů z vybrané země pro fráze obsahující konkrétní prvek
Celý skript, připravený ke zkopírování a spuštění, je k dispozici tzde..
Vyzkoušejte Senuto Suite na 14 dní zdarma
Pojďme na to!Jak rychle stáhnout data z Google Analytics (i verze v4) v R?
.
Krok 1. Stejně jako v předchozím skriptu zapíšeme název knihovny, kterou potřebujeme.
balíčky <- c(" googleAnalyticsR")
.
Krok 2. Stejně jako jsem již popsal u Google Search Console, zkontrolujeme, zda je potřebná knihovna v počítači nainstalována.
install.packages(setdiff(packages, rownames(installed.packages())))
.
Začínáme vážně pracovat s rozhraním API společnosti Google (zaregistrujte si účet Google Cloud Platform)
.
Chceme-li vážně pracovat s rozhraními API poskytovanými společností Google, měli bychom si vytvořit účet.
Krok 3. V tomto kroku si vytvoříme účet v platformě Google Cloud Platform. To je nezbytné, abychom mohli plně využívat možnosti rozhraní API pro Google Analytics. Naším cílem bude získat:
- klientské tajemství (řetězec dostupný v souboru, který stáhneme z GCP)
- ID klienta (ID uživatele GCP)
.
.
K tomu potřebujeme:
-
Vytvořit si bezplatný účet na webových stránkách GCP (nebudu to vysvětlovat)
.
-
Povolte na svém účtu GCP podporu rozhraní Google analytics API.
- .
- .
Za tímto účelem vyberte nabídku API a služby.
 .
.
Přejděte na možnost Povolit rozhraní API a služby.

Z dostupných vybereme následující rozhraní API.

Dále v nabídce vyberte možnost Podrobnosti o přihlášení.
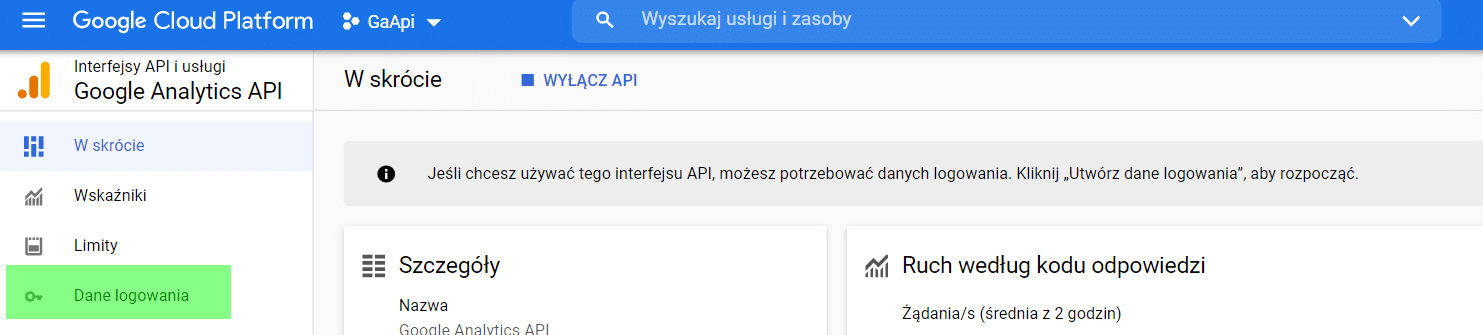 .
.
Při dotazu na typ aplikace vybereme možnost „Počítačová aplikace“.
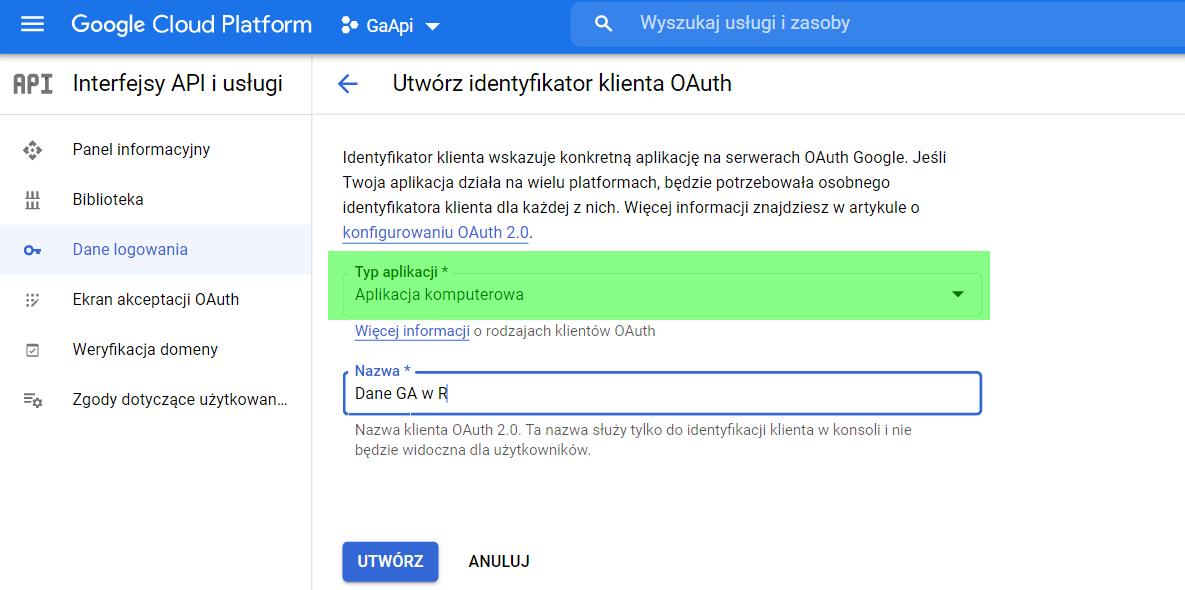
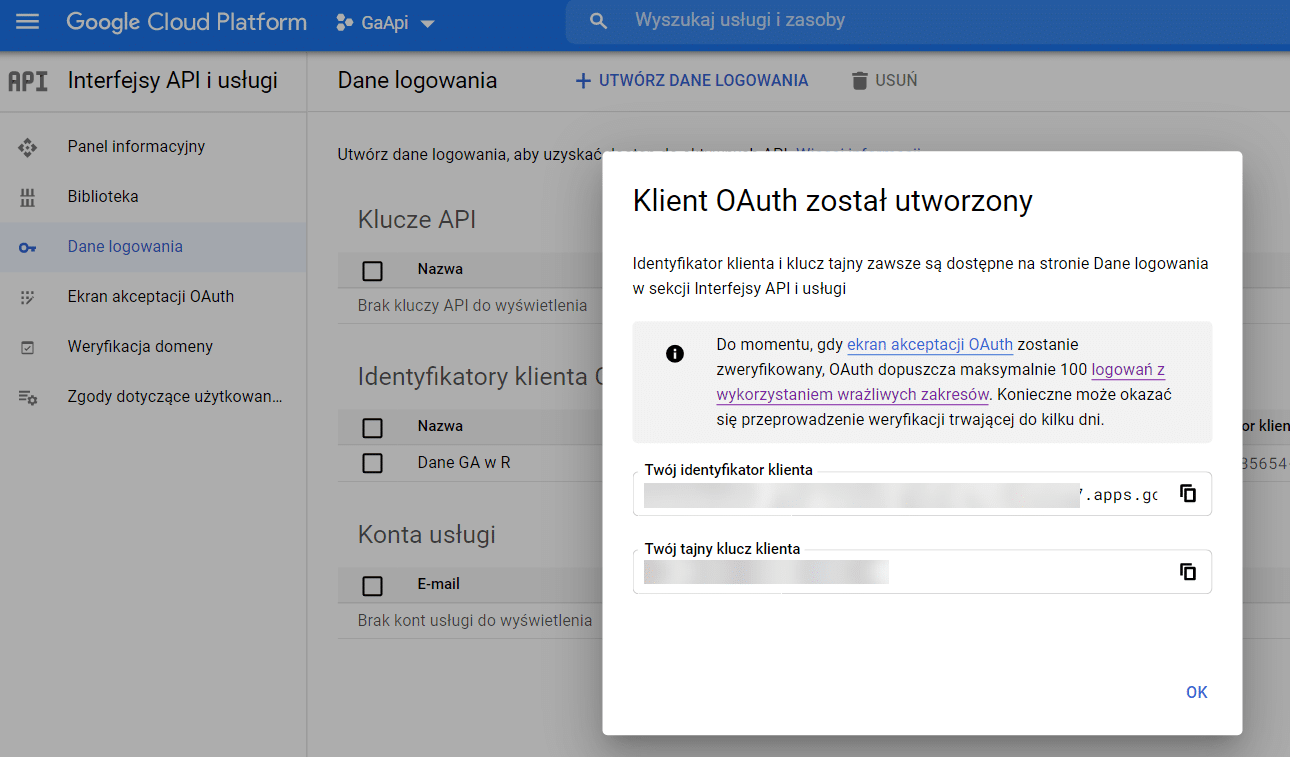
Po vyplnění názvu a typu aplikace získáme ID a tajný klíč pro náš účet.
Dalším krokem je vytvoření účtu služby. To nám umožní vygenerovat adresu potřebnou pro ověření v GA. Tento servisní účet vytvoříme výběrem možnosti Administration > Service Accounts (Správa > Servisní účty) v nabídce GCP (jak je uvedeno níže).
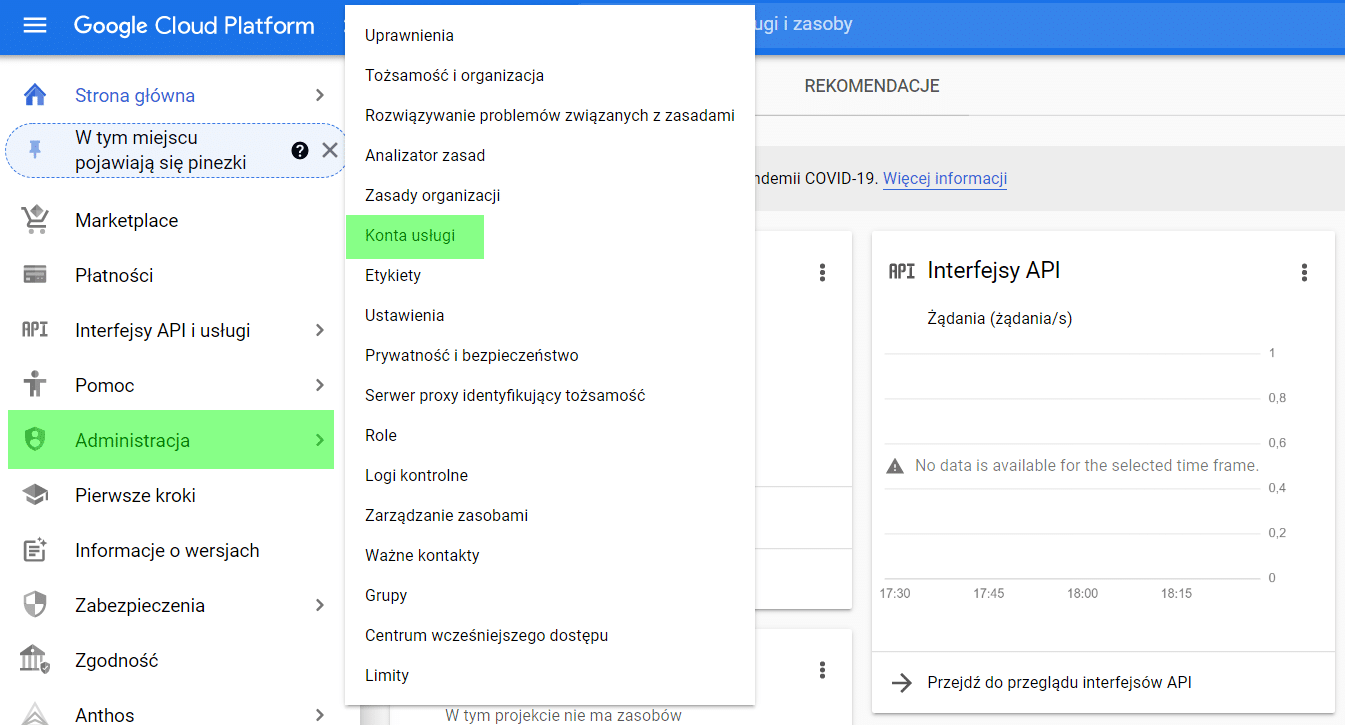
Posledním přípravným krokem je přidání adresy uživatele účtu GCP (zvýrazněno níže) na ovládací panel služby Google Analytics.
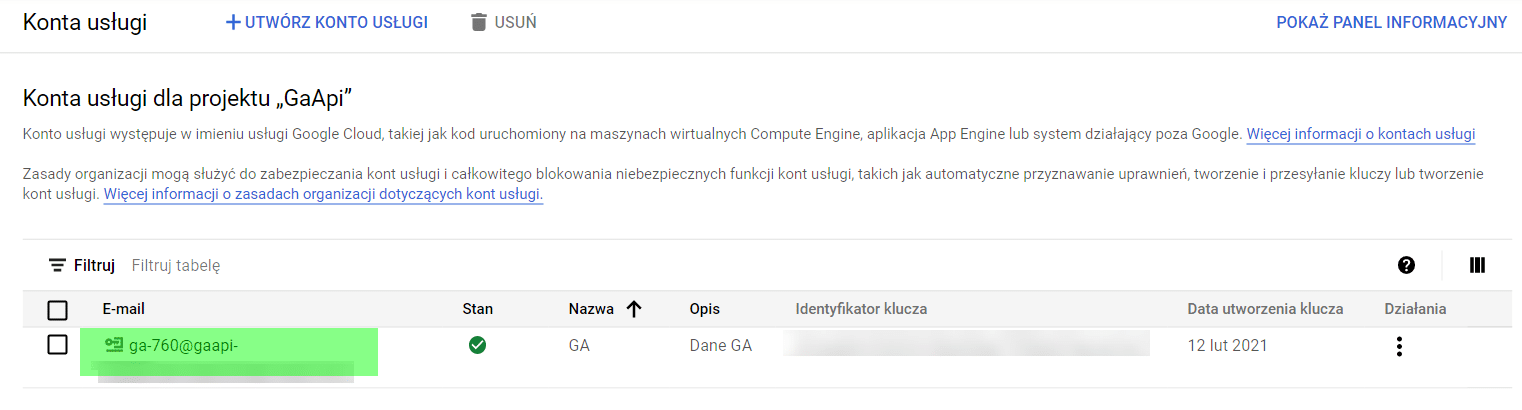
Pro ověření budeme potřebovat ID zákazníka a klíč zákazníka. Uložíme je jako proměnné v R.
Co jsou dimenze a metriky dat
.
Těm, kteří mají zkušenosti s prací s databázemi, bude rozdělení mezi fakty a dimenzemi povědomé. Protože jeden obrázek vydá za více než tisíc slov, pokusím se o tom pojednat názorně.
Fakta jsou události, které jsou základem pro analýzu (např. prodeje nebo uživatelé služeb).
Dimenze popisují fakta. Fakta lze rozdělit na dimenze (např. počet uživatelských relací).
Následující rozdělení údajů pro GA (převzaté z této stránky) představuje analýzu, kde:
Fakt – uživatelé webu.
Dimenze – typ uživatele (zde nový nebo vracející se).
Metrika – počet uživatelů, datum ve formátu (RRRR-MM-DD, tj. například 2021-02-15).
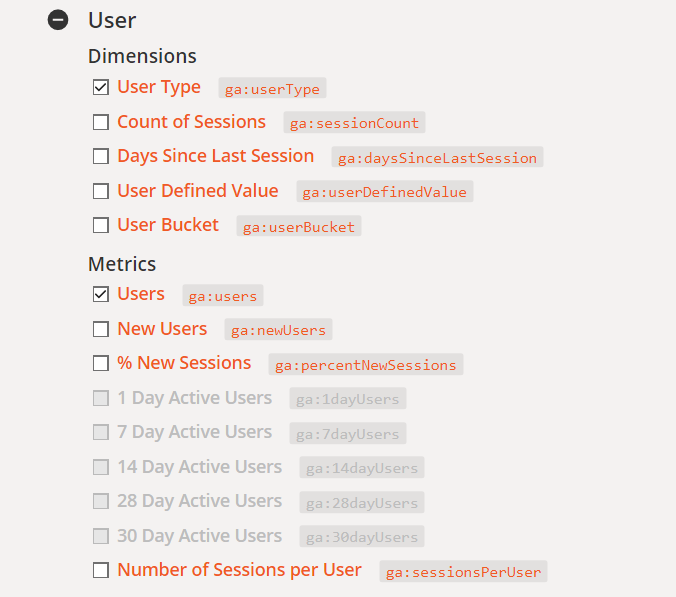
Tím získáme následující údaje:
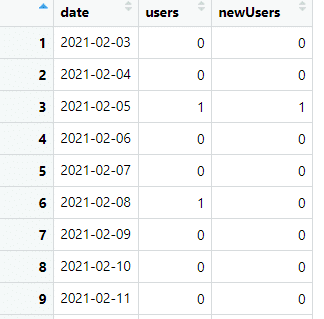
A kód R:

Celý kód je k dispozici zde.
Omezení (vzorkování a množství dat) v přehledech Google Analytics oproti API
.
Služba Google Analytics má omezení týkající se vzorkování dat (více informací o vzorkování zde).
Při stahování dat to můžeme zkontrolovat pomocí parametru anti_sample. Jeho použití způsobí, že systém vrátí pokud možno nevybraná data (tedy dokud se nedostaneme do limitů). Následující příklad ukazuje zpětnou vazbu v konzoli aplikace R Studio, která indikuje, že zpráva byla pořízena bez vzorkování dat.
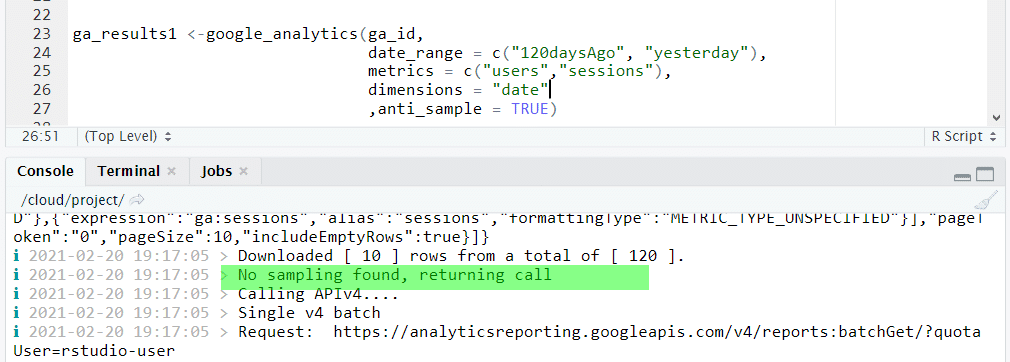
Data ke stažení
.
Stáhněte si seznam účtů GA, ke kterým máme přístup
.
Tímto krokem vždy začínám práci s GA. Umožňuje mi ověřit, že můj skript získal připojení k rozhraní API a že mám přístup k účtům, které mě zajímají. To se provádí voláním funkce ga_account_list().
![]()
![]()
Což nám dává objekt s názvem my_acc obsahující informace o zobrazeních dat a účtech GA, ke kterým máme přístup. To nám umožní vytvořit objekt (v tomto případě matici s názvem data_GA) obsahující všechna ID datových pohledů a názvy účtů, ke kterým máme přístup.
![]()
![]()
Tím získáme následující objekt:
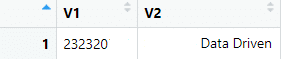
Počet výsledků
.
Ve výchozím nastavení vrací rozhraní API pouze 100 výsledků. Počet výsledků lze nastavit pomocí parametru limit. Chcete-li získat všechny výsledky, zadejte parametru limit hodnotu -1.

Rozsah dat
.
Ve výchozím nastavení je rozsah dat, který načítáme, nastaven pomocí parametru date_range. Je možné vybrat více než jeden rozsah dat.

Velmi užitečné je, že místo konkrétních dat (vždy ve formátu YYYY-MM-DD) můžeme použít univerzální parametry, například včera nebo XXdníAgo. Vrátí datum XX dní před dneškem (místo XX vložíme konkrétní počet dní, takže například 7daysAgo nám dá datum před 7 dny).
Filtrování dat
.
Chceme-li zkrátit dobu čekání na data, vyplatí se použít filtrování. Umožňuje načíst pouze vybraná data. Filtrování je možné na dvou úrovních: metriky a/nebo dimenze (k tomu slouží parametry met_filters – filtrování podle metrik a dim_filters – filtrování podle dimenzí).
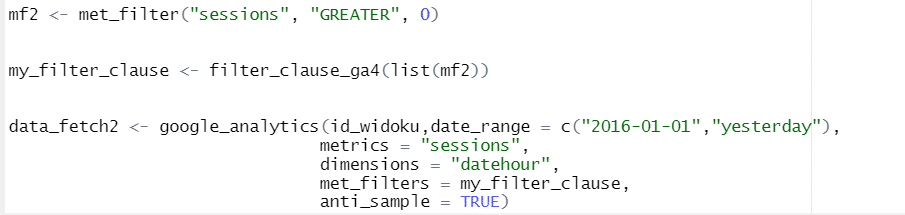
Met_filter() přijímá následující parametry:
- .
- metrika – metrika, podle které filtrujeme (např. relace)
- operátor – nabývá jedné z následujících hodnot :
- „EQUAL“ – rovná se
- „MENŠÍ_NEŽ“ – menší než
- „VÍCE_NEŽ“ – více než
- „IS_MISSING“ – chybějící hodnota
- comparisonValue – hodnota metriky, kterou chceme filtrovat nebo odfiltrovat
- not – pokud nabývá hodnoty TRUE, pak data odpovídající filtru do výsledků nezahrneme.
- Dim_filter() – použijeme tuto funkci s parametry:
- dimenze – dimenze, podle které filtrujeme (např. typ zařízení = Desktop nebo země uživatele = Polsko;
- Operátor – funguje stejně jako u met_filter a může nabývat jedné z hodnot:
- REGEXP – kontroluje, zda pole zadané ve výrazech odpovídá zadanému regulárnímu výrazu
- Začíná_se – začíná zadaným filtrem
- KONČÍ_ZADÁNÍM – končí zadaným filtrem
- PARTIÁLNÍ – zahrnuje zadaný fragment
- EXAKTNÍ – má hodnotu přesně podle zadání
- NUMERIC_EQUAL – má hodnotu rovnou danému číslu
- NUMERIC_GREATER_THAN – je číslo větší než zadané
- NUMERIC_LESS_THAN – je číslo menší než dané číslo
- IN_LIST – je v seznamu hodnot, který jsme zadali
- Výraz – výraz (číslo nebo text, který hledáme v názvu rozměru)
- Casesensitive – pokud má hodnotu TRUE, rozlišuje velká a malá písmena (velká/malá písmena)
- Není – funguje stejně jako u met_filter.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Úplný seznam filtrů a rozměrů dostupných v GA můžeme zkontrolovat pomocí funkce ga_meta.
Příklad použití: V případě, že se jedná o aplikaci, která se používá v systému Ga>, je možné použít tzv:
![]()
![]()
Poskytne nám objekt obsahující podrobný popis všech (včetně již stažených – označených jako DEPRECATED v poli status) rozměrů a metrik.
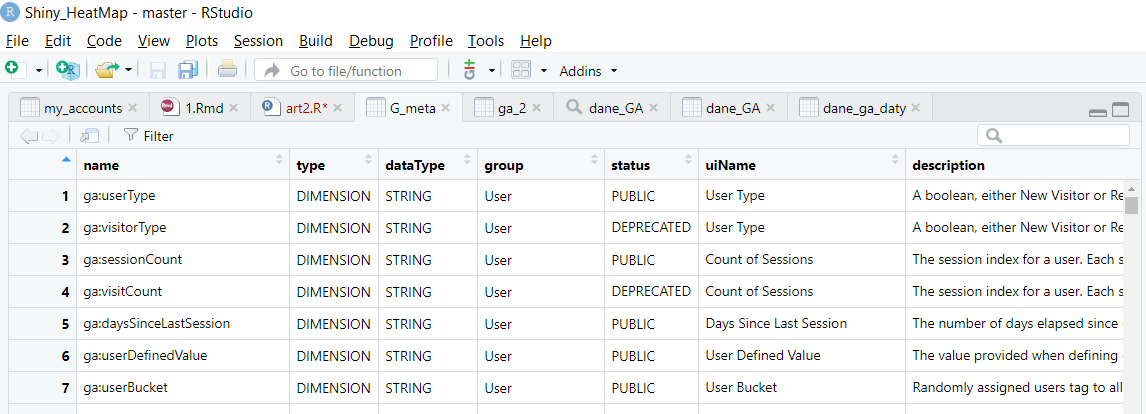
Po vytvoření objektu filtru metrik a/nebo dimenzí je třeba vytvořit objekt filtru pomocí funkce filter_clause_ga4. Tento objekt používáme ve funkci google_analytics. To nám umožňuje vytvářet pokročilé filtry pro kombinace více než jedné metriky a/nebo dimenze.
Níže filtrujeme data tak, aby zahrnovala pouze návštěvy (metrika) ze země Polsko (dimenze s názvem contry nabývá hodnoty Poland).
Vytvoříme filtr pro data, kde dimenze země obsahuje právě řetězec Polsko – to znamená, že odmítneme všechny návštěvy z jiných zemí než z Polska.
![]()
![]()
Na základě tohoto filtru vytvoříme objekt filtru:
![]()
![]()
Ve funkci, která načítá data, používáme objekt filtru:

Kód použitý v této části je k dispozici zde.
Souhrn
.
Mnoho z nás SEO specialistů se zaměřuje na vyhledávač Google. Nástroje jako Přímá odpověď samozřejmě poskytují velký přehled o tom, co se ve vyhledávači děje. I tak by ale základem každé analýzy měly být údaje od samotného Googlu. Své dobrodružství při aplikaci programování do SEO jsem začal právě stahováním dat ze zde popsaného nástroje. Pro mě se to promítlo do lepšího pochopení toho, co se ve vyhledávači děje, a nakonec i do vyšších pozic. Stejně jako všechny nástroje, i ty od Googlu vyžadují pochopení jejich možností a omezení, aby se daly dobře používat.
Nejdůležitější věci, které je třeba mít na paměti:.
- .
- Data z analytických nástrojů Google nejsou stoprocentně sladěna s daty z konzoly Google Search Console
- Data Google nesdílejí informace o konkurenci
- Analytická data Google jsou shromažďována „na vaší straně“. – takže můžete nahrát spoustu dalších informací (např. u příspěvků na blogu jméno autora nebo název výrobce v obchodě)
- Data služby Google Search Console jsou shromažďována na straně společnosti Google – pro shromažďování dat si tedy stačí vytvořit účet.
.
.
.
Pomocí jazyka R jste schopni:.
- sbírat velké množství dat (mnohem více, než se vejde do Excelu – něco přes milion řádků)
- exportovat výsledná data (např. do excelu)
- kombinovat data z více zdrojů
- Pokud je to možné, obejděte omezení bezplatných nástrojů Google
.
.
.
.
Vyzývám vás k testování, komentování a implementaci řešení, která jsem zde popsal, nebo vašich vlastních nápadů.
Uvidíme se v SERPu!
Díky za přečtení!
Zaregistrujte se zdarma a připojte se k více než 14 000 uživatelům aplikace Senuto ????
FAQ
install.packages() pro instalaci chybějících balíčků.
searchConsoleR, provést autorizaci pomocí scr_auth() a pak lze použít funkci search_analytics pro stahování dat.
searchConsoleR lze tato omezení obejít a stáhnout všechna data díky možnosti dávkování. Zde se dozvíte více o strategii SEO.
googleAnalyticsR, zaregistrovat si účet Google Cloud Platform, povolit Google Analytics API a získat přístupové klíče. Zde se dozvíte více o měření úspěšnosti obsahu.