 Piotr Smargol
Piotr Smargol Nenápadný soubor robots.txt umožňuje řídit přístup robotů vyhledávačů na vaše webové stránky. Z tohoto důvodu hraje v SEO klíčovou roli a stojí za to mu věnovat náležitou pozornost, zejména při pokročilejších SEO aktivitách. V tomto článku probereme, co je soubor robots.txt, k čemu slouží a proč je důležitý, a poté přejdeme k ukázkovým pravidlům a návodu, jak si takový soubor vytvořit sami.
Nejdůležitější body
- Soubor robots.txt je klíčový pro řízení přístupu vyhledávacích robotů na webové stránky a hraje důležitou roli v SEO.
- Je důležité správně nastavit pravidla v souboru robots.txt, aby se zabránilo indexaci nežádoucího obsahu a efektivně využil rozpočet na procházení.
- V souboru robots.txt lze použít speciální znaky jako asterisk (*) a dolar ($), které fungují podobně jako regulární výrazy.
- Pro testování správnosti pokynů v souboru robots.txt můžete použít nástroj pro testování robots.txt od Google.
- Pro efektivní správu SEO aktivit doporučujeme využít nástroje jako je Visibility Analysis od Senuto.
Co je to soubor robots.txt a proč se používá?
.
Soubor s přesným názvem robots.txt je jednoduchý textový soubor – uložený ve formátu .txt a umístěný přímo v kořenové složce domény.
Uvnitř souboru umisťujeme pokyny pro roboty, kteří navštěvují naše webové stránky.
V těchto pokynech určíme, které stránky z kořenového adresáře domény mohou roboti navštívit a kterým možnost návštěvy zablokujeme.
Stojí za zmínku, že roboti mohou obejít směrnice umístěné v souboru robots.txt a přesto se dotazovat na stránky nebo sekce tam umístěné.
Vyzkoušejte Senuto Suite na 14 dní zdarma
Pojďme na to!Proč je soubor robots.txt důležitý?
.
Důležitost souboru robots.txt poznáme podle toho, jak robot Google prohledává stránky.
Když robot Google narazí na vaše stránky propojené z jiné domény, která je již v jeho indexu, okamžitě zkontroluje soubor robots.txt, aby ověřil, které zdroje na stránkách může navštívit. Poté tento soubor pravidelně navštěvuje a zjišťuje, zda se v pokynech něco nezměnilo.
Analýzou protokolů webových stránek můžeme zjistit, že soubor robots.txt je i u malých webových stránek navštěvován desítky či desítkykrát měsíčně.
Kromě již zmíněné možnosti zablokovat robotům přístup na určitá místa na webu používáme soubor robots.txt k podlinkovaní adresy URL mapy webu XML. Propojení mapy stránek zde je důležité zejména v případě, že nemáme profil v Google Search Console a že naše mapa stránek má nestandardní adresu URL.
Za zmínku také stojí, jak pečlivě Google plní svůj soubor robots.txt, který najdete na adrese URL https://www.google.com/robots.txt.
Příklad pravidel v souboru robots.txt. Z jakých skupin a směrnic se takový soubor skládá
.
Každý soubor robots.txt je sestaven ze skupin. Mezi skupiny směrnic patří např:
- odkaz na název bota,
Každá aplikace nebo uživatel navštěvující web je představen svým klientským jménem, nebo jinak známým jako jméno bota. Právě toto jméno uvádíme v direktivách uvnitř souboru v direktivě User-agent. - informace o tom, které zdroje jsou vyloučeny nebo povoleny k návštěvě uvedeným botem.
.
Takové skupiny nám umožňují především:
- Vybrat jméno bota, na kterého chceme nasměrovat směrnice.
Uživatelský agent: AdsBot-Google
.
- Přidáme direktivy pro blokování přístupu do konkrétních adresářů nebo na konkrétní adresy URL.
Zakázat: /maps/api/js/
.
- Přidání direktiv pro povolení přístupu ke konkrétním adresářům nebo adresám URL.
/maps/api/js.
Každá další skupina může obsahovat další jméno robota a směrnice pro dalšího robota, např:
Uživatelský agent: Twitterbot Allow: /imgres
.
V souhrnu získáme sadu skupin:
Uživatelský agent: AdsBot-Google Zakázat: /maps/api/js/ Povolit: Povolit: /maps/api/js Zakázat: /maps/api/place/js/ Zakázat: /maps/api/staticmap Zakázat: /maps/api/streetview User-agent: Twitterbot Povolit: /imgres
Všimněte si však, že řádky uvnitř skupiny jsou zpracovávány shora dolů a klientovi uživatele (v tomto případě: jménu robota) odpovídá pouze jedna sada pravidel, přesněji první nejsilněji specifikované pravidlo, které se na něj vztahuje.
Na pořadí skupin v souboru samo o sobě nezáleží. Za zmínku stojí také to, že u robotů se rozlišují malá a velká písmena. Například pravidlo:
Zakázat: /file.asp
platí pro podstránku http://www.example.com/file.asp, ale pro podstránku http://www.example.com/FILE.asp – již ne.
To by však nemělo způsobovat problémy, pokud v naší doméně správně vytvoříme adresy URL.
A konečně, pokud pro jednoho robota existuje více než jedna skupina, směrnice z duplicitních skupin se sloučí do jedné skupiny.
Uživatelský agent
.
Pouze jedna ze skupin umístěných v souboru robots.txt je přiřazena k názvu každého robota a ostatní jsou ignorovány. Proto robot se jménem Senuto, který vidí pravidla v souboru robots.txt domény:
Uživatelský agent: * disallow: .: /search/ User-agent: Senuto allow: /search/
vybere níže uvedené pravidlo (v příkladu) a zpřístupní adresář /search/, protože je na něj přesně zaměřeno.
Disallow
.
Direktiva disallow určuje, ke kterým adresářům, cestám nebo adresám URL nemají vybraní roboti přístup.
disallow: [cesta]
.
disallow: [address-URL]
.
Pokud není vyplněna žádná cesta nebo adresář, je směrnice ignorována.
disallow:
.
Příklad použití směrnice:
disallow: /search
Výše uvedená direktiva zablokuje přístup k adresám URL:
- https://www.domena.pl/search/
- https://www.domena.pl/search/test-site/
- https://www.domena.pl/searches/
.
.
.
Je třeba poznamenat, že zde probíraný příklad se týká pouze použití jednoho pravidla pro jednoho určeného robota.
Povolit
.
Směrnice allow určuje, ke kterým adresářům, cestám nebo adresám URL mají určení roboti povolen přístup.
allow: [cesta]
.
allow: [adresa-URL]
Pokud není vyplněna žádná cesta nebo adresář, je směrnice ignorována.
allow:
.
Příklad použití směrnice:
povolit: /images
Výše uvedená direktiva povolí přístup k adresám URL:
- https://www.domena.pl/images/
- https://www.domena.pl/images/test-site/
- https://www.domena.pl/images-send/
.
.
.
Je třeba poznamenat, že zde probíraný příklad se vztahuje pouze na použití jednoho pravidla pro jednoho uvedeného robota.
Mapa stránek
.
Do souboru robots.txt můžeme také zahrnout odkaz na mapu našich stránek ve formátu XML. Vzhledem k tomu, že stránku robots.txt robot Google pravidelně navštěvuje a je jednou z prvních stránek webu, na které přistupuje, má silný smysl odkaz na mapu webu zařadit.
mapa stránek: [unlabeled-address-URL]
.
V pokynech společnosti Google se uvádí, že adresa URL mapy stránek by měla být absolutní (úplná, správná adresa URL), takže např:
mapa stránek: https://www.domena.pl/sitemap.xml
Další směrnice
.
V souborech robots.txt můžeme najít i další direktivy, a to:
- host – direktiva host se používá k označení preferované domény mezi mnoha jejími kopiemi dostupnými na internetu.
- zpoždění procházení – v závislosti na robotovi může být tato direktiva použita různě. V případě robota vyhledávače Bing bude doba uvedená v poli crawl delay představovat minimální dobu mezi prvním a druhým procházením jedné podstránky webu. Naproti tomu Yandex bude tuto direktivu číst jako dobu, kterou musí robot počkat před dotazem na každou další stránku v doméně.
.
Obě tyto směrnice bude Google ignorovat a při skenování webu je nebude brát v úvahu.
Můžeme v pravidlech používat regulární výrazy?
.
Roboti vyhledávače Google (ale nejen oni) podporují v cestách jednotlivé znaky se speciálními vlastnostmi. Mezi takové znaky patří např:
- .
- znakasterisk * – označuje nula nebo více výskytů libovolného znaku,
- znak dolaru $ – označuje konec adresy URL.
.
.
To se neshoduje zcela s tím, co známe z regulárních výrazů https://pl.wikipedia.org/wiki/Wyrażenie_regularne. Za zmínku stojí také to, že vlastnosti znaků * a $ nejsou zahrnuty ve standardu pro vyloučení robotů https://en.wikipedia.org/wiki/Robots_exclusion_standard.
Příkladem použití těchto znaků nofollow by bylo pravidlo:
disallow: *hledá*
.
Citované pravidlo bude stejné jako pravidlo:
disallow: searches
.
a znaky * budou jednoduše ignorovány.
Tyto znaky najdou využití například tehdy, když chcete zablokovat přístup ke stránkám, kde se mezi dvěma složkami v adrese URL mohou nacházet další složky, a to buď jednotlivě, nebo opakovaně.
Pravidlo pro blokování přístupu ke stránkám, které mají ve adresě URL složku /search/ a hlouběji ve struktuře stránky složku /on-demand/, by vypadalo takto:
disallow: /search/*/on-demand
Pomocí výše uvedeného pravidla zablokujeme přístup k těmto adresám URL:
- https://www.domena.pl/search/wstawka-w-url/on-demand/wlasciwy-url/
- https://www.domena.pl/search/a/on-demand/,
.
Přístup k těmto adresám však blokovat nebudeme:
- https://www.domena.pl/search/on-demand/
- https://www.domena.pl/on-demand/
- https://www.domena.pl/search/adres-url/
.
.
Zajímavým příkladem by bylo zablokování přístupu ke všem souborům s příponou .pdf (předpokládáme, že takto je ukončen každý soubor s touto příponou v naší doméně), které v adrese URL obsahují složku /data-client/. K tomu použijeme směrnici:
disallow: /data-client/*.pdf$
Více informací o správné syntaxi a pravidlech, která je třeba zahrnout do souboru robots.txt, najdete ve specifikaci syntaxe ABNF na adrese URL: https://datatracker.ietf.org/doc/html/rfc5234.
Co by měl obsahovat základní soubor robots.txt
.
Aby byl soubor robots.txt správně čten, měl by:
- být textový soubor v kódování UTF-8,
- mít název: robots.txt (ukázka adresy URL https://www.domena.pl/robots.txt),
- být umístěn přímo v kořenové složce domény,
- být v rámci domény jedinečný – neměl by existovat více než jeden soubor robots.txt, protože pokyny v souborech umístěných na jiné než uvedené adrese URL nebudou přečteny,
- obsahovat minimálně jednu skupinu směrnic uvnitř souboru
.
.
.
.
.
V souboru můžeme také někdy najít znak #. Umožňuje přidat uvnitř souboru komentáře, které robot Google nebude číst. Když do řádku vložíte znak #, žádný znak následující za tímto znakem ve stejném řádku nebude společností Google přečten.
disallow: /search/ #žádný ze znaků následujících za "fence" nebude robotem Google přečten
.
Jak vytvořit soubor robots.txt
.
V tuto chvíli jsme připraveni vytvořit takový soubor sami. K tomu budeme potřebovat libovolný textový editor: MS Word, Poznámkový blok atd. V editoru vytvoříme prázdný textový dokument a nazveme jej prostě robots.txt.
Dalším krokem je doplnění textového dokumentu správnými direktivami. Před jejich zadáním bychom se měli připravit:
- seznam robotů, kterých se omezení mají týkat,
- seznam robotů, kterých se omezení týkat nebudou,
- seznam webů, ke kterým chceme blokovat přístup,
- seznam stránek, jejichž přístup nemůžeme blokovat,
- adresa URL mapy stránek,
.
.
.
.
.
Máme-li výše uvedené údaje, můžeme začít ručně psát pravidla jedno pod druhé do vytvořeného textového dokumentu. Příklad souboru robots.txt:
Uživatelský agent: * disallow: /business-card # zablokuje přístup ke stránkám ve složce business-card. disallow: /*pdf$ #blokuje přístup k souborům s příponou .pdf disallow: sortby= #blokuje přístup k souborům, které mají v url třídění. User-agent: ownbotsc1 allow: * sitemap: <https://www.domena.pl/sitemap_product.xml> #odkaz na xml sitemap sitemap: <https://www.domena.pl/sitemap_category.xml> sitemap: <https://www.domena.pl/sitemap_static.xml> sitemap: <https://www.domena.pl/sitemap_blog.xml>
.
Takto vytvořený dokument musíme umístit do kořenové složky naší domény na serveru FTP, kde jsou umístěny jeho soubory. Stojí za zmínku, že v systémech pro správu obsahu, jako je například WordPress, najdeme pluginy, které nám umožní upravovat soubor robots.txt umístěný na serveru FTP.
Jak otestovat, zda jsou pokyny v souboru robots.txt správné?
.
Abychom mohli důkladně otestovat, zda námi vytvořený soubor robots.txt bude fungovat správně, musíme navštívit: https://www.google.com/webmasters/tools/robots-testing-tool.
Zde nalezneme tester, který stáhne soubor robot.txt, který se aktuálně nachází na doméně (musíme být jejím ověřeným vlastníkem v Google Search Console), a poté nám umožní jej upravit a zkontrolovat, zda námi uvedené podstránky budou blokovány nebo projdou podle směrnic v něm uvedených.
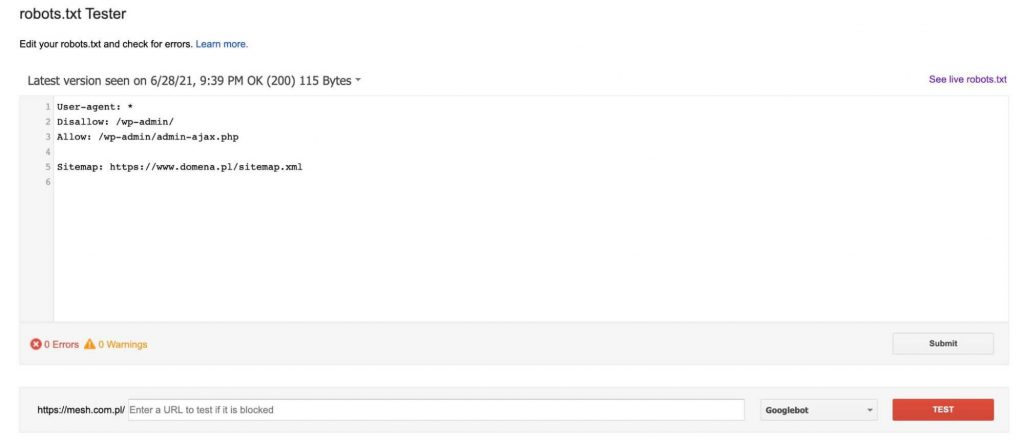
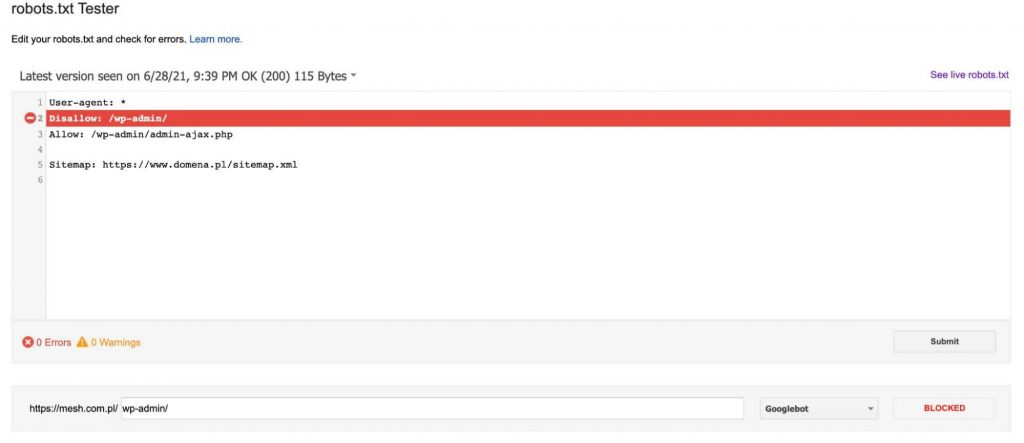
Vždy po přidání adresy URL do testu (v dolní části grafiky) klikneme na červené tlačítko „TEST“ a v odpovědi dostaneme informaci, zda byla uvedená adresa URL zablokována, a pokud ano, který řádek textu v souboru robots.txt naši adresu URL zablokoval.
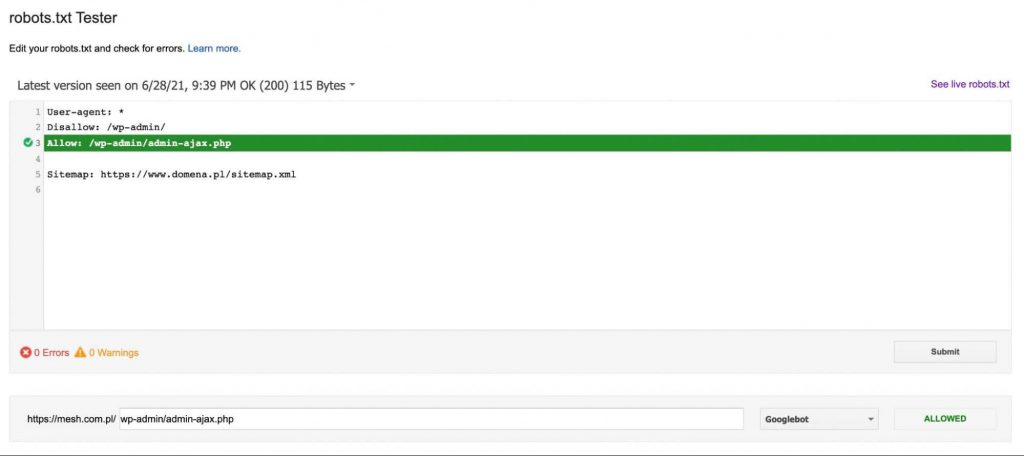
Pokud adresa URL není blokována, zobrazí se zpráva, která zpřístupní adresu URL směrnice robotovi Google – jako na obrázku níže:
Na co si dát pozor při vytváření souboru robots.txt?
.
Při vytváření souboru robots.txt bychom měli dbát zejména na to, abychom robotovi Google zcela nebo částečně zablokovali přístup na web. Všechny změny v tomto souboru je proto třeba konzultovat s odborníkem, abyste svému webu ještě více neuškodili.
Stojí však za zmínku, že soubor robots.txt neblokuje roboty při indexování webu. Google připouští možnost, že pokud se jeho robot dostal na některou z našich podstránek z jiné domény, pak pokud je tato stránka považována za hodnotnou, půjde do indexu.
Další důležitou poznámkou je, že většina robotů, kteří nejsou členy Googlu, se pokyny v souboru robots.txt neřídí a příkazy v něm uvedené ignoruje.
Souhrn
.
Soubor robots.txt je rozhodně důležitým prvkem technického SEO. Jeho špatné vyplnění hrozí omezením návštěvnosti ze SEO, zatímco jeho dobré vyplnění pomůže spravovat indexaci webu a rozpočet na procházení. Čím vyšší je návštěvnost webu, čím více podstránek na našem webu existuje, tím lépe je třeba dbát na správné vyplnění robots.txt.
.