 Łukasz Rogala
Łukasz Rogala Analýza rozpočtu procházení patří mezi pracovní povinnosti každého odborníka na SEO (zejména pokud se zabývá velkými webovými stránkami). Důležitý úkol, který je slušně popsán v materiálech poskytovaných společností Google. Přesto, jak se můžete přesvědčit na Twitteru, i zaměstnanci společnosti Google bagatelizují roli crawl budgetu při získávání lepší návštěvnosti a pozic:
Mají v tomhle pravdu?
Nejdůležitější body
- Rozpočet na procházení určuje, jak často a kolik stránek mohou vyhledávače indexovat na vašem webu.
- Faktory ovlivňující rozpočet na procházení zahrnují výkon serveru, kódy odezvy serveru a duplicitní obsah.
- Pro analýzu rozpočtu na procházení jsou užitečné nástroje jako Google Search Console, externí crawlery typu Screaming Frog SEO Spider a nástroje pro analýzu logů serveru.
- Znaky problému s rozpočtem na procházení zahrnují dlouhou dobu od zveřejnění do indexace nových stránek a dlouhodobé uchovávání neplatných adres URL v indexu.
- Optimalizace rozpočtu na procházení zahrnuje odstranění chyb 404/410, opravu interních přesměrování a zlepšení výkonnosti webových stránek. Více informací naleznete v Visibility Analysis od Senuto.
Jak funguje Google a jak sbírá data?“
Když už jsme nakousli toto téma, připomeňme si, jak vyhledávač shromažďuje, indexuje a organizuje informace. Udržet si tyto tři kroky v koutku mysli je při pozdější práci na webu nezbytné:
Krok 1: Procházení. Prohledávání online zdrojů s cílem objevit – a procházet napříč – všechny existující odkazy, soubory a data. Obecně Google začíná s nejpopulárnějšími místy na webu a poté pokračuje v prohledávání dalších, méně trendových zdrojů.
Krok 2: Indexování. Google se snaží určit, o čem stránka je a zda analyzovaný obsah/dokument představuje jedinečný nebo duplicitní materiál. V této fázi Google seskupuje obsah a stanovuje pořadí důležitosti (čtením návrhů v rel=“canonical“ nebo rel=“alternate“ značkách nebo jinak).
Krok 3: Servírování. Po segmentaci a indexaci se data zobrazí jako odpověď na dotazy uživatelů. V této fázi také Google data vhodně roztřídí, přičemž zohlední faktory, jako je například poloha uživatele.
Důležité: mnoho dostupných materiálů opomíjí krok 4: vykreslování obsahu. Ve výchozím nastavení indexuje Googlebot textový obsah. S dalším vývojem webových technologií však musel Google vymyslet nová řešení, aby přestal pouze „číst“ a začal také „vidět“. Právě o tom je vykreslování. Slouží společnosti Google k podstatnému zlepšení dosahu mezi nově spuštěnými weby a k rozšíření indexu.
Poznámka: Problémy s vykreslováním obsahu mohou být příčinou neúspěšného rozpočtu na procházení.
Vyzkoušejte Senuto Suite na 14 dní zdarma
Pojďme na to!Co je to rozpočet na procházení?“
Crawl budget není nic jiného než frekvence, s jakou mohou crawlery a boti vyhledávačů indexovat vaše webové stránky, a také celkový počet adres URL, ke kterým mohou přistupovat během jednoho procházení. Představte si rozpočet na procházení jako kredity, které můžete utratit za službu nebo aplikaci. Pokud nezapomenete „nabít“ rozpočet na procházení, robot zpomalí a bude vám věnovat méně návštěv.
V SEO se „nabíjení“ vztahuje k práci vynaložené na získání zpětných odkazů nebo zlepšení celkové popularity webu. Z toho vyplývá, že rozpočet na procházení je nedílnou součástí celého ekosystému webu. Když odvádíte dobrou práci na obsahu a zpětných odkazech, zvyšujete limit dostupného rozpočtu na procházení.
Společnost Google se ve svých zdrojích neodvažuje rozpočet na procházení výslovně definovat. Místo toho poukazuje na dvě základní složky procházení, které ovlivňují důkladnost Googlebotu a četnost jeho návštěv:
- .
- limit rychlosti procházení;
- poptávka po procházení.
Co je to limit rychlosti procházení a jak ho kontrolovat?“
Nejjednodušeji řečeno, limit rychlosti procházení je počet současných spojení, která může robot Google navázat při procházení vašeho webu. Protože společnost Google nechce poškodit uživatelský komfort, omezuje počet spojení, aby zachovala plynulý výkon vašeho webu/serveru. Stručně řečeno, čím pomalejší je váš web, tím menší je limit rychlosti procházení.
Důležité: Limit procházení závisí také na celkovém stavu SEO vašeho webu – pokud váš web vyvolává mnoho přesměrování, chyb 404/410 nebo pokud server často vrací stavový kód 500, počet připojení se také sníží.
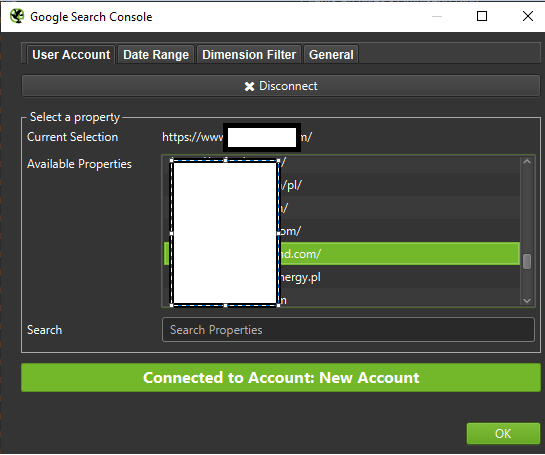
Údaje o limitu počtu procházení můžete analyzovat pomocí informací dostupných v konzole Google Search Console v sestavě Crawl Stats.
Poptávka po procházení nebo popularita webových stránek
Zatímco omezení rychlosti procházení vyžaduje, abyste vypilovali technické detaily svého webu, crawl demand vás odmění za popularitu webu. Zhruba řečeno, čím větší je kolem vašeho webu (a na něm) rozruch, tím větší je jeho crawl demand.
V tomto případě Google zohledňuje dvě záležitosti:
- Celkovou popularitu – Google je ochotnější provádět časté prohledávání adres URL, které jsou na internetu obecně populární (ne nutně těch, na které vedou zpětné odkazy z největšího počtu adres URL).
- Čerstvost dat v indexu – Google se snaží prezentovat pouze nejnovější informace. Důležité: Vytváření stále nového obsahu neznamená, že se zvyšuje celkový limit rozpočtu na procházení.
Faktory ovlivňující rozpočet na procházení
V předchozí části jsme definovali rozpočet na procházení jako kombinaci limitu rychlosti procházení a poptávky po procházení. Mějte na paměti, že pro zajištění správného procházení (a tedy indexování) webu je třeba dbát na obojí současně.
Níže najdete jednoduchý seznam bodů, které je třeba při optimalizaci rozpočtu na procházení zohlednit
- Server – hlavní otázkou je výkon. Čím nižší je rychlost, tím vyšší je riziko, že Google přidělí méně prostředků na indexování nového obsahu.
- Kódy odezvy serveru – čím větší je počet přesměrování 301 a chyb 404/410 na vašem webu, tím horších výsledků indexace dosáhnete. Důležité: Dávejte si pozor na smyčky přesměrování – každý „skok“ snižuje limit rychlosti procházení vašeho webu pro další návštěvu bota.
- Bloky v souboru robots.txt – pokud vycházíte ze směrnic robots.txt na základě instinktu, můžete nakonec vytvořit úzká místa indexace. Výsledek: vyčistíte index, ale na úkor efektivity indexování nových stránek (když byly blokované adresy URL pevně zakotveny ve struktuře celého webu).
- Odstraněná navigace / identifikátory relací / jakékoli parametry v adresách URL – především si dejte pozor na situace, kdy adresa s jedním parametrem může být dále parametrizována, aniž by bylo zavedeno nějaké omezení. Pokud by k tomu mělo dojít, Google dosáhne nekonečného počtu adres a všechny dostupné zdroje vynaloží na méně významné části našich webových stránek.
- Duplicitní obsah – kopírovaný obsah (kromě kanibalizace) výrazně poškozuje efektivitu indexování nového obsahu.
- Tenký obsah – k tomu dochází, když má stránka velmi nízký poměr textu k HTML. V důsledku toho může Google stránku identifikovat jako tzv. měkkou 404 a omezit indexaci jejího obsahu (i když je obsah smysluplný, což může být například případ stránky výrobce prezentující jediný produkt a žádný unikátní textový obsah).
- Špatné vnitřní propojení nebo jeho absence.
Užitečné nástroje pro analýzu rozpočtu procházení
Vzhledem k tomu, že neexistuje žádné měřítko pro rozpočet na procházení (což znamená, že je obtížné porovnávat limity mezi weby), vybavte se sadou nástrojů určených k usnadnění sběru a analýzy dat.
Google Search Console
GSC se v průběhu let pěkně rozrostla. Během analýzy rozpočtu procházení existují dvě hlavní sestavy, na které bychom se měli zaměřit: Pokrytí indexu a Statistiky procházení.
Pokrytí indexů v GSC
Tato sestava je obrovským zdrojem dat. Podívejme se na informace o adresách URL vyloučených z indexování. Je to skvělý způsob, jak pochopit rozsah problému, kterému čelíte.
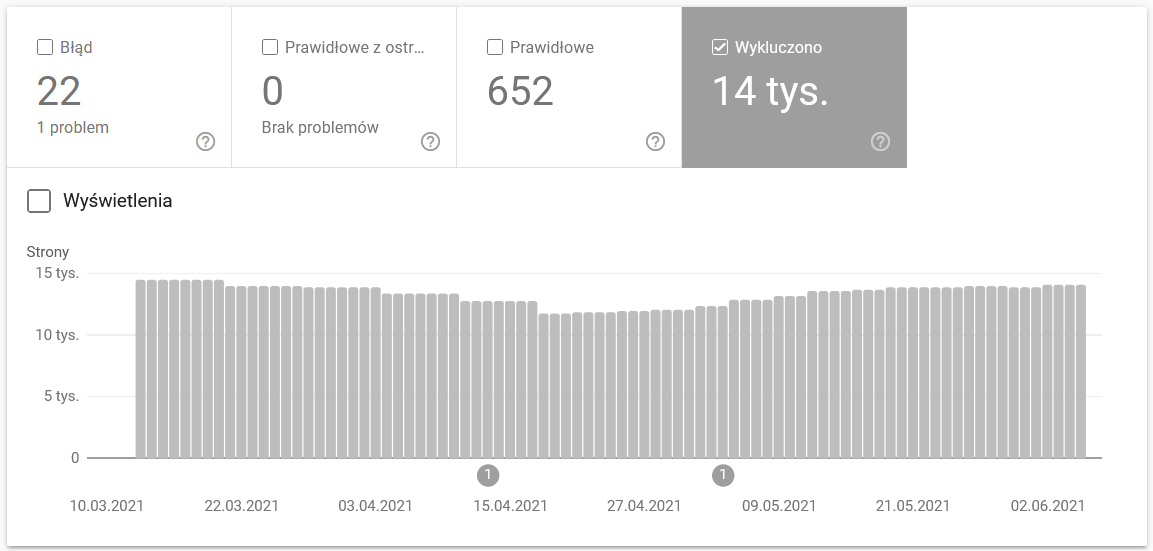
Celé zprávy si zaslouží samostatný článek, proto se prozatím zaměřme na následující informace:
-
- Vyloučeno pomocí tagu ‚noindex‘ – Obecně platí, že více noindexovaných stránek znamená nižší návštěvnost. Což vyvolává otázku – jaký má smysl je na webu udržovat? Jak omezit přístup k těmto stránkám?“
.
- Prohledáno – aktuálně neindexováno – pokud to vidíte, zkontrolujte, zda se obsah v očích Googlebota vykresluje správně. Nezapomeňte, že každá adresa URL s tímto stavem plýtvá vaším rozpočtem na procházení, protože negeneruje organický provoz.
- Odhaleno – aktuálně neindexováno – jeden z alarmujících problémů, který stojí za to zařadit na první místo v seznamu priorit.
- Duplicitní bez uživatelsky zvoleného kanonického textu – všechny duplicitní stránky jsou velmi nebezpečné, protože nejenže poškozují váš rozpočet na procházení, ale také zvyšují riziko kanibalizace.
- Duplikát, Google zvolil jiný kanonický kód než uživatel – teoreticky se není třeba obávat. Google by přece měl být dostatečně chytrý na to, aby učinil správné rozhodnutí místo nás. No, ve skutečnosti Google vybírá své kanonické kódy zcela náhodně – často odřízne cenné stránky s kanonickým kódem směřujícím na domovskou stránku.
- Měkká 404 – všechny „měkké“ chyby jsou velmi nebezpečné, protože mohou vést k odstranění kritických stránek z indexu.
- Duplicitní, odeslaná adresa URL nebyla vybrána jako kanonická – podobně jako stav hlášení o nedostatku kanonických adres vybraných uživatelem.
Statistika procházení
Report není dokonalý a co se týče doporučení, rozhodně doporučuji pohrát si také se starými dobrými logy serveru, které poskytují hlubší vhled do dat (a více možností modelování).
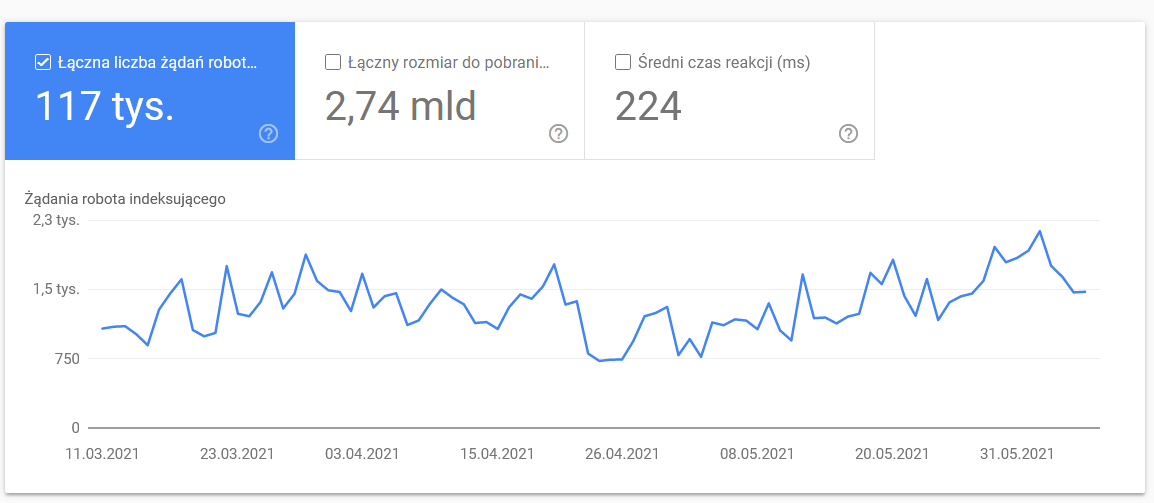
Jak jsem již řekl, pro výše uvedené údaje budete jen těžko hledat srovnávací testy. Nicméně je dobré se na ně podívat blíže:
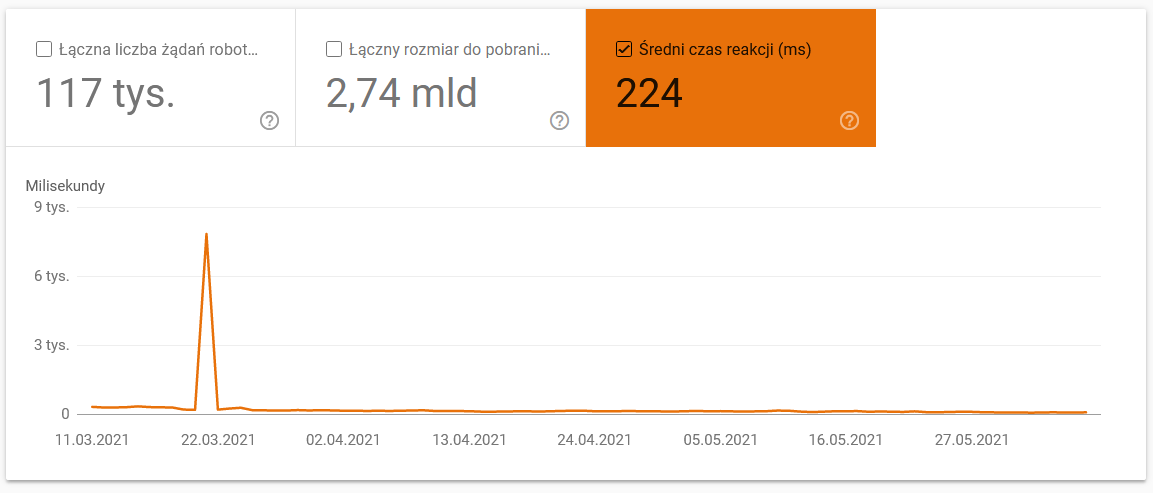
- Průměrná doba stahování. Níže uvedený snímek obrazovky ukazuje, že průměrná doba odezvy dostala dramatický zásah, který byl způsoben problémy souvisejícími se serverem:
- Odpovědi na dotaz Crawl. Podívejte se na zprávu a obecně zjistěte, zda máte s webem problém, nebo ne. Věnujte velkou pozornost atypickým stavovým kódům serveru, jako je například níže uvedený kód 304. Tyto adresy URL neslouží k žádnému funkčnímu účelu, přesto Google plýtvá svými zdroji na procházení jejich obsahu.

- Účel procházení. Obecně tyto údaje do značné míry závisí na objemu nového obsahu na webu. Rozdíly mezi informacemi shromážděnými společností Google a uživatelem mohou být docela fascinující:
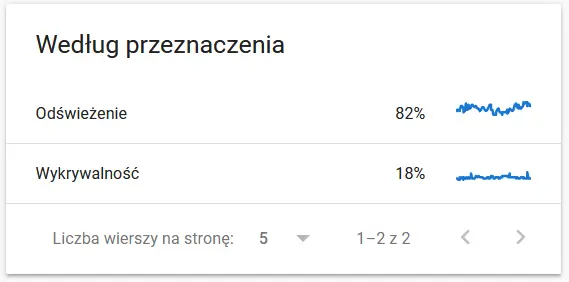
Obsah znovu procházené adresy URL z pohledu společnosti Google:
Mezitím zde vidí uživatel v prohlížeči:
Rozhodně důvod k zamyšlení a analýze : )
- Typ Googlebot. Zde máte na stříbrném podnose boty, kteří navštěvují vaše webové stránky, spolu s jejich motivací pro rozbor vašeho obsahu. Snímek obrazovky níže ukazuje, že 22 % požadavků se týká načítání zdrojů stránky.
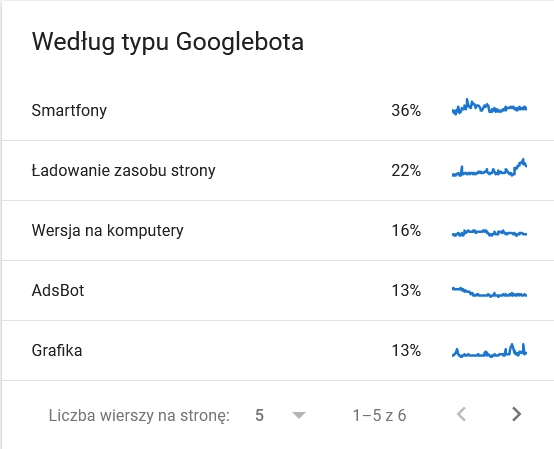
V posledních dnech časového rámce celkový počet balancoval na hraně:
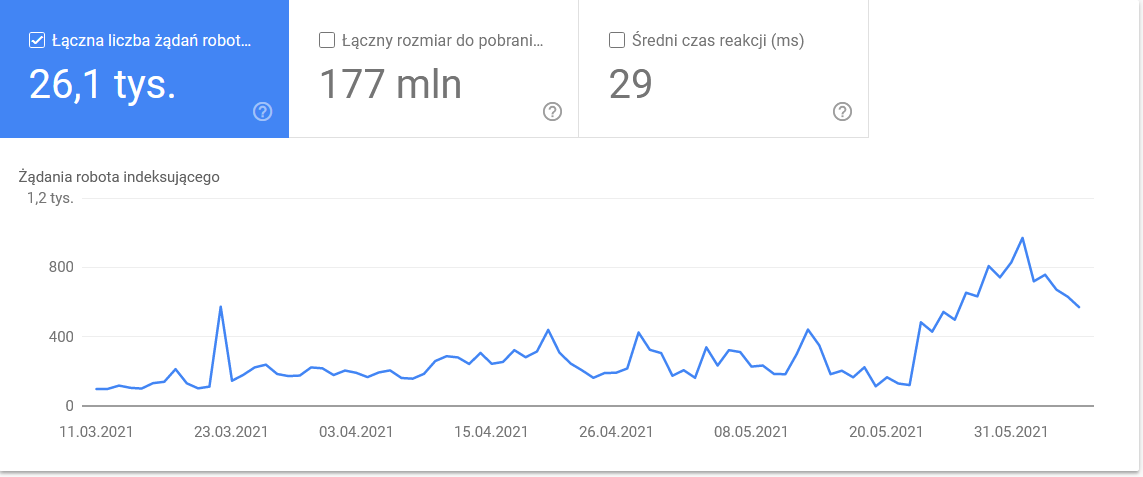
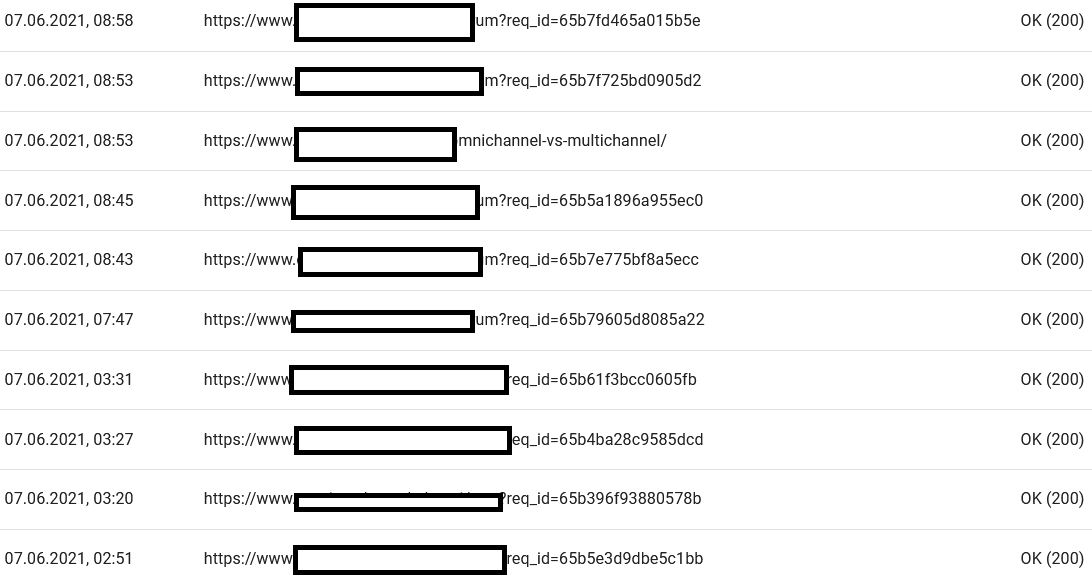
Pohled na podrobnosti odhalí adresy URL, které vyžadují větší pozornost:
Externí crawlery (s příklady ze Screaming Frog SEO Spider)
Crawlery patří mezi nejdůležitější nástroje pro analýzu rozpočtu na procházení webu. Jejich hlavním účelem je napodobovat pohyby prolézacích robotů na webových stránkách. Simulace vám na první pohled ukáže, zda vše probíhá hladce.
.
Pokud patříte mezi vizuální studenty, měli byste vědět, že většina řešení dostupných na trhu nabízí vizualizace dat.
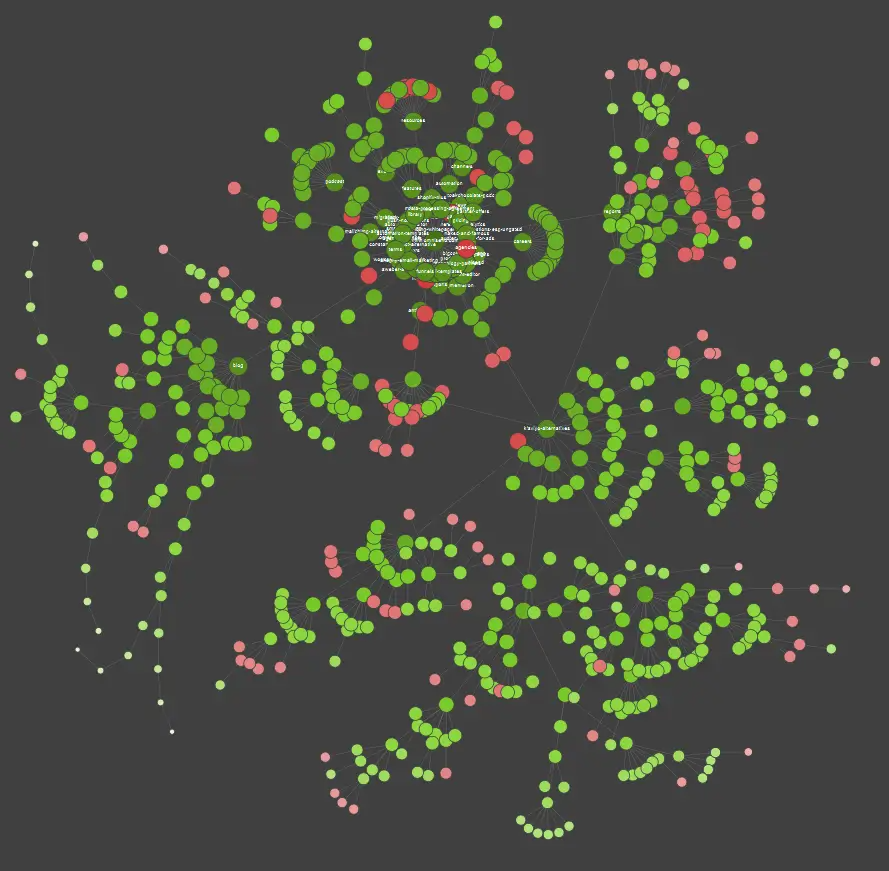
Ve výše uvedeném příkladu červené tečky označují neindexované stránky. Chvíli zvažte jejich užitečnost a dopad na fungování webu. Pokud protokoly serveru odhalí, že tyto stránky plýtvají spoustou času společnosti Google a zároveň nepřinášejí žádnou přidanou hodnotu – je čas vážně přehodnotit smysl jejich ponechání na webu.
Důležité: Pokud chceme co nejpřesněji napodobit chování Googlebota, je správné nastavení nezbytností. Zde si můžete prohlédnout ukázková nastavení z mého počítače:
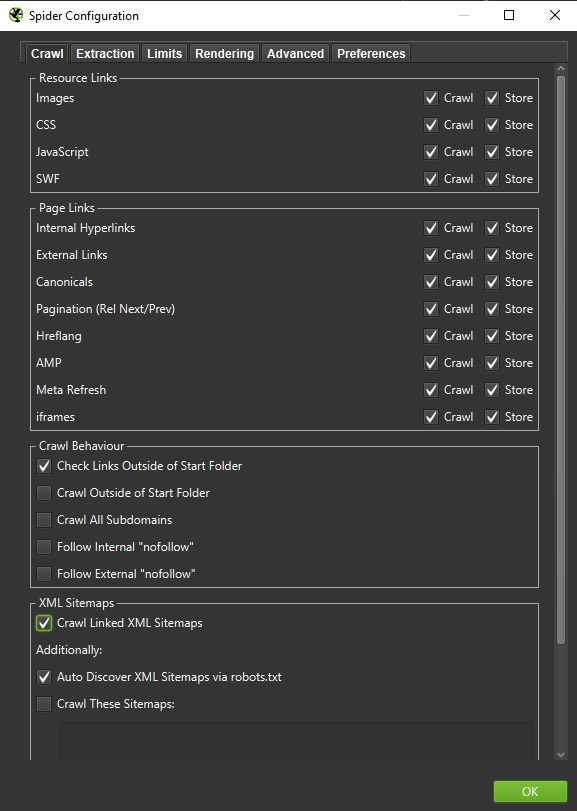
Při provádění hloubkové analýzy je vhodné vyzkoušet dva režimy – pouze text, ale také JavaScript – a porovnat rozdíly (pokud nějaké jsou).
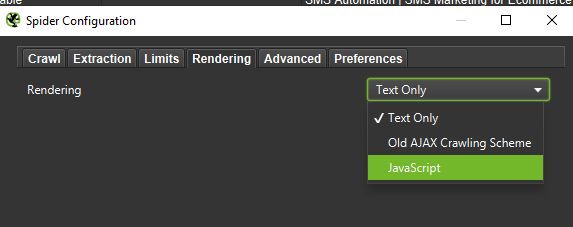
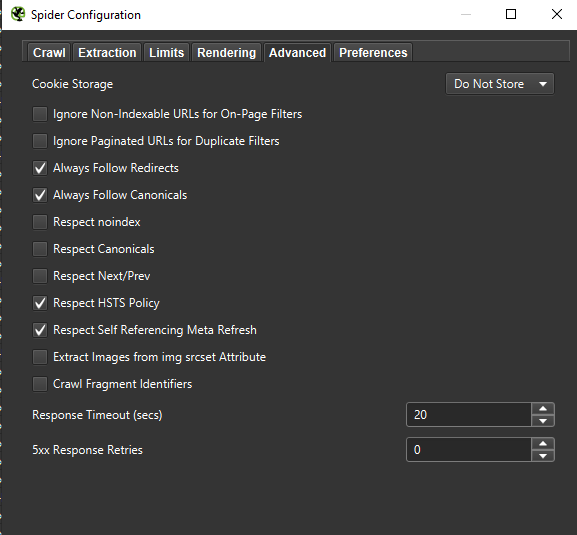
Nakonec nikdy neuškodí otestovat výše uvedené nastavení na dvou různých uživatelských agentech:
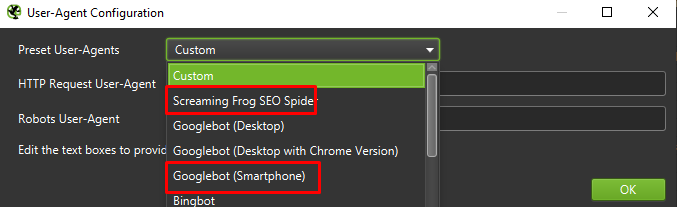
Ve většině případů se budete muset zaměřit pouze na výsledky procházené / vykreslené mobilním agentem.
Důležité: Doporučuji také využít možnosti, kterou poskytuje Screaming Frog, a zásobovat crawler daty z GA a Google Search Console. Tato integrace představuje rychlý způsob, jak identifikovat plýtvání rozpočtem na crawlování, například značný počet potenciálně nadbytečných adres URL, které nemají žádnou návštěvnost.
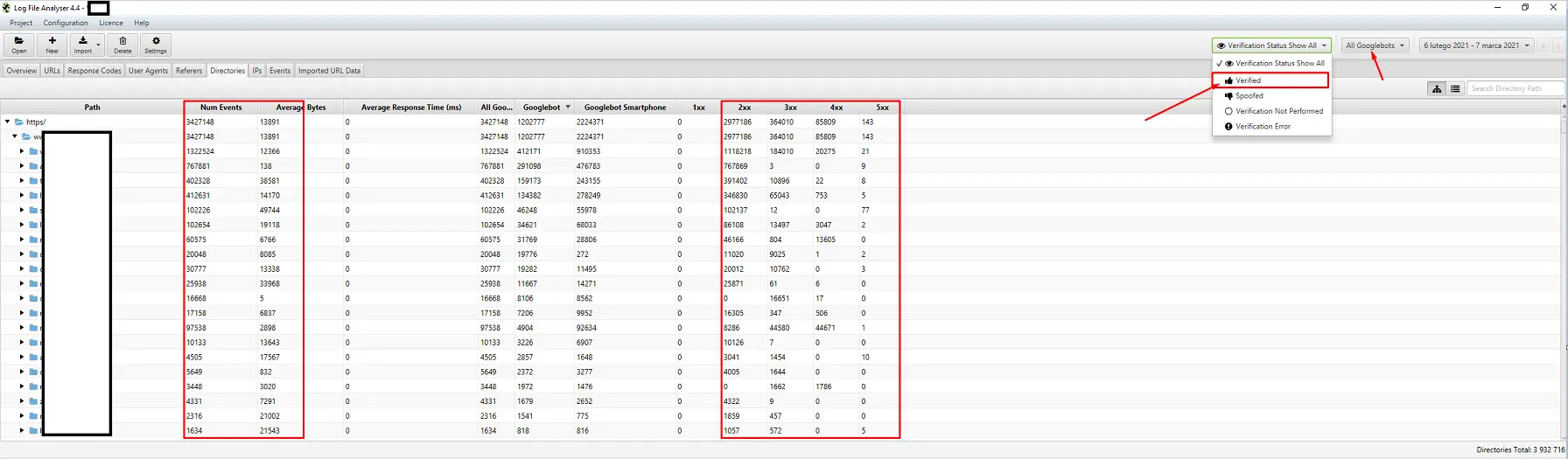
Nástroje pro analýzu logů (Screaming Frog Logfile a další)
Výběr analyzátoru serverových protokolů je otázkou osobních preferencí. Můj oblíbený nástroj je Screaming Frog Log File Analyzer. Možná to není nejefektivnější řešení (načítání obrovského balíku protokolů = zavěšení aplikace), ale líbí se mi jeho rozhraní. Důležité je přikázat systému, aby zobrazoval pouze ověřené roboty Google.
Nástroje pro sledování viditelnosti
Užitečná pomůcka, protože vám umožní identifikovat vaše nejnavštěvovanější stránky. Pokud se nějaká stránka umisťuje v Googlu vysoko na mnoho klíčových slov (= má velkou návštěvnost), může mít potenciálně větší nároky na procházení (zkontrolujte si to v protokolech – opravdu Google generuje pro tuto konkrétní stránku více návštěv?)
Pro naše účely budeme v budoucnu potřebovat obecné přehledy v aplikaci Senuto – Cesty a adresy URL – pro další kontrolu. Obě sestavy jsou k dispozici v Analýze viditelnosti, na kartě Sekce. Podívejte se na ně:
.
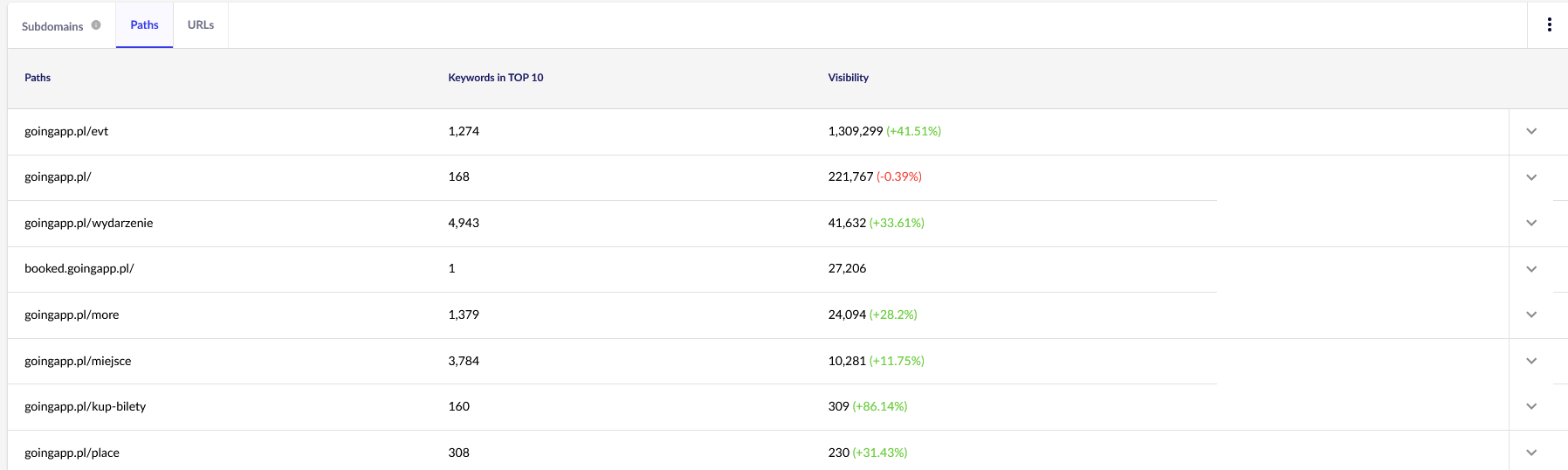
Naším hlavním bodem zájmu je druhá zpráva. Seřaďme si ji a podívejme se na viditelnost našich klíčových slov (seznam a celkový počet klíčových slov, na která se naše webové stránky řadí do TOP 10). Výsledky nám poslouží k určení hlavní osy pro stimulaci (a efektivní alokaci) našeho rozpočtu na procházení.
Nástroje pro analýzu zpětných odkazů (Ahrefs, Majestic)
Pokud má některá z vašich stránek vysoké množství příchozích odkazů, použijte ji jako pilíř strategie optimalizace rozpočtu na procházení. Oblíbené stránky mohou převzít roli rozbočovačů, které přenášejí šťávu dále. Populární stránka se slušným fondem cenných odkazů má navíc větší šanci přilákat časté procházení.
V Ahrefs potřebujeme sestavu Stránky, přesněji řečeno její část s názvem: „Nejlepší podle odkazů“:
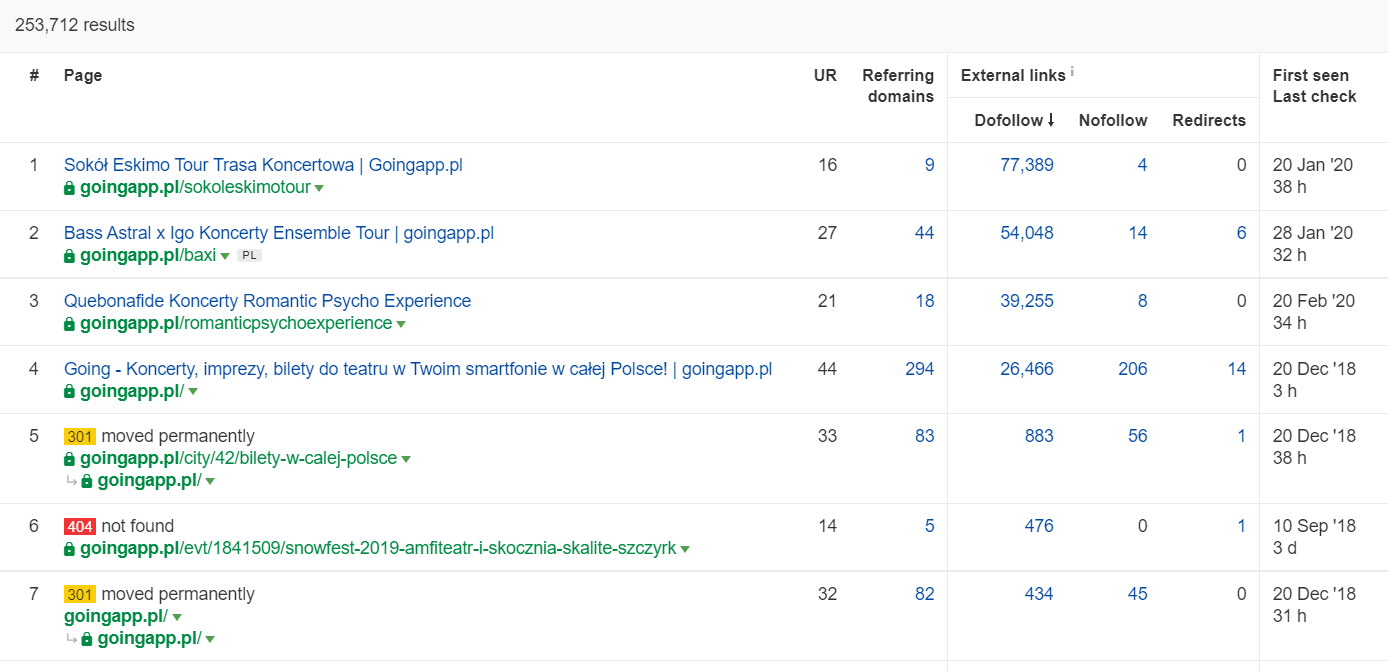
Výše uvedený příklad ukazuje, že některé LP související s koncerty nadále generovaly solidní statistiky zpětných odkazů. I když byly všechny koncerty kvůli pandemii zrušeny, stále se vyplatí používat historicky silné stránky, které vzbudí zvědavost prolézacích robotů a rozšíří šťávu do hlubších koutů vašeho webu.
Jaké jsou vypovídající znaky problému rozpočtu procházení?“
Zjištění, že se potýkáte s problematickým (příliš nízkým) rozpočtem crawlování, nepřichází snadno. Proč? Především proto, že SEO je nesmírně složitý podnik. Nízké pozice nebo problémy s indexací mohou být stejně dobře důsledkem průměrného odkazového profilu nebo nedostatku správného obsahu na webu.
Diagnostika rozpočtu na procházení obvykle zahrnuje kontrolu:
- .
- Kolik času uplyne od zveřejnění do indexace nových stránek (příspěvků na blogu / produktů) za předpokladu, že nepožadujete indexaci prostřednictvím služby Google Search Console?
- Jak dlouho Google uchovává neplatné adresy URL v indexu? Důležité: přesměrované adresy jsou výjimkou – Google je ukládá záměrně.
- Máte stránky, které se dostanou do indexu, aby z něj později vypadly?
- Kolik času tráví Google na stránkách, které negenerují hodnotu (návštěvnost)? Přejděte na analýzu protokolů a zjistěte to.
Jak analyzovat a optimalizovat rozpočet procházení?
Rozhodnutí vrhnout se do optimalizace crawl budgetu je dáno především velikostí vašeho webu. Společnost Google obecně naznačuje, že weby s méně než 1000 stránkami by se neměly trápit tím, jak maximálně využít dostupné limity procházení. Podle mého názoru byste měli začít bojovat o efektivnější a účinnější procházení, pokud váš web obsahuje více než 300 stránek a váš obsah se dynamicky mění (například stále přidáváte nové stránky/příspěvky na blog).
Proč? Je to otázka hygieny SEO. Zavedete-li správné optimalizační návyky a rozumnou správu rozpočtu na procházení v počátcích, budete mít v budoucnu méně práce s nápravou a předěláváním.
Optimalizace rozpočtu procházení. Standardní postup
Obecně se práce na analýze a optimalizaci rozpočtu craw skládá ze tří fází:
- .
- Sběr dat, což je proces shromažďování všeho, co o webu víme – od správců webu i externích nástrojů.
- Analýza viditelnosti a identifikace nízko visících plodů. Co běží jako po másle? Co by mohlo být lepší? Které oblasti mají největší potenciál k růstu?
- Doporučení pro plíživý rozpočet.
Sběr dat pro audit crawl rozpočtu
1. Úplné procházení webových stránek provedené pomocí některého z komerčně dostupných nástrojů. Cílem je provést minimálně dvě procházení: první simuluje Googlebot, zatímco druhé načte web jako výchozí uživatelský agent (postačí uživatelský agent prohlížeče). V této fázi vás zajímá pouze stažení 100 % obsahu. Pokud si všimnete, že se crawler dostal do smyčky (když po dni procházení máme na pevném disku stále jen 10 % webu) – dejte najevo, že je problém, a můžete procházení zastavit. Rozumný počet adres URL pro analýzu se v případě velkých webových stránek pohybuje kolem 250-300 tisíc stránek.
a) Hledáme především interní přesměrování 301, chyby 404, ale také situace, kdy vaše texty mohou být zařazeny do kategorie tenkého obsahu. Screaming Frog má možnost odhalit téměř duplicitní obsah:
2. Protokoly serveru. Ideální časový rámec by měl zahrnovat poslední měsíc, v případě velkých webových stránek však mohou stačit dva poslední týdny. V nejlepším případě bychom měli mít přístup k historickým záznamům serveru, abychom mohli porovnat pohyby Googlebota v době, kdy vše probíhalo hladce.
3. Export dat z konzoly Google Search Console. V kombinaci s výše uvedenými body 1 a 2 by vám data z Index Coverage a Crawl Stats měla poskytnout poměrně komplexní přehled o veškerém dění na vašem webu.
4. Údaje o organické návštěvnosti. Nejnavštěvovanější stránky podle údajů z Google Search Console, Google Analytics a také Senuto a Ahrefs. Chceme identifikovat všechny stránky, které vynikají mezi ostatními svými statistikami vysoké viditelnosti, objemu návštěvnosti nebo počtu zpětných odkazů. Tyto stránky by se měly stát páteří vaší práce na rozpočtu procházení. Využijeme je ke zlepšení procházení nejdůležitějších stránek.
5. Ruční kontrola indexu. V některých případech je nejlepším přítelem odborníka na SEO jednoduché řešení. V tomto případě: revize dat převzatých přímo z indexu! Je dobré vyzvat ke kontrole webu pomocí kombinace operátorů inurl: + site:. .
Nakonec musíme všechna získaná data sloučit. Obvykle použijeme externí crawler s funkcemi umožňujícími import externích dat (data GSC, logy serverů a data o organické návštěvnosti).
Analýza viditelnosti a nízko visící ovoce
Tento proces si zaslouží samostatný článek, ale naším dnešním cílem je získat pohled na naše cíle pro webové stránky a dosažený pokrok z ptačí perspektivy. Zajímá nás vše, co se vymyká běžným zvyklostem: náhlé poklesy návštěvnosti (které nelze vysvětlit sezónními trendy) a souběžné posuny v organické viditelnosti. Zjišťujeme, které skupiny stránek jsou nejsilnější, protože ty se stanou našimi HUBY pro zatlačení Googlebota hlouběji do našeho webu.
V dokonalém světě by taková kontrola měla pokrýt celou historii našeho webu od jeho spuštění. Protože však objem dat každý měsíc stále roste, zaměřme se na analýzu viditelnosti a organické návštěvnosti za posledních 12 měsíců.
Rozpočet procházení – naše doporučení
Výše uvedené činnosti se budou lišit v závislosti na velikosti optimalizovaného webu. Jedná se však o nejdůležitější prvky, které vždy zohledňuji při provádění analýzy rozpočtu na crawlování. Předním cílem je odstranit úzká místa na vašem webu. Jinými slovy, zaručit maximální procházení pro roboty Google (nebo jiné indexovací agenty).
1. Začněme od základů – odstranění nejrůznějších chyb 404/410, analýza vnitřních přesměrování a jejich odstranění z vnitřního propojení. Naši práci bychom měli zakončit závěrečným procházením. Tentokrát by všechny odkazy měly vracet kód odpovědi 200, bez interních přesměrování a chyb 404.
- V této fázi je dobré opravit všechny řetězce přesměrování zjištěné v hlášení zpětných odkazů.
2. Po procházení se ujistěte, že struktura našich webových stránek neobsahuje do očí bijící duplicity.
- Zkontrolujte také, zda nedochází k případné kanibalizaci – kromě problémů vyplývajících z cílení na stejné klíčové slovo pomocí více stránek (zkrátka přestáváte mít kontrolu nad tím, kterou stránku Google zobrazí), kanibalizace negativně ovlivňuje celý váš rozpočet na procházení stránek.
- Zkonsolidujte identifikované duplicity do jediné adresy URL (obvykle té, která má vyšší pozici).
3. Zkontrolujte, kolik adres URL má značku noindex. Jak víme, Google může tyto stránky stále procházet. Jen se nezobrazují ve výsledcích vyhledávání. Snažíme se minimalizovat podíl značek noindex ve struktuře našich webových stránek.
- Příklad – blog organizuje svou strukturu pomocí značek; autoři tvrdí, že toto řešení je diktováno pohodlím uživatelů. Každý příspěvek je označen 3-5 značkami, které jsou přiřazeny nekonzistentně a nejsou indexovány. Analýza logů ukazuje, že je to třetí nejprocházenější struktura na webu.
4. Prověřte soubor robots.txt. Nezapomeňte, že implementace souboru robots.txt neznamená, že Google nebude adresu zobrazovat v indexu.
-
- .
- Zkontrolujte, které ze zablokovaných adresních struktur jsou stále procházeny. Možná jejich odříznutí způsobuje úzké hrdlo?“
.
- Odstraňte zastaralé/nepotřebné směrnice.
5. Analyzujte objem nekanonických adres URL na svém webu. Google přestal považovat rel=“canonical“ za tvrdou směrnici. V mnoha případech je tento atribut vyhledávačem vyloženě ignorován (parametry řazení v indexu – stále noční můra).
6. Analyzujte filtry a jejich základní mechanismus. Filtrování výpisů je největší bolestí hlavy při optimalizaci rozpočtu procházení. Majitelé e-shopů trvají na implementaci filtrů použitelných v libovolné kombinaci (například filtrování podle barvy + materiálu + velikosti + dostupnosti… do omrzení). Toto řešení není optimální a mělo by se omezit na minimum.
7. Architektura informací na webu – taková, která zohledňuje obchodní cíle, potenciál návštěvnosti a aktuální profil odkazů. Pracujme s předpokladem, že odkaz na obsah rozhodující pro naše obchodní cíle by měl být viditelný na celém webu (na všech stránkách) nebo na domovské stránce. Samozřejmě zde zjednodušujeme, ale domovská stránka a horní menu / odkazy na celém webu jsou nejsilnějšími ukazateli při budování hodnoty z interních odkazů. Současně se snažíme dosáhnout optimálního rozložení domény: naším cílem je situace, kdy můžeme začít procházení z libovolné stránky a přitom dosáhnout stejného počtu stránek (každá adresa URL by měla mít MINIMÁLNĚ jeden příchozí odkaz).
- Práce na robustní informační architektuře je jedním z klíčových prvků optimalizace rozpočtu na procházení. Umožňuje nám uvolnit část zdrojů bota z jednoho místa a přesměrovat je na jiné. Je to také jedna z největších výzev, protože vyžaduje spolupráci zainteresovaných obchodních subjektů – což často vede k velkým bitvám a kritice podkopávající doporučení SEO.
8. Vykreslování obsahu. Kritické v případě webových stránek, jejichž cílem je založit interní propojení na doporučovacích systémech zachycujících chování uživatelů. Především většina těchto nástrojů se spoléhá na soubory cookie. Společnost Google soubory cookie neukládá, takže nezískává přizpůsobené výsledky. Výsledek: Google vidí vždy stejný obsah nebo žádný obsah.
- Častou chybou je, že bráníte robotu Google v přístupu ke kritickému obsahu JS/CSS. Tento krok může vést k problémům s indexováním stránky (a plýtvání časem Googlu na vykreslování nedostupného obsahu).
9. Výkonnost webových stránek – Core Web Vitals. Ačkoli jsem skeptický ohledně vlivu CWV na hodnocení webu (z mnoha důvodů, včetně rozmanitosti komerčně dostupných zařízení a různé rychlosti internetového připojení), je to jeden z parametrů, který stojí za to s kodérem prodiskutovat.
10. Sitemap.xml – zkontrolujte, zda funguje a obsahuje všechny klíčové prvky (nic jiného než kanonické adresy URL vracející stavový kód 200).
- Mým prvním doporučením pro optimalizaci souboru sitemap.xml je rozdělit stránky podle typu nebo – pokud je to možné – podle kategorií. Toto rozdělení vám poskytne plnou kontrolu nad pohybem a indexací obsahu ze strany Googlu.